
搭載 NVIDIA 技術的系統在 MLPerf HPC 1.0 的五項測試中,有四項獨占鰲頭,MLPerf HPC 1.0 是用於衡量用於高效能運算領域之人工智慧效能的產業基準。
這是 MLPerf 的最新測試結果,MLPerf 是一套在 2018 年 5 月首次發布的深度學習產業基準。MLPerf HPC 提出了一種運算方式,用人工智慧加速及增強了超級電腦上的模擬作業。
在分子動力學、天文學及氣候模擬方面的最新進展,皆採用了「高效能運算+人工智慧」的模式,在科學研究上取得突破性進展。這項趨勢推動科學與工業領域的用戶採用 Exascale 等級的人工智慧。
這些基準在測量些什麼
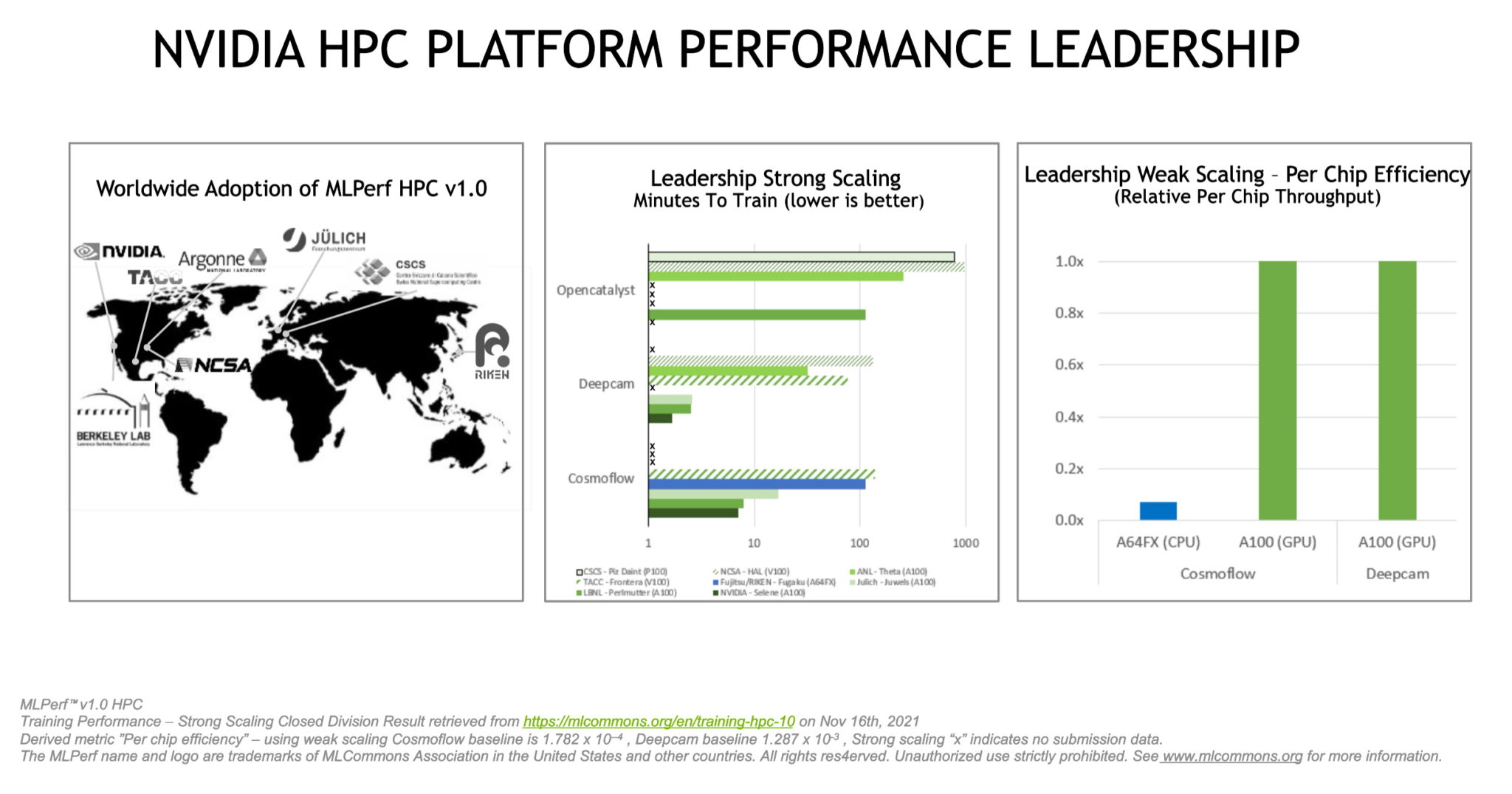
MLPerf HPC 1.0 使用高效能運算中心的三種典型工作負載,測量人工智慧模型的訓練結果。
- Cosmoflow 估計望遠鏡影像中的物體細節。
- Deepcam 測試偵測氣候資料中的颶風和大氣河流。
- Opencatalyst 追蹤系統對分子內原子之間作用力的預測程度。
每項測試分為兩個部分。衡量系統訓練模型的速度,稱為強縮放(strong scaling)。而與其對應的弱縮放(weak scaling),則是用於測量系統的最大處理量,即系統在特定時間內能訓練模型的數量。
與去年進行的 MLPerf 0.7 回合強縮放最佳結果相比,NVIDIA 在 cosmoflow 方面的表現進步五倍。在 deepcam 方面的表現更是進步七倍。
勞倫斯伯克利國家實驗室的 Perlmutter 超級電腦系統,搭載有 5120 個 NVIDIA A100 Tensor Core GPU,這次在 opencatalyst 基準測試中派出其中的 2048 個 GPU,於強縮放的測量結果方面領先群雄。
在 deepcam 的弱擴展類別中,我們使用16個節點來處理每項作業,同時要處理256個作業,最後勇奪這個類別的冠軍。我們在自家內部系統,也是全球最大的工業超級電腦 NVIDIA Selene(如上圖)上進行各項測試。
最新的測量結果展現出 NVIDIA 人工智慧平台的另一個維度,還有它領先業界的效能表現。這象徵著 NVIDIA 第八次在 MLPerf 基準測試中拿下最高分,這些測試涵蓋了資料中心、雲端和網路邊緣的人工智慧訓練與推論作業。
