此解決方案必須使用 DeepStream 5.1。
多攝影機應用程式已經越來越普及,它們對於啟用自主機器人、智慧影像分析(IVA)和 AR/VR 應用程式而言不可或缺。無論確切的使用案例為何,都必須執行一些常見任務:
- 擷取
- 預處理
- 編碼
- 顯示
在許多情況下,您會想要在攝影機資料流上部署 DNN,並在偵測上執行自訂邏輯。圖 1 為應用程式的常見流程。
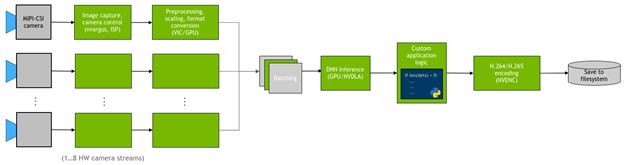
圖 1:在此專案中建置的工作流程
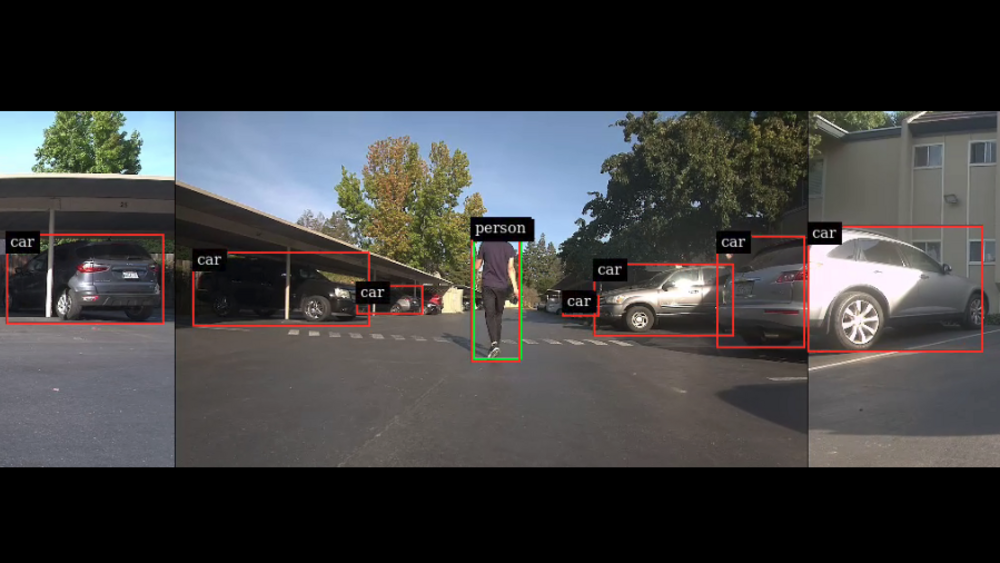
本文示範如何在 NVIDIA Jetson 平台上有效率地實現這些常見任務。具體而言,我將介紹 jetmulticam,一種可用於建立多攝影機管道,易於使用的 Python 套件。我在具有環繞攝影機系統的機器人上示範特定使用案例。最後,我加入了以 DNN 物件偵測為基礎的自訂邏輯(人體跟隨),取得以下影片所示的結果:
多攝影機硬體
在選擇攝影機時,需要考量許多參數:解析度、畫格率、光學、全域/捲簾快門、介面、像素大小。欲深入瞭解來自 NVIDIA 合作夥伴的相容攝影機,請參閱完整清單。
在此多攝影機配置中,使用下列硬體:
- NVIDIA Jetson Xavier NX 模組
- 具 GMSL2 功能的載板,來自於 Leopard Imaging
- 3 × IMX185 GMSL2 攝影機,來自於 Leopard Imaging
IMX185 攝影機各具有大約 90° 的視野。將它們以互成直角的方式安裝,以取得 270° 的總 FOV,如圖 2 所示。
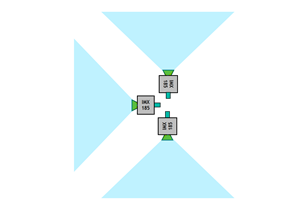
圖 2:安裝攝影機以最大化水平 FOV
攝影機採用的 GMSL 介面可提供極大的靈活性,甚至可以將攝影機放置於距離 Jetson 模組數公尺的位置。於此範例中,您可以將攝影機升高大約 0.5m,以取得更大的垂直 FOV。
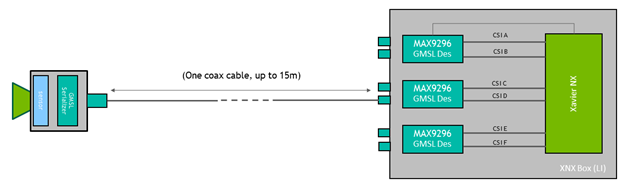
圖 3:GMSL 介面可以靈活地將攝影機放在遠離 Jetson 模組的位置
Jetmulticam 入門
首先,在 Jetson 機板上下載及安裝 NVIDIA Jetpack SDK。然後,安裝 jetmulticam 套件:
$ git clone https://github.com/NVIDIA-AI-IOT/jetson-multicamera-pipelines.git $ cd jetson-multicamera-pipelines $ bash scripts/install_dependencies.sh $ pip3 install Cython $ pip3 install .
