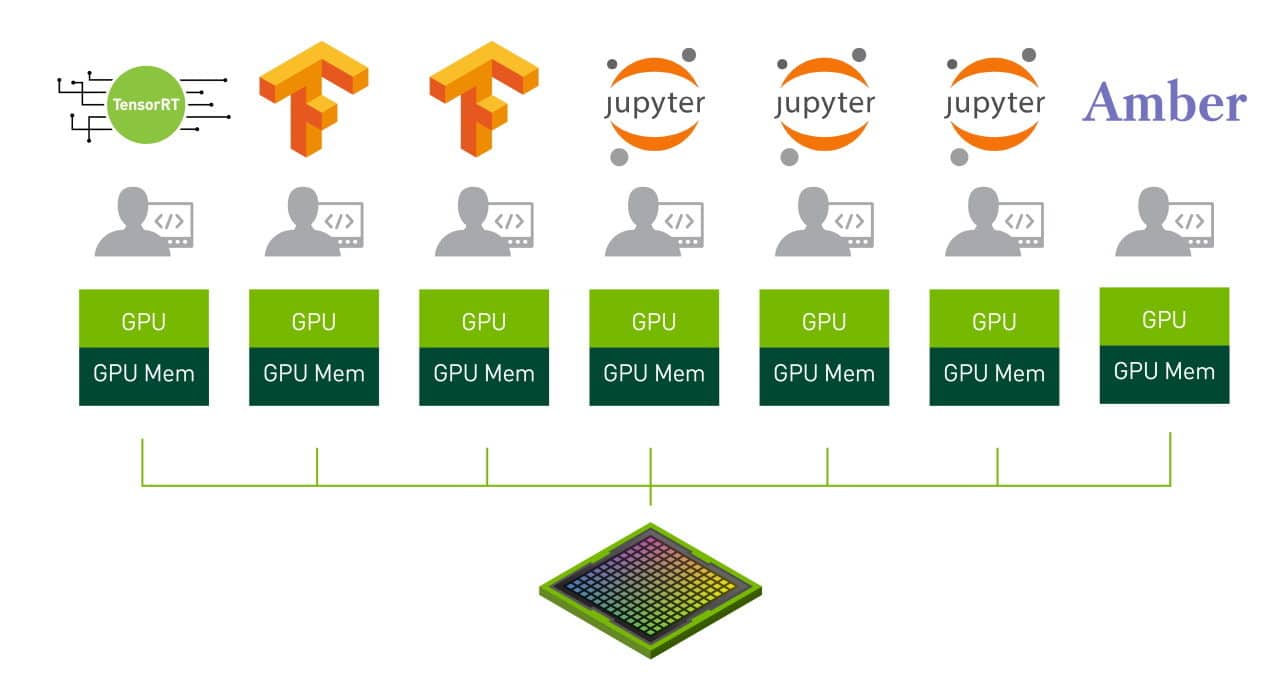
NVIDIA Ampere 架構中的 MIG 模式可以在 A100 GPU 上同時並行七個作業。
還記得夏日休息後在飲水機旁排長隊等待嗎?現在想像一下一個多頭的噴泉,所有人都能同時清涼一下。
這就是NVIDIA Ampere 架構中啟用的多執行個體 GPU 或 MIG 的本質。
MIG 將單個 NVIDIA A100 GPU 劃分為多達七個獨立的 GPU 執行個體。它們同時運行,每個都有自己的記憶體,快取和串流多處理器。與以前的 GPU 相比,這使 A100 GPU 能夠以高達 7 倍的利用率提供有保證的服務質量( QoS )。
在 MIG 模式下, A100 可以同時運行多達七個不同大小的 AI 或 HPC 工作負載。該功能對於通常不需要現代 GPU 提供的所有性能的 AI 推論作業特別有用。
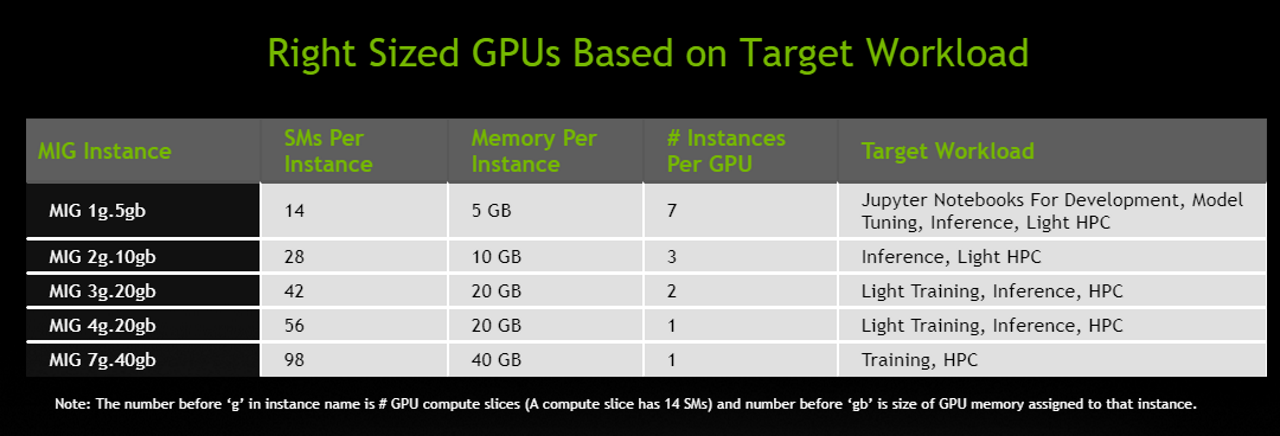
例如,用戶可以建立兩個每個具有 20 GB 記憶體的 MIG 執行個體,三個具有 10 GB 的執行個體或七個具有 5 GB 的執行個體。用戶可以建立適合自己工作負載的組合。
因為 MIG 隔離了 GPU 執行個體,所以它提供了故障隔離功能,一個執行個體中的問題不會影響在同一實體 GPU 上運行的其他執行個體。每個執行個體均提供有保證的 QoS ,以確保用戶的工作負載獲得預期的延遲和吞吐量。
雲端服務提供商和其他企業可以使用 MIG 來提高其 GPU 伺服器的利用率,從而為用戶提供多達 7 倍的 GPU 執行個體。
Google Cloud 首席軟體工程師 Tim Hockin 說“ NVIDIA 是 Google Cloud 的戰略合作夥伴,我們很高興他們代表客戶進行創新, MIG 使共享的 Kubernetes 叢集中的 GPU 效率和利用率達到新的水平。我們期待與 NVIDIA 和 Kubernetes 社區合作,以實現這些共享的 GPU 用例,並通過 Google Kubernetes Engine 使它們供大眾使用。”
企業在MIG上飛快進行推論
對於企業用戶, MIG 可以加快 AI 模型的開發和部署。
MIG 允許多達七名資料科學家同時存取專用的 GPU ,因此他們可以平行工作以微調深度學習模型,以獲得最佳的準確性和性能。這是一項耗時的工作,但通常不需要太多的計算能力,也就是說這是 MIG 的一個很好的案例。
一旦模型準備好運行, MIG 可使單個 GPU 一次處理多達七個推論作業。對於涉及小型,低延遲模型且不需要完整 GPU 的情況的批次 1 推論工作負載而言,這是理想的選擇。
