
本文章是 RAPIDS 生態系統介紹系列的第二篇。此系列探討了 RAPIDS 的各個層面,讓使用者可以解決 ETL(Extract、Transform、Load,擷取、轉換、載入)問題、建構機器學習和深度學習模型、探索各種圖表、處理地理空間、訊號,以及系統紀錄資料,或透過 BlazingSQL 使用 SQL 語言處理資料。
在過去十年內,資料科學領域的大幅成長,使資料科學家對於處理資料量之運算能力的需求穩定上升。大約在 15 至 20 年前,處理資料的常見選擇,僅限於例如 SQL Server、Teradata、PostGRE 或 MySQL 以 SAS 和 SQL 為基礎的解決方案、使用 R 如果仰賴統計方法或使用 Python 如果需要通用語言的多用途性,則必須犧牲一些統計功能。這些年來,推出了許多可以處理不斷擴大之資料流的解決方案,如 2006 年發布的 Hadoop,多年來已逐漸普及,之後 Apache Spark 取代Hadoop,成為以分散式方式處理資料的首選工具。
然而,使用 Spark 也帶來了新的挑戰,例如熟悉 PyData 生態系統中之 pandas 及其他工具的人,必須學習新的 API,而企業必須重新編寫程式碼基礎,才能在 Spark 的分散式環境中運作。Dask 可以彌補此差距,為既有的 PyData 物件,例如 pandas DataFrames 或 NumPy 陣列增加分散式支援,並能更容易地充分利用 CPU 或分散式叢集的能力,無須重寫大量程式碼。不過,以互動方式處理大量資料,已經超出 CPU 叢集合理的大小和價格範圍。
在 2018 年底,RAPIDS 改變了此局勢。RAPIDS 與 Dask 的搭配,可利用 NVIDIA GPU 的大規模平行性處理資料。但是不同於 Apache Spark,它未導入新的 API,而是提供 PyData 生態系統中的 pandas、scikit-learn、NetworkX 等工具的程式設計介面,令人感到非常熟悉。
第一篇文章是 python pandas 教學,介紹可以在 NVIDIA GPU 上處理大量資料的 RAPIDS CUDA DataFrame 函式庫:RAPIDS cuDF。
而本篇將會探討為何 cuDF 幾乎可以直接取代 pandas。我們同時提供了備忘單以輔助本教學,您可以在此處下載:cuDF4pandas-cheatsheet,以及包含 cuDF 和 pandas API 呼叫的互動式 notebook,如此處所示。
常見介面
如果您使用 Python 處理資料,則可能會一直使用 pandas 或 NumPy,因為 pandas 是以 NumPy 為基礎。這兩個函式庫為 PyData 生態系統帶來大到無法形容的價值。pandas 幾乎是所有資料操作和清理的必備工具,且出現在 GitHub、Kaggle、Towards Data Science 等平台上發布的無數 notebook 中。如果您正在尋找使用 Python 解決資料問題的解決方案,則可能會看到採用 pandas 的範例。
RAPIDS cuDF 幾乎完全複製相同的 API 和功能。雖然不是 100% 與 pandas 功能相等,但是 NVIDIA 團隊以及外部貢獻者都在不斷努力縮小相等功能的差距。
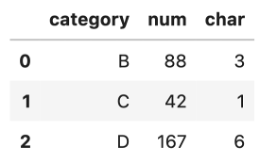
要在這兩個框架之間移動非常容易。以下是非常簡單的 pandas 指令碼,可以讀取資料、計算 DataFrame 的描述性統計,然後執行簡單的資料聚合。
# pandas
import pandas as pd
df = pd.read_csv('df.csv')
(
df
.groupby(by='category')
.agg({'num': 'sum', 'char': 'count'})
.reset_index()
)
讓我們看一看 df DataFrame 的內部。
df.head(10)
獲得的輸出如下:
聚合步驟將能準確地提供最終結果。
使用 RAPIDS,僅需要變更上述程式碼的匯入陳述式,即可在 GPU 上執行與享受互動式資料查詢。
# cudf
import cudf
df = cudf.read_csv('../results/pandas_df_with_index.csv')
(
df
.groupby(by='category')
.agg({'num': 'sum', 'char': 'count'})
.reset_index()
)
實際上,我們僅變更匯入,現在已能在 GPU 上執行!
