
在 2022 年 NVIDIA GTC 主題演講中,NVIDIA CEO 黃仁勳介紹了以全新 NVIDIA Hopper GPU 架構為基礎的新型 NVIDIA H100 Tensor 核心 GPU。本文將帶領您一窺新型 H100 GPU,並介紹 NVIDIA Hopper 架構 GPU 的重要新功能。
簡介 NVIDIA H100 Tensor 核心 GPU
NVIDIA H100 Tensor 核心 GPU 是我們的第九代資料中心 GPU,是設計成為大規模人工智慧(AI)和高效能運算(HPC),提供超越上一代 NVIDIA A100 Tensor 核心 GPU 大幅的效能提升。H100 延續了 A100 的主要設計重點,以改善 AI 和 HPC 工作負載的強縮放,並大幅提高架構效率。

針對現今的主流 AI 和 HPC 模型,採用 InfiniBand 互連的 H100,提供高達 A100 之 30 倍的效能。新的 NVLink Switch System 互連可計算某些最大與最具挑戰性的工作負載,這些工作負載需要跨多個 GPU 加速節點的模型平行才能適配。這些工作負載再次獲得效能提升,在某些情況下,可以透過採用 InfiniBand 的 H100 再次將效能提高三倍。
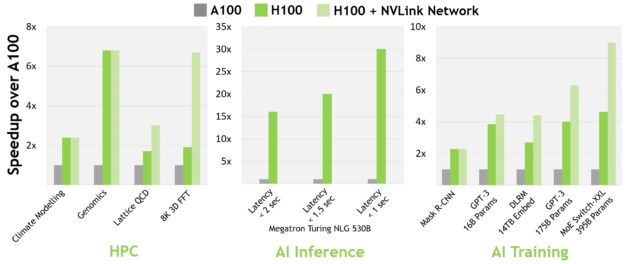
所有效能數據都是以目前之預期為根據的初步數據,產品在上市後可能會改變。A100 叢集:HDR IB 網路。H100 叢集:NDR IB 網路搭配 NVLink Switch System。# GPU:氣候建模 1K、LQCD 1K、基因體學 8、3D-FFT 256、MT-NLG 32 (批次大小:1 秒下 A100 為 4,H100 為 60、1.5-2 秒時 A100 為 8,H100 為 64)、MRCNN 8 (批次 32)、GPT-3 16B 512 (批次 256)、DLRM 128 (批次 64K)、GPT-3 16K (批次 512)、MoE 8K (批次 512,每一個 GPU 一位專家)。
在 2022 年春季 GTC 上,發表了新的 NVIDIA Grace Hopper Superchip 產品。NVIDIA Hopper H100 Tensor 核心 GPU 將可驅動專為 TB 級加速運算而打造,並在大型模型 AI 和 HPC 上提供 10 倍效能的 NVIDIA Grace Hopper Superchip CPU+GPU 架構。
NVIDIA Grace Hopper Superchip 利用 Arm 架構的靈活性,為加速運算創造從零開始設計的 CPU 和伺服器架構。H100 與採用超快速 NVIDIA 晶片之間互連的 NVIDIA Grace CPU 搭配,提供 900 GB/s 的總頻寬,較 PCIe Gen5 快 7 倍。此創新設計提供比現今最快之伺服器高 30 倍的總頻寬,並為使用數 TB 資料的應用程式提供高達 10 倍的效能。
NVIDIA H100 GPU 主要的特色摘要
- 新的串流多處理器(streaming multiprocessor,SM)改進了許多效能和效率。主要的新特色包括:
- 新的第四代 Tensor 核心之晶片間的速度比 A100 快 6 倍,包括每 SM 加速、SM 數量更多以及 H100 的時脈更高。在每一個 SM 基礎上,相較於上一代 16 位元浮點選項,Tensor 核心在相等資料類型上的矩陣相乘累加(Matrix Multiply-Accumulate,MMA)運算速率是 A100 SM 的 2 倍,使用新的 FP8 資料類型時為 A100 的 4 倍。稀疏性功能是利用深度學習網路中的細粒度結構化稀疏性,使標準 Tensor 核心運作的效能加倍。
- 新的 DPX 指令加快了動態規劃演算法,其速度提高至 A100 GPU 的 7 倍。兩個範例包括基因體學處理的 Smith-Waterman 演算法,以及尋找最佳路線,讓機器人在動態倉庫環境中行進的 Floyd-Warshall 演算法。
- IEEE FP64 和 FP32 晶片間之處理速率比 A100 快 3 倍,因為每一個 SM 的時脈對時脈效能加快了 2 倍,加上 SM 數量更多及 H100 的時脈更高。
- 新的執行緒區塊叢集功能可以使用單一 SM 上之單一執行緒區塊更大的粒度,進行局部性的程式控制。其為程式設計階層另外增加了一層,以延伸 CUDA 程式設計模型,現在包括執行緒、執行緒區塊、執行緒區塊叢集和網格。叢集讓多個執行緒區塊在多個 SM 上同時執行的,進而以同步及協作方式擷取和交換資料。
- 分散式共用記憶體允許 SM 對 SM 直接通訊,以跨多個 SM 共用記憶體區塊進行載入、儲存和原子操作。
- 新的非同步執行功能,包含新的 Tensor 記憶體加速器(Tensor Memory Accelerator,TMA)單元,可以在全域記憶體與共用記憶體之間有效率地傳輸大型資料區塊。TMA 同時可支援在叢集中的執行緒區塊之間進行非同步複製。還有一個新的非同步交易屏障,可以移動原子資料和進行同步。
- 新的 transformer 引擎結合了軟體,以及專為加快 transformer 模型訓練和推論而設計的自訂 NVIDIA Hopper Tensor 核心技術。transformer 引擎採用智慧化方式管理,並在 FP8 與 16 位元運算之間動態選擇,自動處理每一層 FP8 與 16 位元之間的重鑄和縮放,為大型語言模型提供比上一代 A100 快 9 倍的 AI 訓練加速以及快 30 倍的 AI 推論加速。
- HBM3 記憶體子系統提供的頻寬比上一代高將近 2 倍。H100 SXM5 GPU 是世界上第一款搭載 HBM3 記憶體的 GPU,可提供領先同級的每秒 3 TB 記憶體頻寬。
- 50 MB L2 快取架構可針對大部分模型和資料集進行快取,以供反覆存取,進而減少通往 HBM3 的行程。
- 相較於 A100 的第二代多執行個體 GPU(Multi-Instance GPU,MIG)技術,每一個 GPU 執行個體的運算容量增加了大約 3 倍,而記憶體頻寬增加了將近 2 倍。現在首次提供具有 MIG 級 TEE 的機密運算能力。最多可以支援七個個別 GPU 執行個體,且各具有專用的 NVDEC 和 NVJPG 單元。現在,每一個執行個體都包含各自的效能監視器,可以搭配 NVIDIA 開發人員工具使用。
