
巨量資料、新演算法和快速運算是使現代 AI 革命成為可能的三個主要因素。但是,資料為企業帶來了許多挑戰:資料標記困難、資料管理無效、資料可用性有限、資料私密性等。
以合成方式產生的資料,是解決這些挑戰可能的解決方案,因為是從模型取樣產生資料點。連續取樣可以產生無限數量的資料點,包括標籤。因此可以跨團隊或在外部共用資料。
產生合成資料也可以提供一定程度的資料私密性,且不會影響品質或真實性。產生成功的合成資料,必須在擷取分布的同時維持私密性及有條件地產生新資料,之後可以使用這些資料建立更穩健的模型或預測時間序列。
本文以 NVIDIA NeMo 為範例,說明如何使用 Transformer 模型,以人工方式產生合成資料。我們說明如何在機器學習演算法中使用以合成方式產生的資料有效替代真實生活資料,以保護使用者隱私,同時做出準確的預測。
Transformer:更佳的合成資料產生器
深度學習生成模型是將複雜的真實世界資料模型化的理想選擇。兩種熱門的生成模型皆已達成部分成就:變分自動編碼器(Variational Auto-Encoder,VAE)和生成對抗網路(Generative Adversarial Network,GAN)。
但是,在產生合成資料方面,VAE 和 GAN 模型存有已知的問題:
- GAN 模型中的模式崩潰問題,會導致產生之資料遺漏訓練資料分布中的某些模式。
- VAE 模型因為非自迴歸損失,而難以產生銳利的資料點。
Transformer 模型近期在自然語言處理(natural language processing,NLP)領域取得重大成就。經證實 Transformer 模型的自我注意力編碼和解碼架構可以準確建立資料分布模型,且可以擴充至更大的資料集。例如,NVIDIA Megatron-Turing NLG 模型是以 530B 個參數取得出色的結果。
GPT
OpenAI 的 GPT3 是使用 Transformer 模型的解碼器部分,且有 175B 個參數。GPT3 廣受眾多產業和領域採用,從生產力與教育,到創造力和遊戲。
經證實 GPT 模型是優異的生成模型。如您所知,根據機率鏈式法則,任何聯合機率分布都可以分解成一連串條件機率分布的產物。GPT 自迴歸損失直接將圖 1 所示的聯合機率分布模型化。
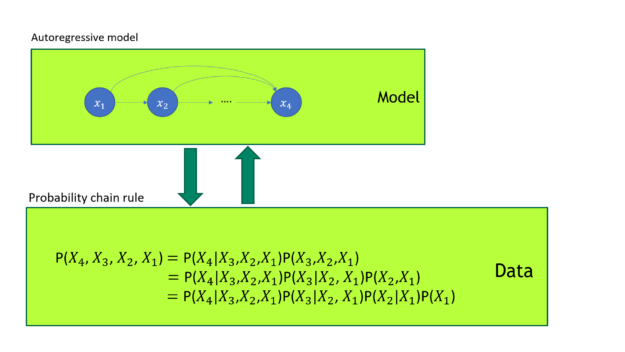
在圖 1 中,GPT 模型訓練使用自迴歸損失。它與機率鏈式法則形成一對一對映。GPT 直接將資料聯合機率分布模型化。
由於表格資料是由不同類型的資料行或資料列組成,因此 GPT 可以理解跨多個表格之行與列的聯合資料分布,並如同 NLP 文字資料一樣產生合成資料。我們的實驗顯示,GPT 模型確實可以產生更高品質的表格合成資料。
更高品質的表格資料標記器
雖然具有優越性,但是使用 GPT 將表格資料模型化仍具有一些挑戰:GPT 模型的資料輸入是標記 ID 序列。在 NLP 資料集方面,可以使用 byte-pair encoding(BPE)標記器,將文字資料轉換成標記 ID 序列。
在表格資料集方面,當然是使用通用的 GPT BPE 標記器,但是此方法存有一些問題。
首先,當 GPT BPE 標記器將表格資料分成標記時,不同行之同一列的標記數量通常不固定,因為數量是取決於個別子標記出現的頻率。表示如果使用一般 NLP 標記器,將會遺失表格中的直列資訊。