廣泛的商業生態體系
在這一回合測量活動中的八名參賽者,有七名用上了 NVIDIA 的 GPU。
這些單位包括德國的尤利希超級計算中心 (the Jülich Supercomputing Centre in Germany )、瑞士國家超級計算中心 (the Swiss National Supercomputing Centre),以及美國的阿貢(the Argonne and Lawrence Berkeley National Labs) 和勞倫斯伯克利國家實驗室 (the National Center for Supercomputing Applications、國家超級計算應用中心和德克薩斯先進計算中心 (the Texas Advanced Computing Center)。
尤利希超級計算中心主任 Thomas Lippert 在一篇部落格文章中寫道:「我們藉由這項基準測試,表現出這具超級電腦能夠徹底釋放潛力來處理各項實際運算作業,有助於歐洲保持在人工智慧方面的領先地位。」
MLPerf 基準獲得 MLCommons 的支持,這是一個由阿里巴巴、Google、Intel、Meta、NVIDIA 等公司所率領的產業組織。
我們怎麼做到的
一個包含完整軟體堆疊的成熟 NVIDIA 人工智慧平台,造就出如此優秀的表現。
我們在這一回合的測量活動中,利用大家都能拿到的工具來調整程式碼,像是使用 NVIDIA DALI 來加快處理資料;使用 CUDA Graph 來減少小批量的延遲,以有效地擴大到最多1024個以上的 GPU。我們還用上了 NVIDIA MagnumIO 裡的關鍵組件之一 NVIDIA SHARP,它提供了網路計算(In-Network Computing)功能,以加速通訊及將資料操作卸載到 NVIDIA Quantum InfiniBand 交換器網路。
可以從 MLPerf 資源庫中下載我們用於提交測試結果所使用的各款軟體。我們定期把這些程式碼加入 NGC 目錄,在這個軟體中心裡可以取得預先訓練的人工智慧模型、產業應用程式框架、GPU 應用程式及其它軟體資源。