基本多攝影機管道
在安裝之後,可以使用 CameraPipeline 類別建立基本管道。使用初始化器引數傳遞需要包含在管道中的攝影機清單。在以下範例中,元素 [0、1、2] 是對應裝置節點 /dev/video0、/dev/video1、/dev/video2。
from jetmulticam import CameraPipeline p = CameraPipeline([0, 1, 2])
完成管道已初始化及啟動。現在,您可以從管道中的每一部攝影機讀取影像,並以 numpy 陣列的形式進行存取。
img0 = p.read(0) # img0 is a np.array img1 = p.read(1) img2 = p.read(2)
通常,在迴圈中從攝影機讀取很方便,如以下程式碼範例所示。管道與主要執行緒非同步執行,且 read 一律取得最近的緩衝區。
while True: img0 = p.read(0) print(img0.shape) # >> (1920, 1080, 3) time.sleep(1/10)
更複雜的 AI 管道
現在,您可以建立更複雜的管道。此次是使用 CameraPipelineDNN 類別組成更複雜的管道,並使用來自於 NGC 目錄的兩個預先訓練模型:PeopleNet 和 DashCamNet。
import time from jetmulticam import CameraPipelineDNN from jetmulticam.models import PeopleNet, DashCamNet if __name__ == "__main__": pipeline = CameraPipelineDNN( cameras=[2, 5, 8], models=[ PeopleNet.DLA1, DashCamNet.DLA0, # PeopleNet.GPU ], save_video=True, save_video_folder="/home/nx/logs/videos", display=True, ) while pipeline.running(): arr = pipeline.images[0] # np.array with shape (1080, 1920, 3) dets = pipeline.detections[0] # Detections from the DNNs time.sleep(1/30)
以下是管道初始化的細項:
- 攝影機
- 模型
- 硬體加速
- 儲存影片
- 顯示影片
- 主要迴圈
攝影機
首先,與上一個範例類似,cameras 引數是感測器清單。於此範例中,是使用與裝置節點關聯的攝影機:
/dev/video2/dev/video5/dev/video8
cameras=[2, 5, 8]
模型
第二個引數 models,讓您可以定義在管道中執行的預先訓練模型。
models=[ PeopleNet.DLA1, DashCamNet.DLA0, # PeopleNet.GPU ],
部署來自於 NGC 的兩個預先訓練模型:
- PeopleNet:可以識別人、臉孔和包包的物件偵測模型。
- DashCamNet:可以識別以下四類物件的模型:汽車、人、道路標誌和自行車。
若需要更多資訊,請參閱 NGC 中的 模型卡。
硬體加速
模型是使用 NVIDIA Deep Learning Accelerator(DLA)即時執行。具體而言,是在 DLA0(DLA 核心 0)上部署 PeopleNet,在 DLA1 上部署 DashCamNet。
在兩個加速器之間分配模型,有助於提高管道的總傳輸量。此外,DLA 比 GPU 更省電。因此,系統採用最高時脈設定,在滿載下僅消耗大約 10W。最後,在此配置中,Jetson GPU 可以使用 Jetson NX 上的 384 個 CUDA 核心加快更多任務。
以下程式碼範例呈現出目前支援的模型/加速器組合清單。
pipeline = CameraPipelineDNN( # ... models=[ models.PeopleNet.DLA0, models.PeopleNet.DLA1, models.PeopleNet.GPU, models.DashCamNet.DLA0, models.DashCamNet.DLA1, models.DashCamNet.GPU ] # ... )
儲存影片
以下兩個引數可以指定是否儲存已編碼影片,並定義儲存的資料夾。
save_video=True, save_video_folder="/home/nx/logs/videos",
顯示影片
初始化的最後一步是配置管道,在螢幕上顯示視訊輸出以進行除錯。
display=True
主要迴圈
最後,定義主要迴圈。於執行階段期間,是在 pipeline.images 下提供影像,在 pipeline.detections 下提供偵測結果。
while pipeline.running(): arr = pipeline.images[0] # np.array with shape (1080, 1920, 3) dets = pipeline.detections[0] # Detections from the DNNs time.sleep(1/30)
偵測結果如以下程式碼範例所示。針對各項偵測,都會取得包含下列項目的字典:
- 物件類別
- 在像素座標中定義為 [left、width、top、height] 的物件位置
- 偵測信賴度
>>> pipeline.detections[0]
