第四屆年度 Data Science Bowl,吸引逾 2,100 支隊伍同場較勁。
在開發打擊疾病的藥物之際,十億美元已經不像過去那麼好用。
不久前十億美元的金額或許還足以支付開發三十種新藥的成本,而如今這筆錢連開發一款新藥的費用也付不起。
今年的 Data Science Bowl 活動有助於解決研發藥物的痛苦。在這場全球最大的社會福祉人工智慧競賽裡,吸引了超過2,100個團隊致力於降低新藥研發成本與測試時間。
他們面臨的挑戰:使用深度學習來加快藥物研發流程關鍵步驟的速度和準確性,而這個關鍵步驟便是找出每個細胞的細胞核。
由麻省理工學院與哈佛大學共同創辦,也是這項賽事非營利合作夥伴的布洛德研究所(Broad Institute of MIT and Harvard)影像平台主任 Anne Carpenter 說:「更快、更準確地發展新的治療方法,這項極為現實的需求成為推動2018年 Data Science Bowl 賽事的動力。」
這句話有激發出你的好奇心嗎? 現在採取行動為時未晚,報名截止日期是4月9日,而最終提交日則為4月16日。
十萬美元的獎金,加上一部深度學習超級電腦
第四屆年度 Data Science Bowl 賽事邀請來自世界各地的參與者訓練深度學習模型,以研究細胞影像及找出細胞核。
顧問公司 Booz Allen Hamilton 的資料解決方案與機器智慧部門總監 Ray Hensberger 表示:「要是我們能改善這個流程,便會更快找出新的治療方法。」
Booz Allen 與 Kaggle 資料科學競賽平台共同主辦這項賽事,其它贊助者包括 NVIDIA、醫療診斷公司 PerkinElmer 等。除了推動研發藥物的速度,各優勝隊伍還將獲得總價值17萬美元的獎金和獎品,其中包括一台 NVIDIA DGX Station 個人人工智慧超級電腦工作站。
摩爾定律的另一面
開發新藥是一項複雜又艱鉅的任務,開發成本可能達到數十億美元,耗時十年甚至更長時間。根據 Eroom 定律(即將 Moore’s law 反過來拼寫)的觀察結果,就算開發技術有所增長,開發新藥的成本依舊大概每九年便成長一倍。
生物化學家嘗試通過數千種化合物,測量生病與健康細胞對各種療法的反應,以找出哪一種化合物對特定病毒或細菌有治療效果,或是哪一種化合物在人體裡會產生出預定的反應。
Carpenter 說幾乎所有的人類細胞都含有細胞核,辨識每個細胞最直接的方法就是找出細胞核。她說目前的影像處理演算法可以找出細胞核,並且測量細胞的生病狀態,在細胞核的形狀相當圓又不太擁擠時,測量的效果最好。
對組織樣本進行複雜實驗時,若細胞核呈現異常形狀或擁擠在一起時,這些演算法便派不上用場。
「有時候生物學家別無選擇,只能親自查看上千個影像來完成實驗。」Carpenter 說。她在以下影片裡介紹了 Data Science Bowl 在技術方面的其它細節:
深度學習藥物發現
現有方法也需要科學家配合各類影像和細胞,反復修改演算法。Carpenter 希望深度學習軟體能在生物學家不插手的情況下做到這一點,每年省下數十萬個小時,為研發新藥開闢更快速的管道。
她希望將獲勝的演算法用於建構研發藥物的深度學習軟體。
在 Carpenter 實驗室裡工作的博士後研究員 Kyle Karhohs 說:「深度學習有助於發現影像裡的相關細節,其能力足以媲美或超越人類的觀察能力。這或許能提高藥物發現的規模及速度,讓我們有更強大的能力,以前所未有的精準度找出影像裡的生物特徵。」
如要瞭解 Data Science Bowl 與類似的人工智慧競賽活動如何能為社會帶來益處,請參加3月26日至29日在矽谷舉行之 GPU 科技大會的「AI for Social Good as a Technology Driver」及其它會議。請立即報名。
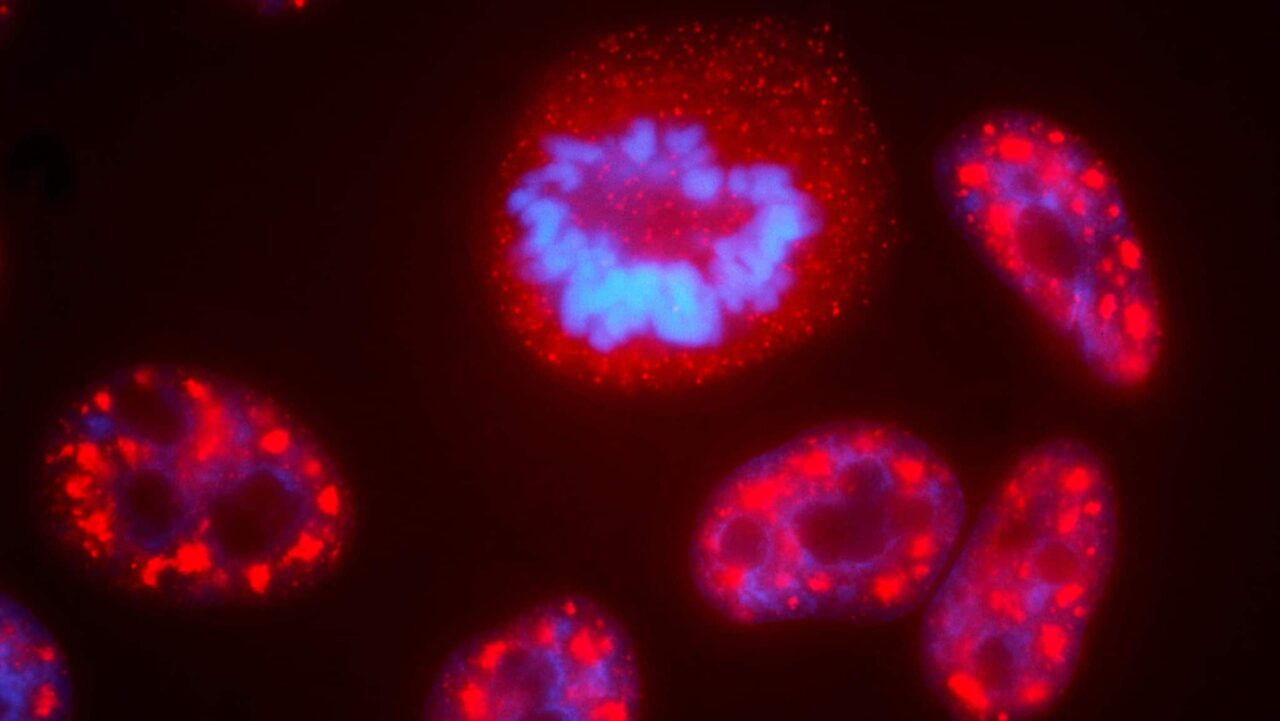
*本文的主要圖片顯示人類細胞核內部。圖片提供:國家癌症研究所的 Steve Mabon 與 Tom Misteli。