- 新的機密運算支援可以保護使用者資料、防禦硬體和軟體攻擊,並在虛擬化與 MIG 環境中有效隔離及保護虛擬機器(VM)。H100 實現了世界上第一款原生機密運算 GPU,並以全 PCIe 線路速率,使用 CPU 延伸受信任的執行環境(trusted execution environment,TEE)。
- 相較於上一代 NVLink,第四代 NVIDIA NVLink,all-reduce 操作的頻寬增加了 3 倍,整體頻寬增加了 50%,而多 GPU IO 操作的總頻寬是每秒 900 GB,頻寬是 PCIe Gen 5 的 7 倍。
- 第三代 NVSwitch 技術包含常駐於節點內部和外部的交換器,以便在伺服器、叢集和資料中心環境中連接多個 GPU。節點內部的每一個 NVSwitch 皆提供 64 個第四代 NVLink 鏈路連接埠,以加快多 GPU 連線的能力。總交換器傳輸量,從上一代的每秒2 Tbit 增加到每秒 13.6 Tbit。新的第三代 NVSwitch 技術也是透過將多點傳送和 NVIDIA SHARP 網路內縮減為集體操作,提供硬體加速。
- 新的 NVLink Switch System 互連技術和以第三代 NVSwitch 技術為基礎的新型第二層 NVLink 交換器,皆導入位址空間隔離和保護,可以使用 2:1 錐形胖樹拓撲,透過 NVLink 連接多達 32 個節點或 256 個 GPU。這些連接的節點可以提供每秒6 TB 的全部對全部頻寬,且可供應令人難以置信之 exaFLOP 的 FP8 稀疏 AI 運算。
- PCIe Gen 5 提供每秒 128 GB 的總頻寬(各方向每秒 64 GB),Gen 4 PCIe 的總頻寬則為每秒 64 GB(各方向每秒 32GB)。PCIe Gen 5 讓 H100 可以與效能最高的 x86 CPU 和 SmartNIC 或資料處理單元(data processing unit,DPU)介接。
同時包含許多其他新功能,可以改進強縮放、降低延遲和負擔,並從整體上簡化 GPU 程式設計。
深入解析 NVIDIA H100 GPU 架構
使用最新 NVIDIA Hopper GPU 架構為基礎的 NVIDIA H100 GPU,具有多項創新:
- 新的第四代 Tensor 核心在更多種 AI 和 HPC 任務上,執行比以往更快的矩陣運算。
- 新的 transformer 引擎使 H100 可以為大型語言模型提供比上一代的 A100 快 9 倍的 AI 訓練加速,以及快 30 倍的 AI 推論加速。
- 新的 NVLink Network 互連可以跨多個運算節點,在多達 256 個 GPU 之間進行 GPU 對 GPU 通訊。
- 安全 MIG 將 GPU 劃分成孤立、大小適中的執行個體,以最大化小型工作負載的服務品質(quality of service,QoS)。
眾多其他新的架構特色,讓許多應用程式可以將效能提升高達 3 倍。
NVIDIA H100 是第一款真正的非同步 GPU。H100 將 A100 的全域至共用非同步傳輸延伸至所有位址空間,並增加支援張量記憶體存取模式。它讓應用程式可以建立將資料移入和移出晶片的端對端非同步管道,使資料移動與運算能完全重疊和隱藏。
現在僅需要小量的 CUDA 執行緒,即可使用新的 Tensor 記憶體加速器(TMA)管理 H100 的完整記憶體頻寬,而大多數其他 CUDA 執行緒則可著重於一般用途運算,例如新一代 Tensor 核心的預處理和後處理資料。
H100 可為 CUDA 執行緒群組階層,增加稱為執行緒區塊叢集的新層級。叢集是由保證同時調度,且能跨多個 SM 進行高效率執行緒協作和資料共用之執行緒區塊組成的群組。叢集也可更有效率地協作驅動非同步單元,例如 Tensor 記憶體加速器和 Tensor 核心。
在協調越來越多的晶片內加速器和不同的一般用途執行緒群組時必須同步。例如,使用輸出的執行緒和加速器時,必須等候產生它們的執行緒和加速器。
NVIDIA 非同步交易屏障讓叢集中的一般用途 CUDA 執行緒與晶片內加速器可以有效率地同步,即使它們常駐於不同的 SM 上也一樣。這些新功能讓每一個使用者和應用程式都能隨時充分利用 H100 GPU 的所有單元,使 H100 成為到目前為止最強大、最可程式化與節能的 NVIDIA GPU。
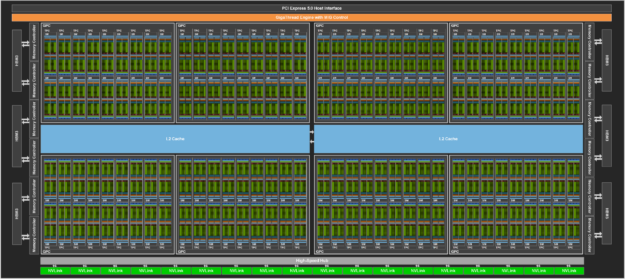
驅動 H100 GPU 的完整 GH100 GPU 是採用為 NVIDIA 客製化的 TSMC 4N 製程進行製造,具備 800 億個電晶體、814 mm2 的裸晶大小,以及更高頻率的設計。
NVIDIA GH100 GPU 是由多個 GPU 處理叢集(GPU processing cluster,GPC)、紋理處理叢集(texture processing cluster,TPC)、串流多處理器(streaming multiprocessor,SM)、L2 快取和 HBM3 記憶體控制器組成。
GH100 GPU 的完整建置包含下列單元:
- 8 個 GPC、72 個 TPC(每一個 GPC有 9 個 TPC)、每一個 TPC 有 2 個 SM,每一個完整 GPU 有144 個 SM
- 每一個 SM 有 128 個 FP32 CUDA 核心,每一個完整 GPU 有18432 個 FP32 CUDA 核心
- 每一個 SM 有 4 個第四代 Tensor 核心,每一個完整 GPU 有 576 個
- 6 個 HBM3 或 HBM2e 堆疊,12 個 512 位元記憶體控制器
- 60 MB L2 快取
- 第四代 NVLink 和 PCIe Gen 5
採用 SXM5 機板外型規格的 NVIDIA H100 GPU,包含下列單元:
- 8 個 GPC,66 個 TPC,每一個 TPC 有2 個 SM,每一個 GPU 有 132 個 SM
- 每一個 SM 有 128 個 FP32 CUDA 核心,每一個 GPU 有16896 個 FP32 CUDA 核心
- 每一個 SM 有 4 個第四代 Tensor 核心,每一個 GPU 有528 個