[
# ...
{
"class": "person",
"position": [1092.72 93.68 248.01 106.38], # L-W-T-H
"confidence": 0.91
},
#...
]
使用自訂邏輯延伸 AI 管道
在最後一步中可以延伸主要迴圈,以使用 DNN 輸出建構自訂邏輯。具體而言,使用來自於攝影機的偵測輸出,在機器人中建置基本的人體跟隨邏輯。原始碼是在 NVIDIA-AI-IOT/jetson-multicamera-pipelines GitHub 儲存庫中提供。
- 請解析 pipeline.detections 輸出,以尋找要跟隨的人。使用 find_closest_human 函式建置此邏輯。
- 在 dets2steer 中根據定界框的所在位置,計算機器人的轉向角度。
- 如果人在左側影像中,則向左轉到底。
- 如果人在右側影像中,則向右轉到底。
- 如果人在中間影像中,則依據比例轉動至定界框中心的 X 座標。
產生的影片是儲存至您在初始化過程中定義的 /home/nx/logs/videos。
解決方案概述
以下簡要介紹 jetmulticam 的運作方式。套件是使用應用程式需要的攝影機數量動態,建立和啟動 GStreamer 管道。圖 4 所示為基礎 GStreamer 管道在依據人體跟隨範例配置時的樣子。如您所見,系統中的所有關鍵操作(以綠色方塊表示)都因為硬體加速而受益。
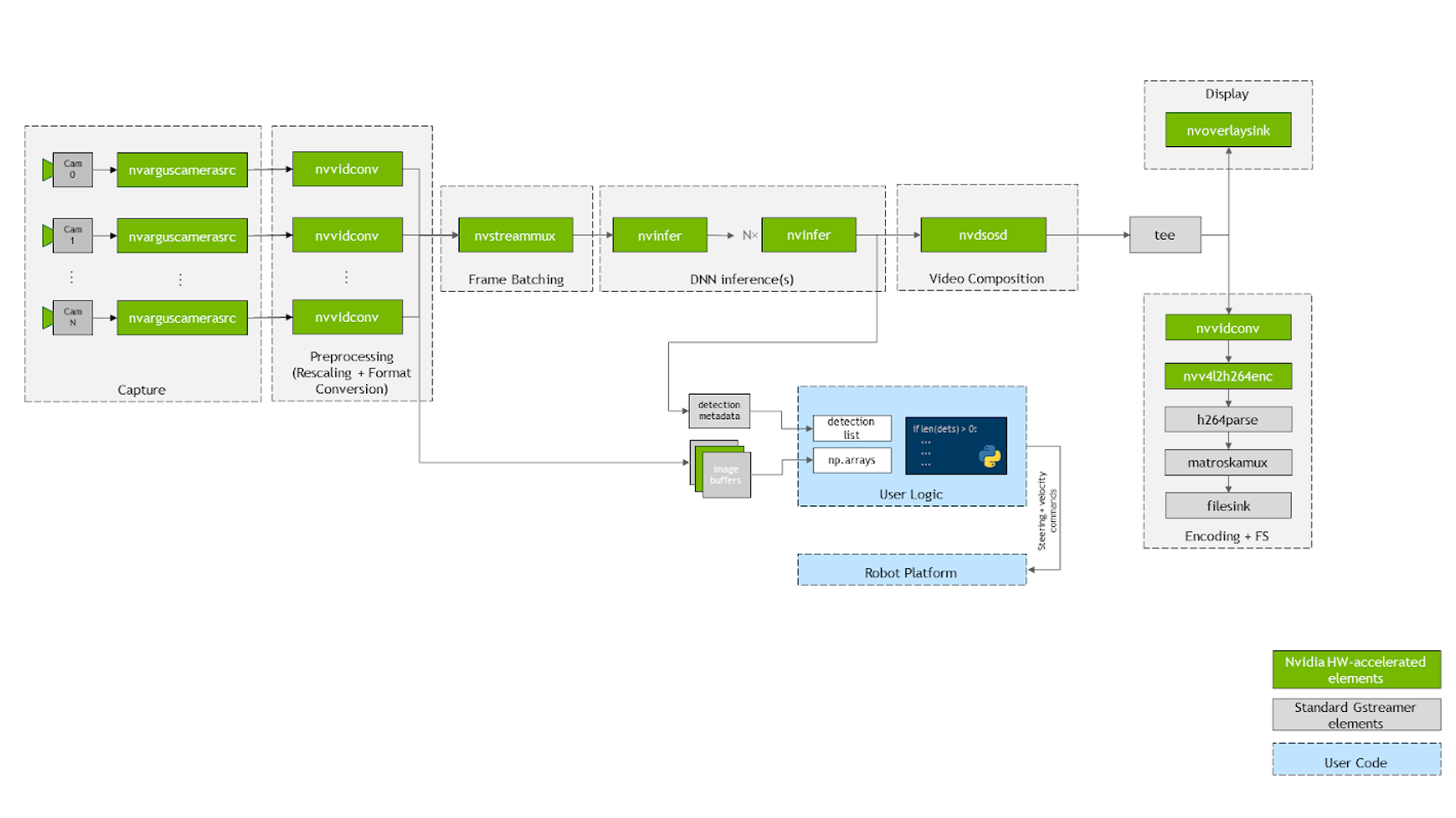
圖 4:jetmulticam套件的內部元件