NLP 標記器的另一個問題是直列中的長字串,將由大量的標記組成。這是浪費的做法,因為 GPT 將標記序列模型化的能力有限。例如,商家名稱 Mitsui Engineering & Shipbuilding Co 需要 7 個標記,以使用 BPE 標記器進行編碼([44、896、9019、14044、1222、16656、16894、1766])。
如 TabFormer 論文所述,可行的解決方案是將表格的結構資訊納入考量,為表格資料建立專用的標記器。TabFormer 標記器是針對每一列使用單一標記,如果列的標記數量較小時,可能會導致準確度損失,如果標記數量太大,則可能會導致概化能力較弱。
我們是使用多個標記對列進行編碼,以進行改進。
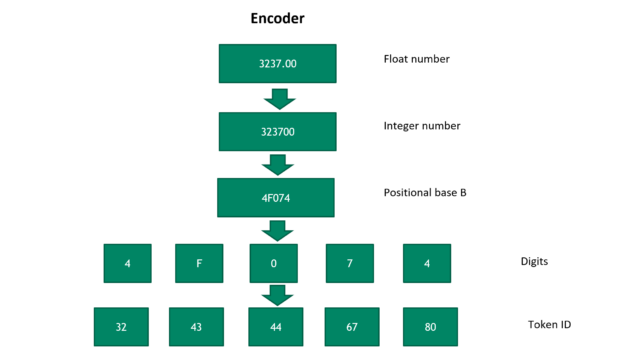
圖 2 所示為將浮點數轉換成標記 ID 序列的步驟。首先,我們採用可逆方式,將浮點數轉換成正整數。然後轉換成位置基數為 B 的數字,其中的 B 為超參數。基數 B 越大,表示該數字需要的標記越少。
但是,較大之基數 B 會犧牲新數字的概括性。在最後一步中,數字對映至唯一標記 ID。請依據相反順序執行這些步驟,以將標記 ID 轉換成浮點數。之後,依據標記數量和選擇的位置基數 B,決定浮點數解碼準確度。
使用 NeMo 框架擴充模型訓練
NeMo 是訓練對話式 AI 模型的框架。在 NeMo 儲存庫的已發布程式碼中,我們的表格資料標記器可以支援整數和類別資料、處理 NaN 值,並支援不同的純量轉換,以最小化數字之間的差距。若需要更多資訊,請參閱原始碼實作。
您可以使用特殊表格資料標記器,訓練任何大小的表格合成資料產生 GPT 模型。由於記憶體限制,可能難以訓練大型模型。NeMo Megatron 是 NeMo 中訓練大型語言模型,並提供張量模型平行和流程模型平行的工具套件。
使訓練具有數十億個參數的 Transformer 模型成為可能。除模型平行外,您也可以在訓練時應用資料平行,以充分利用叢集中的所有 GPU。根據 OpenAI 的自然語言比例法則和深度學習模型過度參數化理論,在將訓練資料大小納入考量下,建議訓練大型模型,以獲得合理的驗證損失。
將 GPT 模型應用在真實世界應用程式
在最近的 GTC 講座中,我們證明經過訓練的大型 GPT 模型可以產生高品質合成資料。如果我們繼續針對已訓練表格 GPT 模型進行取樣,則可以產生無限數量的資料點,這些資料點都是遵循聯合分布做為原始資料。產生的合成資料提供與原始資料相同的分析洞見,不會洩露個人的私密資訊。使安全的資料共用成為可能。
此外,如果根據過去資料調整生成模型,以產生未來合成資料,則該模型實際上是在預測未來。對於處理金融時間序列資料的金融服務業客戶極具吸引力。我們與 Cohen & Steers 合作建置表格 GPT 模型,以預測經濟和市場指標,包括通貨膨脹、波動率和股權市場,並提供高品質的結果。
Bloomberg 在 GTC 2022 上說明他們如何應用我們提出的合成資料方法,分析信用卡交易資料的模式,同時保護使用者資料的私密性。
應用知識
本文介紹使用 NeMo 產生合成表格資料的概念,並說明如何用於解決真實世界問題。若需要更多資訊,請參閱以資料為中心的 AI 運動。
如果有興趣將此技術應用在您的合成資料產生,請參考此 NeMo Megatron 合成表格資料產生 notebook 教學。若需要應用此方法產生合成資料的實作訓練,請直接與我們聯繫。