- 80 GB HBM3,5 個 HBM3 堆疊,10 個 512 位元記憶體控制器
- 50 MB L2 快取
- 第四代 NVLink 和 PCIe Gen 5
採用 PCIe Gen 5 機板外型規格的 NVIDIA H100 GPU,包含下列單元:
- 7 或 8 個 GPC,57 個 TPC,每一個 TPC 有 2 個 SM,每一個 GPU 有 114 個 SM
- 每一個 SM 有 128 個 FP32 CUDA 核心,每一個 GPU 有 14592 個 FP32 CUDA 核心
- 每一個 SM 有 4 個第四代 Tensor 核心,每一個 GPU 有 456 個
- 80 GB HBM2e,5 個 HBM2e 堆疊,10 個 512 位元記憶體控制器
- 50 MB L2 快取
- 第四代 NVLink 和 PCIe Gen 5
相較於以 TSMC 7nm N7 製程為基礎的上一代 GA100 GPU,採用 TSMC 4N 製程可以使 H100 提高 GPU 核心頻率、改善每瓦效能,以及納入更多的 GPC、TPC 和 SM。
圖 3 所示為具有 144 個 SM 的完整 GH100 GPU。H100 SXM5 GPU 有 132 個 SM,PCIe 版本有 114 個 SM。H100 GPU 主要用於為 AI、HPC 和資料分析執行資料中心和邊緣運算工作負載,但是不包括圖形處理。在 SXM5 和 PCIe H100 GPU 中只有兩個 TPC 具備圖形功能(也就是說,它們可以執行頂點、幾何及像素著色器)。
H100 SM 架構
H100 SM 是以 NVIDIA A100 Tensor 核心 GPU SM 架構為基礎,因為導入 FP8,而使 A100 峰值每 SM 浮點的運算能力提升四倍,並使在所有先前之 Tensor 核心、FP32 和 FP64 資料類型上的 A100 原始 SM 運算能力加倍,時脈對時脈。
新的 transformer 引擎與 NVIDIA Hopper FP8 Tensor 核心結合,為大型語言模型提供比上一代 A100 快 9 倍的 AI 訓練加速,以及快 30 倍的 AI 推論加速。新的 NVIDIA Hopper DPX 指令可以將用於基因體學和蛋白質定序的 Smith-Waterman 演算法處理加快 7 倍。
新的 NVIDIA Hopper 第四代 Tensor 核心、Tensor Memory Accelerator 及許多其他新的 SM 和一般 H100 架構改進,在許多其他情況下可以共同提供加快 3 倍的 HPC 和 AI 效能。
|
NVIDIA H100 SXM51 |
NVIDIA H100 PCIe1 |
|
|
峰值 FP641 |
30 TFLOPS |
24 TFLOPS |
|
峰值 FP64 Tensor 核心1 |
60 TFLOPS |
48 TFLOPS |
|
峰值 FP321 |
60 TFLOPS |
48 TFLOPS |
|
峰值 FP161 |
120 TFLOPS |
96 TFLOPS |
|
峰值 BF161 |
120 TFLOPS |
96 TFLOPS |
|
峰值 TF32 Tensor 核心1 |
500 TFLOPS | 1000 TFLOPS2 |
400 TFLOPS | 800 TFLOPS2 |
|
峰值 FP16 Tensor 核心1 |
1000 TFLOPS | 2000 TFLOPS2 |
800 TFLOPS | 1600 TFLOPS2 |
|
峰值 BF16 Tensor 核心1 |
1000 TFLOPS | 2000 TFLOPS2 |
800 TFLOPS | 1600 TFLOPS2 |
|
峰值 FP8 Tensor 核心1 |
2000 TFLOPS | 4000 TFLOPS2 |
1600 TFLOPS | 3200 TFLOPS2 |
|
峰值 INT8 Tensor 核心1 |
2000 TOPS | 4000 TOPS2 |
1600 TOPS | 3200 TOPS2 |
表 1:NVIDIA H100 Tensor 核心 GPU 初步效能規格
1根據目前預期之 H100 的初步效能估計,上市產品可能會改變
2使用稀疏性功能時有效的 TFLOPS / TOPS
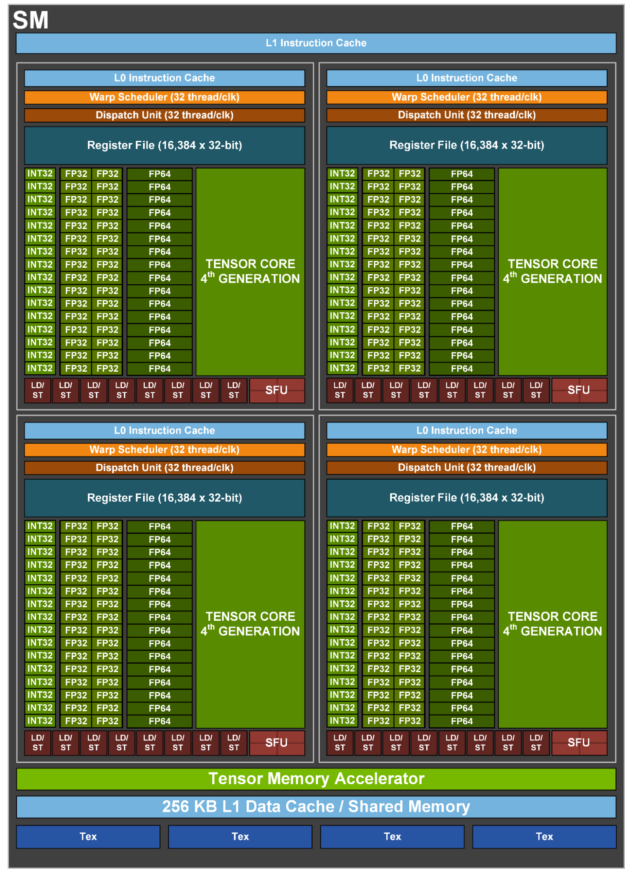
H100 SM 主要特色摘要
- 第四代 Tensor 核心:
- 晶片間之速度比 A100 快 6 倍,包括每一個 SM 加速、更多的 SM 數量,以及 H100 更高的時脈。
- 相較於上一代 16 位元浮點選項,每一個 SM 的 Tensor 核心,在相等資料類型上的 MMA(Matrix Multiply-Accumulate,矩陣相乘累加)運算速率為 A100 SM 的 2 倍,使用新的 FP8 資料類型時為 A100 的 4 倍。
- 稀疏性功能是利用深度學習網路中的細粒度結構化稀疏性,使標準 Tensor 核心運作的效能加倍
- 新的 DPX 指令將動態規劃演算法的速度提高達 A100 GPU 的 7 倍。兩個範例包括基因體學處理的 Smith-Waterman 演算法,以及尋找最佳路線,讓機器人在動態倉庫環境中行進的 Floyd-Warshall 演算法。
- IEEE FP64 和 FP32 晶片間之處理速率比 A100 快 3 倍,因為每一個 SM 的時脈對時脈效能加快了 2 倍,加上 SM 數量更多及 H100 的時脈更高。
- 256 KB 的組合共用記憶體和 L1 資料快取,是 A100 的33 倍。
- 新的非同步執行功能,包含新的 Tensor Memory Accelerator(TMA)單元,可以在全域記憶體與共用記憶體之間有效率地傳輸大型資料區塊。TMA 同時可支援在叢集中的執行緒區塊之間進行非同步複製。還有一個新的非同步交易屏障,可以移動原子資料和進行同步。
- 新的執行緒區塊叢集功能可以跨多個 SM 公開局部性控制。
- 分散式共用記憶體可以直接進行 SM 對 SM 通訊,並能跨多個 SM 共用記憶體區塊進行載入、儲存和原子操作
H100 Tensor 核心架構