首先,使用圖中的 nvarguscamerasrc 元素,以多個 CSI 攝影機拍攝影片。透過 nvvidconv 或 nvvideoconvert 重新調整個別緩衝區,並轉換成 RGBA 格式。之後使用 DeepStream SDK 提供的 component,針對畫格進行批次處理。在預設的情況下,批次大小等於系統中的攝影機數量。
在部署 DNN 模型時,請利用 nvinfer 元素。在示範中,我在兩個不同的加速器:DLA 核心 1 和 DLA 核心 2 上部署兩個模型:PeopleNet 和 DashCamNet,且兩者都可在 Jetson Xavier NX 上使用。但是,若有需要,甚至可以堆疊更多模型。
在產生的定界框被 nvosd 元素覆蓋之後,可以使用 nvoverlaysink 將它們顯示在 HDMI 顯示器上,並使用經過硬體加速的 H264 編碼器,將視訊資料流進行編碼。儲存至 .mkv 檔案。
回呼函式將 Python 程式碼中的影像(例如 pipeline.images[0])解析為 numpy 陣列,或登錄在各個視訊轉換器元素上的 probe。同樣地,另一個回呼函式是登錄在最後一個 nvinfer 元素的 sinkpad 上,將中繼資料解析為人性化偵測清單。若需要更多與原始碼或個別元件配置有關的資訊,請參閱 create_pipeline 函式。
結論
NVIDIA Jetson 平台提供的硬體加速與 NVIDIA SDK 結合,讓您可以實現出色的即時效能。例如,人體跟隨範例在三個攝影機資料流上即時執行兩個物件偵測神經網路,同時將 CPU 利用率維持在 20% 以下。
本文示範的 Jetmulticam 套件,讓您可以使用 Python 建構本身的硬體加速管道,並在偵測時加入自訂邏輯。