“ NVIDIA 技術對於我們的交付機器人平台 Serve 至關重要,” Postmates 人工智慧總監郭振宇說。
他說:“ MIG 將使我們能夠充分利用我們部署的每個 GPU ,因為它使我們能夠動態地重新配置計算資源,以滿足不斷變化的工作負載需求,優化基於雲端的基礎架構,以實現最大的效率和成本節省。”
專為IT / DevOps設計
用戶無需更改 CUDA 編程模型即可獲得 MIG for AI 和 HPC 的好處。 MIG 可與現有的 Linux 操作系統以及 Kubernetes 和容器一起使用。
NVIDIA 為其 A100 提供了 MIG 的軟體。其中包括 GPU 驅動程式, NVIDIA 即將推出的CUDA 11軟體,更新的 NVIDIA 容器執行以及通過 NVIDIA 設備插件(NVIDIA Device Plugin)在 Kubernetes 中提供的新資源類型。
與 MIG 一起使用 NVIDIA 虛擬運算伺服器(vComputeServer),將可以管理和監視虛擬機管理程式的優勢,例如 Red Hat Virtualization 和 VMware vSphere 。該組合將支持流行的功能,例如即時遷移和多租戶。
“我們的客戶越來越需要管理在虛擬機上運行的多租戶工作流,同時提供隔離和安全優勢,”紅帽營銷總監 Chuck Dubuque 說。
他補充說:“ NVIDIA A100 GPU 上的新多執行個體 GPU 功能支持一系列新的 AI 加速工作負載,這些工作負載可以在 Red Hat 平台上從雲端到邊緣運行。”
有了 NVIDIA A100 及其軟體,用戶將能夠在其新 GPU 執行個體上查看和安排作業,就好像它們是實體 GPU 一樣。
去哪裡了解更多
要了解 MIG 在 A100 GPU 中的作用,請觀看 NVIDIA 創辦人暨執行長黃仁勳的主題演講。要了解更多訊息,請註冊MIG 網路研討會或閱讀詳細的文章,以深入了解NVIDIA Ampere 架構。
MIG 是 NVIDIA Ampere 架構中的一系列新功能之一,將 AI 訓練,推論和 HPC 性能推向了新的高度。有關更多詳細訊息,請參閱以下部落格:
- TensorFloat-32 (TF32)是一種加速格式,可加快 AI 訓練和某些 HPC 作業的速度,最高可達 20 倍。
- 雙精度 Tensor 內核(Double-Precision Tensor Cores),可將 HPC 模擬和 AI 速度提高至 2.5 倍。
- 支持稀疏性,讓 AI 推論的數學吞吐量提高 2 倍。
- 或者,請訪問我們的網站,介紹NVIDIA A100 GPU。