Tensor 核心是矩陣相乘和累加(MMA)數學運算專用的高效能運算核心,可以為 AI 和 HPC 應用程式提供突破性的效能。相較於標準浮點(FP)、整數(INT)和融合相乘累加(FMA)運算,在一個 NVIDIA GPU 中跨 SM 平行運作的 Tensor 核心可以大幅提高傳輸量和效率。
Tensor 核心是首次導入 NVIDIA V100 GPU 中,並會隨著每一個新的 NVIDIA GPU 架構世代進一步強化。
H100 中新的第四代 Tensor 核心架構提供之時脈對時脈每 SM 原始密集和稀疏矩陣數學傳輸量,是 A100 的兩倍,且在考量到 H100 的 GPU 加速時脈高於 A100 時,甚至更多。支援 FP8、FP16、BF16、TF32、FP64 和 INT8 MMA 資料類型。新的 Tensor 核心的資料管理也更具有效率,可以節省高達 30% 的運算元傳遞能力。
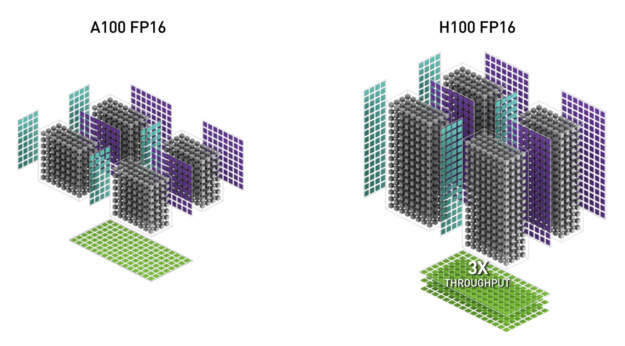
NVIDIA Hopper FP8 資料格式
H100 GPU 增加了 FP8 Tensor 核心,以加快 AI 訓練和推論。如圖 6 所示,FP8 Tensor 核心可以支援 FP32 和 FP16 累加器,以及兩種新的 FP8 輸入類型:
- E4M3,具有 4 個指數位元、3 個尾數位元和 1 個符號位元
- E5M2,具有 5 個指數位元、2 個尾數位元和 1 個符號位元
E4M3 支援需要較小之動態範圍與較高之精度的運算,E5M2 則是提供較寬的動態範圍和較低的精度。相較於 FP16 或 BF16,FP8 的資料儲存要求已減半,且傳輸量已加倍。
本文將於之後說明新 transformer 引擎使用 FP8 和 FP16 精度減少記憶體用量與提高效能,同時維持大型語言及其他模型的準確度。
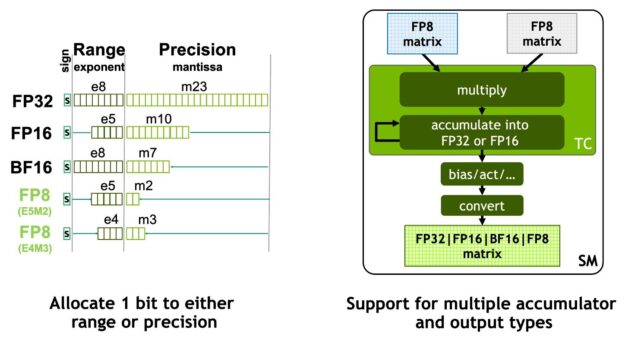
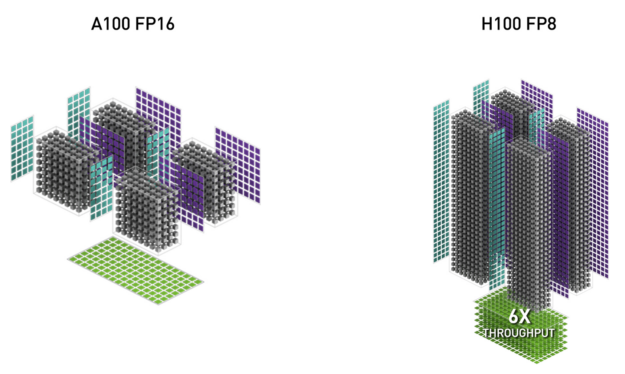
表 2 顯示多種資料類型之 H100 的加速效果超越 A100。
|
(以 TFLOPS 為單位) |
A100 |
A100 Sparse |
H100 SXM51 |
H100 SXM51 Sparse |
H100 SXM51 與 A100 相較的加速效果 |
|
FP8 Tensor 核心 |
2000 |
4000 |
A100 FP16 的 6.4 倍 |
||
|
FP16 |
78 |
120 |
1.5 倍 |
||
|
FP16 Tensor 核心 |
312 |
624 |
1000 |
2000 |
3.2 倍 |
|
BF16 Tensor 核心 |
312 |
624 |
1000 |
2000 |
3.2 倍 |
|
FP32 |
19.5 |
60 |
3.1 倍 |
||
|
TF32 Tensor 核心 |
156 |
312 |
500 |
1000 |
3.2 倍 |
|
FP64 |
9.7 |
30 |
3.1 倍 |
||
|
FP64 Tensor 核心 |
19.5 |
60 |
3.1 倍 |
||
|
INT8 Tensor 核心 |
624 TOPS |
1248 TOPS |
2000 |
4000 |
3.2 倍 |
表 2:H100 與 A100 相較的加速效果(初步 H100 效能,TC=Tensor 核心)。除另有說明外,所有測量值均以 TFLOPS 為單位。
1根據目前預期之 H100 的初步效能估計,上市產品可能會改變
新的 DPX 指令加快動態規劃
許多蠻力最佳化演算法皆具有在解開較大的問題時,多次重複使用子問題解法的特性。動態規劃(Dynamic programming,DP)是一種將複雜的遞迴問題,分解成較簡單之子問題進行解決的演算法技術。DP 演算法會儲存子問題的結果,無須在之後需要時重新運算,可以將指數問題集的運算複雜度降低至線性標準。
DP 通常是使用在各種最佳化、資料處理和基因體學演算法中。
- 在迅速成長的基因體定序領域,Smith-Waterman DP 演算法是最重要的使用方法之一。
- 在機器人領域,Floyd-Warshall 是一種關鍵的演算法,可以即時尋找最佳路線,讓機器人在動態倉庫環境中行進。
將 H100 導入 DPX 指令中,可以使 DP 演算法的效能比 NVIDIA Ampere GPU 快 7 倍。這些新指令可以為許多 DP 演算法的內迴圈提供進階融合運算元支援。因此可以大幅加快解決疾病診斷、最佳化物流路線,甚至是圖表分析的時間。
H100 運算效能摘要
整體而言,在考量 H100 所有新運算技術的進步之後,H100 提供的運算效能大約比 A100 高 6 倍。圖 10 以串接方式總結 H100 的改進:
- 相較於 A100 的 108 個 SM,132 個 SM 的 SM 數量增加了 22%
- 由於出現了新的第四代 Tensor 核心,使每一個 H100 SM 都加快 2 倍。
- 在每一個 Tensor 核心中,新的 FP8 格式與相關之 transformer 引擎另外提供 2 倍的改進。
- H100 的時脈頻率提高,可以另外提升大約3 倍的效能。
這些改進總計使 H100 的峰值運算傳輸量達到 A100 的大約 6 倍,對於世界上最需要運算的工作負載而言是一大躍進。
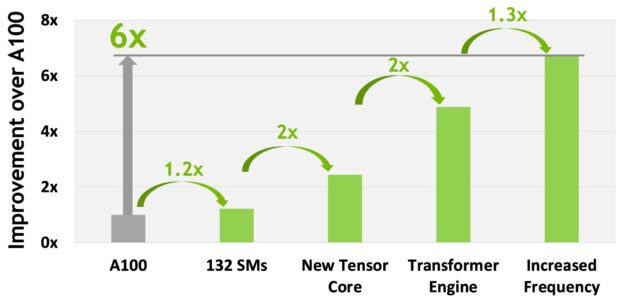
H100 為世界上最需要運算之工作負載提供 6 倍的傳輸量。
H100 GPU 階層和非同步改進
在平行程式中實現高效能的兩個必要關鍵,為資料局部性和非同步執行。程式設計師可以透過將程式資料移動至盡可能靠近執行單元的位置,利用更低之延遲和更高之頻寬存取近端資料帶來的效能。非同步執行需要尋找獨立任務,以便與記憶體傳輸及其他處理重疊。目標是充分利用 GPU 中的所有單元。
在下一節,將探索在 NVIDIA Hopper 中新增至 GPU 程式設計階層的重要新層次,以比單一 SM 上之單一執行緒區塊更大的規模公開局部性。我們同時將說明可提高效能及降低同步負擔之新的非同步執行功能。
執行緒區塊叢集
CUDA 程式設計模型長期仰賴使用包含多個執行緒區塊的網格,利用程式中之局部性的 GPU 運算架構。一個執行緒區塊包含多個在單一 SM 上同時運作的執行緒,其中的執行緒可以與快速屏障同步,並使用 SM 的共用記憶體交換資料。但是,隨著 GPU 成長超過 100 個 SM,運算程式也變得更複雜,以執行緒區塊做為程式設計模型中的唯一局部性單元,已不足以最大化執行效率。