在此類小型資料集上使用 pandas 執行,僅需要幾毫秒的時間,即可皆大歡喜。但處理具有 1 億筆紀錄的 DataFrame,效能如何呢?讓我們模擬更大的資料集。在此範例中,我們將使用 CuPy 稍微加快速度。
import cupy as cp choices = range(6) probs = cp.random.rand(6) s = sum(probs) probs = [e / s for e in probs] n = int(100e6) ## 100M selected = cp.random.choice(choices, n, p=probs) nums = cp.random.randint(10, 1000, n) chars = cp.random.randint(65,80, n)
上面代碼中等同於 NumPy 的是:
import numpy as np choices = range(6) probs = np.random.rand(6) s = sum(probs) probs = [e / s for e in probs] n = int(100e6) ## 100M selected = np.random.choice(choices, n, p=probs) nums = np.random.randint(10, 1000, n) chars = np.random.randint(65,80, n)
有看出差異了嗎?是的,僅差在匯入陳述式!在時間方面:CuPy 版本在 Titan RTX 上執行大約為 1.27 秒,而使用 NumPy 版本在 i5 CPU 上執行大約為 3.33 秒。
現在,我們可以使用 CuPy 或 NumPy 陣列,建立 cuDF 或 pandas DataFrames。
import cudf
df = cudf.DataFrame({
'category': selected
, 'num': nums
, 'char': chars
})
df['category'] = df['category'].astype('category')
以及
import pandas
df = pandas.DataFrame({
'category': selected
, 'num': nums
, 'char': chars
})
df['category'] = pandas_df['category'].astype('category')
可以忽略建立這些的時間,因為 cuDF 和 pandas 僅擷取指向已建立 CuPy 和 NumPy 陣列的指標。再次強調,截至目前為止,我們僅變更了匯入陳述式。
聚合程式碼與我們之前使用的相同,cuDF 與 pandas DataFrames 之間無任何改變。但是執行的時間卻大不相同:平均使用 68.9 ms ± 3.8 ms 完成 cuDF 程式碼,執行 7 次,每次各 10 個迴圈;而使用 pandas 程式碼平均使用 1.37s ± 1.25 ms,同樣執行 7 次,每次各 10 個迴圈。相當於加速大約 20 倍!且無須變更程式碼!
自訂核心
在某些情況下,當涉及轉換資料的自訂函式時,從 pandas 移動到 cuDF 需要小幅修改程式碼。
RAPIDS cuDF 是以 NVIDIA CUDA 為基礎的 GPU 函式庫,無法直接在 GPU 上執行正規 Python 程式碼。基本上 cuDF 是使用 Numba 轉換 Python 程式碼,並編譯成 CUDA 核心。覺得很複雜嗎?別擔心!使用 cuDF 執行自訂轉換函式,無須熟悉 CUDA。
以下是簡單的 pandas 範例,根據兩個特徵計算迴歸線。
# pandas def pandas_regression(a, b, A_coeff, B_coeff, constant): return A_coeff * a + B_coeff * b + constant
pandas_df['output'] = pandas_df.apply( lambda row: pandas_regression( row['num'] , row['float'] , A_coeff=0.21 , B_coeff=-2.82 , constant=3.43 ), axis=1)
非常簡單,想要使用 cuDF 達到相同的結果時,方式稍微不同,但是非常易讀及容易轉換。
# cudf
def cudf_regression(a, b, output, A_coeff, B_coeff, constant):
for i, (aa, bb) in enumerate(zip(a,b)):
output[i] = A_coeff * aa + B_coeff * bb + constant
cudf_df.apply_rows( cudf_regression , incols = {‘num’: ‘a’, ‘float’: ‘b’} , outcols = {‘output’: np.float64} , kwargs = {‘A_coeff’: 0.21, ‘B_coeff’: -2.82, ‘constant’: 3.43} )
Numba 會將 cudf_regression 函式編譯成 CUDA 核心。apply_rows 呼叫相當於 pandas 中的 apply 呼叫,而 axis 參數設為 1,即透過列進行迭代,而不是透過欄。請注意,在 cuDF 中必須指定輸出欄的資料類型,以使 Numba 可以提供正確的回傳類型簽章給 CUDA 核心。雖然具有這些差異,但是程式碼與 pandas 版本非常類似,主要差異在於 API 呼叫:計算迴歸線的方式幾乎相同。
return A_coeff * a + B_coeff * b + constant
與
output[i] = A_coeff * aa + B_coeff * bb + constant
如同這樣,即可在 GPU 上執行純 Python 程式碼。
如果想在 Strings、DateTimes 或類別欄使用運算時,請參考我們準備的 notebook,檢視可用的 pandas 與 cuDF API 呼叫,並下載 cuDF4pandas 備忘單!