H100 導入了新的執行緒區塊叢集架構,將能以比單一 SM 上之單一執行緒區塊更大的粒度公開局部性控制。執行緒區塊叢集延伸了 CUDA 程式設計模型,並為 GPU 的實體設計階層另外增加一層,包括執行緒、執行緒區塊、執行緒區塊叢集和網格。
叢集是由保證同時調度至 SM 群組上之執行緒區塊組成的群組,目標是跨多個 SM 進行高效率的執行緒協作。H100 中的叢集是跨 GPC 中的 SM 同時執行。
GPC 是由硬體階層中,在實體上持續彼此接近之 SM 組成的群組。叢集具有硬體加速屏障和新的記憶體存取協作功能,將在以下內容中進行探討。GPC 中之 SM 專用的 SM 對 SM 網路,在叢集中的執行緒之間提供快速資料共用。
如圖 11 所示,在 CUDA 中可以選擇在核心啟動時,將網格中的執行緒區塊分組至叢集,且可從 CUDA cooperative_groups API 中利用叢集功能。
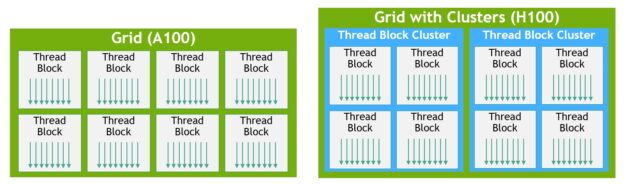
網格是由 A100 舊版 CUDA 程式設計模型中的執行緒區塊組成,如圖的左半部所示。NVIDIA Hopper 架構增加了選用的叢集階層,如圖的右半部所示。
分散式共用記憶體
所有執行緒都可以利用叢集,透過載入、儲存和原子操作直接存取其他 SM 的共用記憶體。此功能稱為分散式共用記憶體(distributed shared memory,DSMEM),因為在邏輯上,共用記憶體虛擬位址空間是分布於叢集中的所有區塊。
DSMEM 使 SM 之間可以更有效率地交換資料,而無須以將資料寫入全域記憶體或從中讀取資料的方式傳遞資料。叢集的專用 SM 對 SM 網路,可以確保快速、低延遲地存取遠端 DSMEM。相較於使用全域記憶體,DSMEM 將執行緒區塊之間的資料交換加快大約 7 倍。
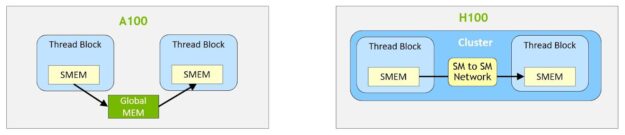
在 CUDA 層級中,來自叢集之所有執行緒區塊的所有 DSMEM 區段,皆可對映至各個執行緒的通用位址空間,因此可以透過簡單的指標直接參照所有 DSMEM。CUDA 使用者可以利用 cooperative_groups API 建構,指向叢集中任何執行緒區塊的通用指標。DSMEM 傳輸也可以表示做為與以共用記憶體為基礎之屏障同步的非同步複製操作,追蹤完成度。
圖 13 為在不同演算法上使用叢集的效能優勢。叢集讓您可以直接控制 GPU 的較大部分,而不是限於單一 SM,以提高效能。叢集可以讓更大量的執行緒協作執行,相較於僅使用單一執行緒區塊,將能存取更大的共用記憶體集區。
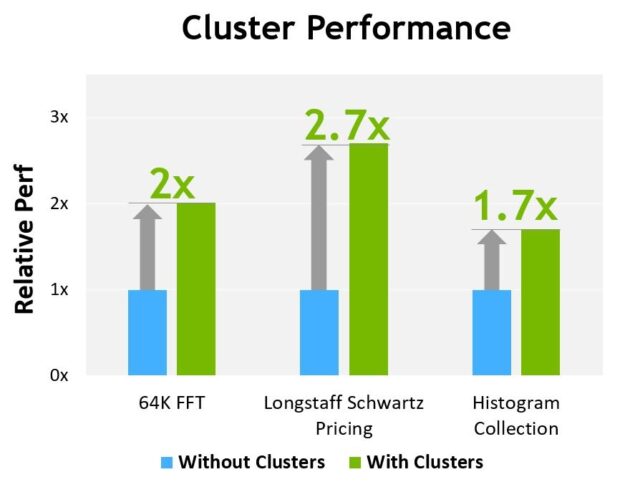
根據目前預期之 H100 的初步效能估計,上市產品可能會改變。
非同步執行
每一個新一代 NVIDIA GPU 都包含許多架構增強功能,以改進效能、可程式性、電源效率、GPU 利用率及許多其他因素。近期的 NVIDIA GPU 世代加入了非同步執行功能,讓資料移動、運算與同步具有更多的重疊。
NVIDIA Hopper 架構提供的新功能,可以改進非同步執行,並可讓記憶體複本與運算及其他獨立工作進一步重疊,同時能最小化同步點。我們說明了新的非同步記憶體複製單元 Tensor Memory Accelerator(TMA)和新的非同步交易屏障。
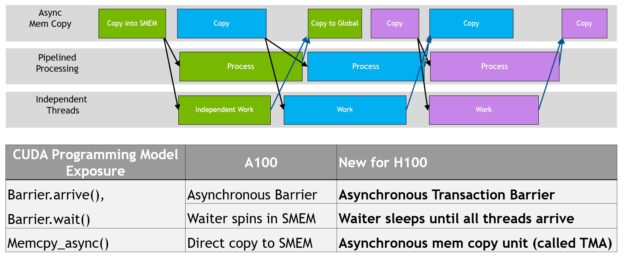
資料移動、運算與同步的程式重疊。非同步並行和最小化同步點是效能的關鍵。
Tensor Memory Accelerator
為了有助於提供強大的新型 H100 Tensor 核心,透過新的 Tensor Memory Accelerator(TMA)提高資料擷取效率,可以將大型資料區塊和多維度張量,從全域記憶體傳輸至共用記憶體以及再次傳回。
使用複製描述元啟動 TMA 操作,該描述元是使用張量維度和區塊座標指定資料傳輸,而不是逐元素定址(圖 15)。可以指定大型資料區塊(最高可達共用記憶體容量),並將其從全域記憶體載入共用記憶體,或從共用記憶體儲存回全域記憶體。TMA 可以大幅減輕定址負擔及提高效率,同時支援不同的張量配置((1D-5D 張量)、不同的記憶體存取模式、縮減與其他功能。
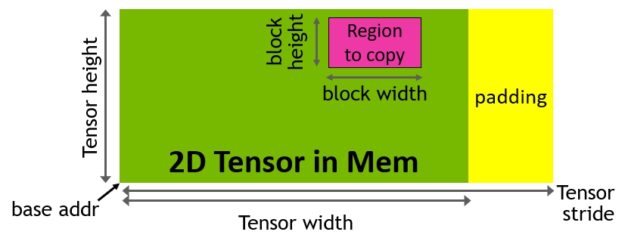
TMA 操作是屬於非同步,並利用 A100 導入之以共用記憶體為基礎的非同步屏障。此外,TMA 程式設計模型為單執行緒,可選擇執行緒束中的單一執行緒發出非同步 TMA 操作(cuda::memcpy_async)以複製張量。因此,可能會有多個執行緒等候 cuda::barrier 完成資料傳輸。為了進一步提高效能,H100 SM 增加了硬體,以加快這些非同步屏障等候操作的速度。
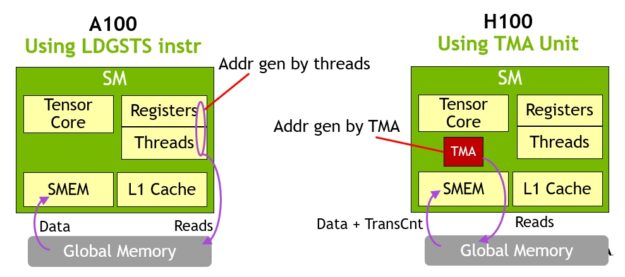
TMA 的主要優勢為可釋放執行緒,以執行其他的獨立工作。在 A100 (圖 16,左)上,是使用特殊的 LoadGlobalStoreShared 指令執行非同步記憶體複製,所以由執行緒負責產生所有的位址,並在整個複製區域中循環。
在 NVIDIA Hopper 上,是由 TMA 進行所有的處理。單一執行緒在啟動 TMA 之前會建立一個複製描述元,之後會在硬體中處理位址產生和資料移動。TMA 提供了一個更簡單的程式設計模型,可以在複製張量區段時,接管運算跨距、偏移和邊界計算的任務。
非同步交易屏障
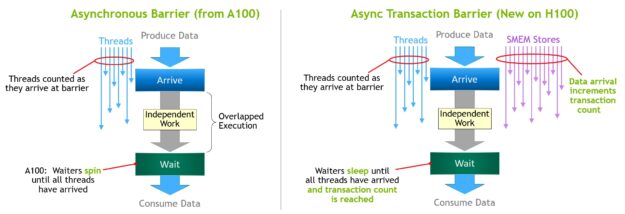
非同步屏障最初是在 NVIDIA Ampere 架構中導入(圖 17,左)。假設多個執行緒產生了在屏障之後都會使用的資料。非同步屏障將同步過程分成兩個步驟。
- 首先,執行緒在完成產生共用資料部分之後發出 Arrive 訊號。此 Arrive 不會造成阻礙,因此執行緒可以自由執行其他的獨立工作。
- 最後,執行緒需要所有其他執行緒產生的資料。此時,將會執行 Wait 以進行阻擋,直至每一個執行緒都發出 Arrive 訊號。
非同步屏障的優點是提前抵達的執行緒可以在等候時執行獨立工作。此重疊是額外效能的來源。如果所有執行緒都有足夠的獨立工作時,實際上,屏障會變得空閒,因為所有執行緒都已抵達,可立即撤回 Wait 指令。
NVIDIA Hopper 的新功能是讓等候中的執行緒休眠,直至所有的其他執行緒抵達。在先前的晶片上,等候中之執行緒會在共用記憶體中的屏障物件上旋轉。
雖然非同步屏障仍是 NVIDIA Hopper 程式設計模型的一部分,但是增加了新的屏障形式,稱為非同步交易屏障。非同步交易屏障與非同步屏障類似(圖 17,右)。它也是一種分割屏障,但是會計算交易,而非僅計算執行緒抵達。
NVIDIA Hopper 包含一個新的命令,可以寫入共用記憶體,以傳遞想要寫入的資料以及交易計數。基本上,交易計數是位元組計數。非同步交易屏障是根據 Wait 命令阻擋執行緒,直至所有生產者執行緒皆已執行 Arrive,且所有交易計數的總和已達到預期值。
非同步交易屏障是一種強大的新基元,可以進行非同步記憶體複製或資料交換。如前所述,叢集可以進行執行緒區塊間通訊,以透過隱式同步交換資料,且該叢集功能是以非同步交易屏障為基礎。
H100 HBM 和 L2 快取記憶體架構
GPU 的記憶體架構與階層設計是應用程式效能的關鍵,且會影響 GPU 的大小、成本、功耗和可程式性。GPU 中存有許多記憶體子系統,從大量的晶片外 DRAM(畫格緩衝區)裝置記憶體,以及不同層級和類型的晶片內記憶體,到用於 SM 運算的暫存器檔案。
H100 HBM3 和 HBM2e DRAM 子系統
隨著 HPC、AI 和資料分析資料集的規模不斷成長,以及運算問題變得越來越複雜,使更大的 GPU 記憶體容量和頻寬變得不可或缺。
- NVIDIA P100 是世界上第一個支援高頻寬 HBM2 記憶體技術的 GPU 架構。
- NVIDIA V100 提供了更快、更有效率及容量更高的 HBM2 建置。
- NVIDIA A100 GPU 進一步提高了 HBM2 的效能和容量。
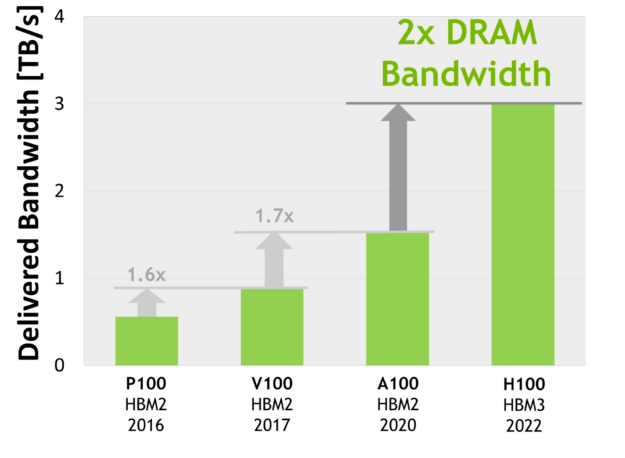
H100 SXM5 GPU 透過支援 80 GB(5個堆疊)的快速 HBM3 記憶體,而大幅提高標準,提供超過每秒 3 TB 的記憶體頻寬,相較於兩年前推出的 A100 記憶體,頻寬增加了 2 倍。PCIe H100 提供 80 GB 的快速 HBM2e,且記憶體頻寬超過每秒 2 TB。
記憶體資料速率尚未確定,最終產品可能會改變。
H100 L2 快取
H100 中的 50 MB L2 快取比 A100 40 MB L2 大 1.25 倍。它可以快取更大部分的模型和資料集以供反覆存取,進而減少通往 HBM3 或 HBM2e DRAM 的行程,並提高效能。
採用分區交錯結構的 L2 快取,針對資料進行局部化和快取,以便直接連接至分割區之 GPC 中的 SM 存取記憶體。L2 快取常駐控制可以最佳化容量利用率,讓您能選擇性地管理應保留在快取中或被逐出的資料。
HBM3 或 HBM2e DRAM 和 L2 快取子系統皆可支援資料壓縮和解壓縮技術,最佳化記憶體及快取使用與效能。
|
GPU 功能 |
NVIDIA A100 |
NVIDIA H100 SXM51 |
NVIDIA H100 PCIe1 |
|
GPU 架構 |
NVIDIA Ampere |
NVIDIA Hopper |
NVIDIA Hopper |
|
GPU 機板外型規格 |
SXM4 |
SXM5 |
PCIe Gen 5 |
|
SM |
108 |
132 |
114 |
|
TPC |
54 |
66 |
57 |
|
每一個 SM 的 FP32 核心 |
64 |
128 |
128 |
|
每一個 GPU 的 FP32 核心 |
6912 |
16896 |
14592 |
|
每一個 SM 的 FP64 核心 (Tensor 除外) |
32 |
64 |
64 |
|
每一個 GPU 的 FP64 核心 (Tensor 除外) |
3456 |
8448 |
7296 |
|
每一個 SM 的 INT32 核心 |
64 |
64 |
64 |
|
每一個 GPU 的 INT32 核心 |
6912 |
8448 |
7296 |
|
每一個 SM 的 Tensor 核心 |
4 |
4 |
4 |
|
每一個 GPU 的 Tensor 核心 |
432 |
528 |
456 |
|
GPU 加速時脈 |
1410 MHz |
尚未確定 |
尚未確定 |
|
FP16 累加的峰值 FP8 Tensor TFLOPS1 |
無 |
2000/40002 |
1600/32002 |
|
FP32 累加的峰值 FP8 Tensor TFLOPS1 |
無 |
2000/40002 |
1600/32002 |
|
FP16 累加的峰值 FP16 Tensor TFLOPS1 |
312/6242 |
1000/20002 |
800/16002 |
|
FP32 累加的峰值 FP16 Tensor TFLOPS1 |
312/6242 |
1000/20002 |
800/16002 |
|
FP32 累加的峰值 BF16 Tensor TFLOPS1 |
312/6242 |
1000/20002 |
800/16002 |
|
峰值 TF32 Tensor TFLOPS1 |
156/3122 |
500/10002 |
400/8002 |
|
峰值 FP64 Tensor TFLOPS1 |
19.5 |
60 |
48 |
|
峰值 INT8 Tensor TOPS1 |
624/12482 |
2000/40002 |
1600/32002 |
|
峰值 FP16 TFLOPS (非 Tensor)1 |
78 |
120 |
96 |
|
峰值 BF16 TFLOPS (非 Tensor)1 |
39 |
120 |
96 |
|
峰值 FP32 TFLOPS (非 Tensor)1 |
19.5 |
60 |
48 |
|
峰值 FP64 TFLOPS (非 Tensor)1 |
9.7 |
30 |
24 |
|
峰值 INT32 TOPS1 |
19.5 |
30 |
24 |
|
紋理單元 |
432 |
528 |
456 |
|
記憶體介面 |
5120 位元 HBM2 |
5120 位元 HBM3 |
5120 位元 HBM2e |
|
記憶體大小 |
40 GB |
80 GB |
80 GB |
|
記憶體資料速率 |
1215 MHz DDR |
尚未確定 |
尚未確定 |
|
記憶體頻寬1 |
每秒 1555 GB |
每秒 3000 GB |
每秒 2000 GB |
|
L2 快取大小 |
40 MB |
50 MB |
50 MB |
|
每一個 SM 的共用記憶體大小 |
可配置,最高可達 164 KB |
可配置,最高可達 228 KB |
可配置,最高可達 228 KB |
|
每一個 SM 的暫存器檔案大小 |
256 KB |
256 KB |
256 KB |
|
每一個 GPU 的暫存器檔案大小 |
27648 KB |
33792 KB |
29184 KB |
|
TDP1 |
400 瓦 |
700 瓦 |
350 瓦 |
|
電晶體 |
542 億 |
800 億 |
800 億 |
|
GPU 裸晶大小 |
826 mm2 |
814 mm2 |
814 mm2 |
|
TSMC 製程 |
7 nm N7 |
為 NVIDIA 客製化的 4N |
為 NVIDIA 客製化的 4N |
表 3:NVIDIA A100 與 H1001 資料中心 GPU 的比較
1根據目前預期之 H100 的初步規格,上市產品可能會改變
2使用稀疏性功能的有效 TOPS / TFLOPS
3NVIDIA 資料中心 GPU 的 GPU 峰值時脈與 GPU 加速時脈相同
由於 H100 和 A100 Tensor 核心 GPU 是設計為安裝在高效能伺服器和資料中心機架中,以驅動 AI 和 HPC 運算工作負載,因此不包含顯示器接頭、用於光線追蹤加速的 NVIDIA RT 核心,或 NVENC 編碼器。
Compute Capability
H100 GPU 可支援新的 Compute Capability 9.0。表 4 比較 NVIDIA GPU 架構之不同運算能力的參數。
|
資料中心 GPU |
NVIDIA V100 |
NVIDIA A100 |
NVIDIA H100 |
|
GPU 架構 |
NVIDIA Volta |
NVIDIA Ampere |
NVIDIA Hopper |
|
運算能力 |
7.0 |
8.0 |
9.0 |
|
每一個執行緒束的執行緒 |
32 |
32 |
32 |
|
每一個 SM 的執行緒束上限 |
64 |
64 |
64 |
|
每一個 SM 的執行緒上限 |
2048 |
2048 |
2048 |
|
每一個 SM 的執行緒區塊(CTA)上限 |
32 |
32 |
32 |
|
每一個執行緒區塊叢集的執行緒區塊上限 |
無 |
無 |
16 |
|
每一個 SM 的 32 位元暫存器上限 |
65536 |
65536 |
65536 |
|
每一個執行緒區塊(CTA)的暫存器上限 |
65536 |
65536 |
65536 |
|
每一個執行緒的暫存器上限 |
255 |
255 |
255 |
|
執行緒區塊大小(執行緒數量)的上限 |
1024 |
1024 |
1024 |
|
每一個 SM 的 FP32 核心 |
64 |
64 |
128 |
|
SM 暫存器與 FP32 核心的比例 |
1024 |
1024 |
512 |
|
每一個 SM 的共用記憶體大小 |
可配置,最高達 96 KB |
可配置,最高可達 164 KB |
可配置,最高可達 228 KB |
表 1:運算能力:V100 vs. A100 vs. H100
Transformer 引擎
Transformer 模型是現今廣泛採用之語言模型(從 BERT 到 GPT-3)的骨幹,需要龐大的運算資源。最初為了自然語言處理(NLP)而開發的 transformer,已逐漸應用在電腦視覺、藥物探索等各種領域中。
Transformer 的大小不斷以倍數增加,現在已達到數兆個參數,並導致訓練時間延長達數個月,由於運算需求很大,在業務需求方面很不切實際。例如,在進行訓練時,Megatron Turing NLG(MT-NLG)需要 2048 個 NVIDIA A100 GPU 運作 8 週。整體而言,在過去 5 年內,transformer 模型的成長速度已超越大多數其他 AI 模型,大約每 2 年成長 275 倍(圖 19)。
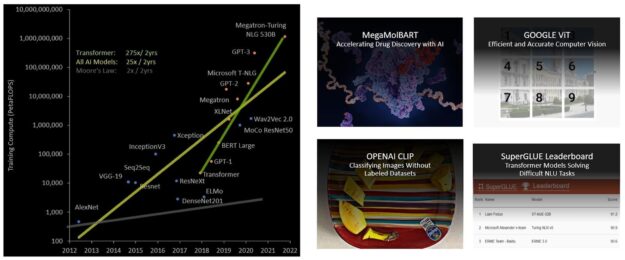
H100 包含新的 transformer 引擎,可使用軟體和自訂的 NVIDIA Hopper Tensor 核心技術,大幅加快 transformer 的 AI 運算。
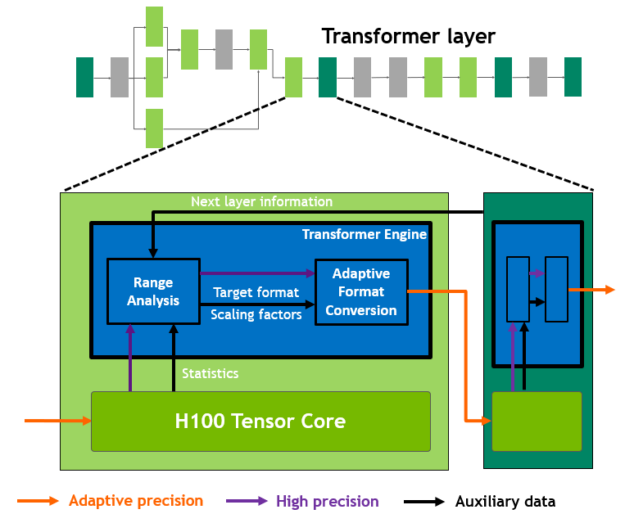
混合精度之目的是以智慧化方式管理精度,以維持準確度,同時持續獲得更小、更快的數值格式效能。Transformer 引擎會在 transformer 模型的每一層,分析 Tensor 核心產生的輸出值統計資料。
Transformer 引擎會在瞭解接下來的神經網路層類型及需要的精度之後,決定將張量轉換成哪一種目標格式,然後儲存至記憶體中。FP8 的範圍比其他數值格式更有限。
為了以最佳方式使用可用範圍,transformer 引擎會使用根據張量統計資料計算的縮放因數,以動態方式,將張量資料縮放至可表示的範圍內。因此,每一層都是在需要的範圍內運作,並以最佳方式加速。
第四代 NVLink 和 NVLink Network
超人類對話式 AI 等任務使用的新興 Exascale HPC 和上兆參數 AI 模型,需要進行數月的訓練,即使是超級電腦亦同。想要將延長的訓練時間從數個月壓縮至數天,為企業帶來更多助益時,必須在伺服器叢集中的每一個 GPU 之間進行高速無縫通訊。PCIe 因頻寬有限而造成瓶頸。想要建立最強大的端對端運算平台,需要更快速、更具擴充性的 NVLink 互連。
NVLink 是 NVIDIA 之高頻寬、節能、低延遲、無損的 GPU 對 GPU 互連,包括復原功能,例如鏈路層級錯誤偵測、封包重放機制,以確保成功的資料傳輸。相較於 NVIDIA A100 Tensor 核心 GPU 採用的第三代 NVLink,H100 GPU 採用新的第四代 NVLink,提供 1.5 倍的通訊頻寬。
新的 NVLink 是以每秒 900 GB 之總頻寬運作多 GPU I/O 和共用記憶體存取,提供的頻寬為 PCIe Gen 5 的 7 倍。A100 GPU 中的第三代 NVLink 在各方向使用四個差動對(通道)建立單一鏈路,以在各方向提供每秒 25 GB 的有效頻寬。相較之下,第四代 NVLink 在各方向僅使用兩個高速差動對建立單一鏈路,且同樣在各方向提供每秒 25 GB 的有效頻寬。
- H100 包含 18 個第四代 NVLink 鏈路,提供每秒 900 GB 的總頻寬。
- A100 包含 12 個第三代 NVLink 鏈路,提供每秒 600 GB 的總頻寬。
除第四代 NVLink 外,H100 也導入了新的 NVLink Network 互連,它是 NVLink 的可擴充版本,可以跨多個運算節點,在多達 256 個 GPU 之間進行 GPU 對 GPU 通訊。
標準的 NVLink 可以讓所有 GPU 共用同一個位址空間,並直接使用 GPU 實體位址傳遞要求,而 NVLink Network 則導入了新的網路位址空間。其係由 H100 中新的位址轉譯硬體支援,可以將所有 GPU 位址空間相互隔離,並與網路位址空間隔離。讓 NVLink Network 能夠安全地擴充至更大量的 GPU。
由於 NVLink Network 端點不共用同一個記憶體位址空間,因此不會在整體系統中自動建立 NVLink Network 連線。相反的,使用者軟體應與 InfiniBand 等其他網路介面一樣,視需要顯式建立端點之間的連線。
第三代 NVSwitch
新的第三代 NVSwitch 技術包含常駐於節點內部和外部的交換器,可以在伺服器、叢集和資料中心環境中連接多個 GPU。節點內部每一個新的第三代 NVSwitch 皆提供 64 個第四代 NVLink 鏈路連接埠,以加快多 GPU 連線能力。總交換器傳輸量,從上一代的每秒 7.2 Tbit 增加到每秒 13.6 Tbit。
新的第三代 NVSwitch 同時透過多點傳送和 NVIDIA SHARP 網路內縮減,提供集體操作的硬體加速。加速集體包括 write broadcast(all_gather)、reduce_scatter 和 broadcast atomics。相較於在 A100 上使用 NVIDIA Collective Communications Library(NCCL),結構內多點傳送和縮減可提供高達 2 倍的傳輸量增益,同時能大幅降低小型區塊大小集體的延遲。集體的 NVSwitch 加速,顯著降低了集體通訊的 SM 負載。
新的 NVLink Switch System
將新的 NVLINK Network 技術與新的第三代 NVSwitch 結合,讓 NVIDIA 可以建立前所未見之通訊頻寬水準的大型縱向擴充 NVLink Switch System 網路。每一個 GPU 節點都會公開節點中 GPU 之所有 NVLink 頻寬的 2:1 錐形層級。節點是透過 NVLink Switch 模組中包含的第二層 NVSwitch 連接在一起,這些模組常駐於運算節點外部,並將多個節點連接在一起。
NVLink Switch System 最多可支援 256 個 GPU。連接之節點可以提供 57.6 TB 的全部對全部頻寬,且可供應令人難以置信之 exaFLOP 的 FP8 稀疏 AI 運算。
圖 21 為以 A100 與 H100 為基礎之 32 節點 256 GPU DGX SuperPOD 的比較。以 H100 為基礎的 SuperPOD,可以選擇使用新的 NVLink Switch 將 DGX 節點互連。
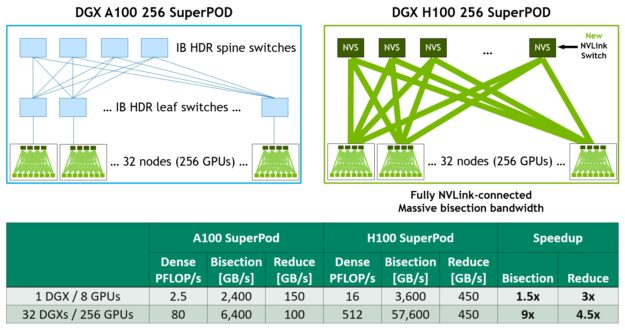
DGX H100 SuperPod 可以橫跨多達 256 個 GPU,使用以第三代 NVSwitch 技術為基礎的新型 NVLink Switch,透過 NVLink Switch System 完全連接。
採用 2:1 錐形胖樹拓撲的 NVLink Network 互連能將對分頻寬增加 9 倍,例如全部對全部交換,而 all-reduce 傳輸量則比上一代的 InfiniBand 系統增加 4.5 倍。DGX H100 SuperPOD 具有 NVLINK Switch System 選項。
PCIe Gen 5
H100 採用 PCI Express Gen 5 x16 通道介面,提供每秒 128 GB 的總頻寬(各方向每秒 64 GB),A100 中的 Gen 4 PCIe 的總頻寬則為每秒 64 GB(各方向每秒 32GB)。
H100 可以利用 PCIe Gen 5 介面與效能最高的 x86 CPU 和 SmartNIC,以及資料處理單元(data processing unit,DPU)介接。H100 能與 NVIDIA BlueField-3 DPU 建立最佳連線,以提供 400 Gb/s 乙太網路或 Next Data Rate(NDR)400 Gb/s InfiniBand 網路加速,確保安全的 HPC 和 AI 工作負載。
H100 增加了對原生 PCIe 原子操作的支援,例如為 32 和 64 位元資料類型增加原子 CAS、原子交換和原子擷取,並加快 CPU 與 GPU 之間的同步和原子操作。H100 也可以支援單根輸入/輸出虛擬化(SR-IOV),針對多個處理序或 VM,共用與虛擬化單一 PCIe 連接的 GPU。H100 允許來自與單一 SR-IOV PCIe 連接之 GPU 的虛擬功能(VF)或實體功能(PF),透過 NVLink 存取對等 GPU。
總結
欲深入瞭解提升應用程式效能的其他 H100 新功能和改良功能,請參閱 NVIDIA H100 Tensor 核心 GPU 架構白皮書。
致謝
我們想要感謝 Stephen Jones、Manindra Parhy、Atul Kalambur、Harry Petty、Joe DeLaere、Jack Choquette、Mark Hummel、Naveen Cherukuri、Brandon Bell、Jonah Alben,以及許多其他對本文章具有貢獻的 NVIDIA GPU 架構師和工程師。