建立人工智慧(AI)應用程式時的主要挑戰和目標之一,是產生具有高效能和高準確度的穩健模型。建立此類深度學習模型是非常耗時的事。可能需要數週或數月的時間進行重新訓練、微調和最佳化,直至模型滿足必要條件。對許多開發人員而言,從零開始建立深度學習 AI 工作流程不是可行的選項,因此,我們建立了 NVIDIA NGC 目錄。
NGC 目錄是由 AI 和高效能運算(HPC)容器、預先訓練模型、SDK,以及 Helm chart 組成的 NVIDIA GPU 最佳化中心。其目的為簡化和加快端對端工作流程。
NGC 目錄同時包含豐富任務專用的預先訓練模型,適用於醫療、零售、製造等各種領域,以及電腦視覺、語音和語言理解等 AI 任務。本文章探討了使用來自 NGC 目錄之預先訓練模型的好處。之後,我們將會示範如何使用經過預先訓練的電腦視覺模型,建立手勢辨識 AI 應用程式。
為何使用預先訓練模型?
想要從零開始建立 AI 模型,通常需要大型的高品質資料集。在許多情況下,可能無法取用此類資料集,而必須自行取得資料或使用第三方資源。即使如此,資料也可能需要經過重組和訓練準備。此情形成為資料科學家的瓶頸,他們必須花費大量的時間標記、註解和轉換資料,而不是設計 AI 模型。
其他典型的開發步驟,包括從開放原始碼框架,建立深度學習模型、訓練、改進和多次重新訓練,以透過多次迭代達到需要的準確度。深度學習模型的規模和複雜性是另一項挑戰。過去五年期間,在運算資源方面的需求,增加了大約 30,000 倍,從五年前的 ResNet 50 到現在的 BERT-Megatron。想要處理如此龐大的模型,必須取用大規模叢集,以利用多節點系統提供的擴充性。
顧名思義,預先訓練模型是之前已在特定代表性資料集上經過訓練的模型。其包含針對該表示進行微調的權重和偏差。您可以使用預先訓練模型,將自訂模型初始化,以加快開發速度。通常有助於節省時間,且能執行更多的迭代,以改進模型。此技術為遷移學習(transfer learning)。
適用於各種使用案例和領域的預先訓練模型
NGC 目錄包含專用於汽車、醫療、製造、零售等產業的模型,同時可為下列使用案例提供模型:
- 偵測:SSD PyTorch
- 分類:ResNet50 v1.5、resnext101-32x4d
- 分割:MaskRCNN、UNET Industrial
- 自動語音辨識:Jasper
- 語音合成:FastPitch、TacoTron2、Waveglow
- 翻譯:GMNT、Transformer
- 語言模型建立:BERT、Electra
- 推薦系統:Wide and Deep、VAE
這些預先訓練模型,是由 NVIDIA 研究部門和 NVIDIA 合作夥伴直接開發。您可以直接將這些預先訓練模型整合至現有的產業 SDK 中,例如用於醫療的 NVIDIA Clara、用於對話式 AI 的 NVIDIA Riva、用於深度學習推薦系統的 NVIDIA Merlin,以及用於自動駕駛車的 NVIDIA DRIVE,以便能更快速地進入部署。
模型憑證
現在模型包含憑證,可以協助快速確認為 AI 軟體開發部署的適當模型。這些憑證提供模型的報告卡,顯示出訓練配置、效能指標及其他關鍵參數。此指標呈現出重要的超參數,例如模型準確度、期數、批次大小、精度、訓練資料集、傳輸量及其他重要維度,協助您確定模型的使用性,並放心部署。
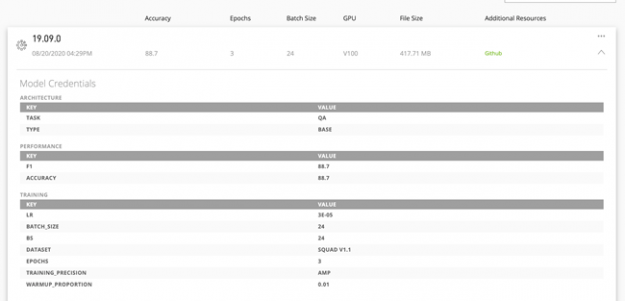
模型憑證讓您可以快速確認適當的模型,並在實際量產中更快地進行部署。計分卡指標可以自訂,以便使用對應的適當屬性,更佳地描述模型。例如,電腦視覺模型可以使用每秒影像數指標表示推論效能,而每秒句數則適合 NLP 模型。
遷移學習
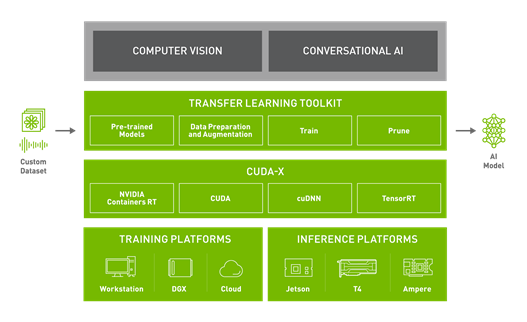
在選擇模型之後,可能需要針對不同的任務,使用自訂資料集進行訓練。NVIDIA TAO 工具套件是以 Python 為基礎的 AI 工具套件,讓您可以使用自己的資料,自訂專用的預先訓練 AI 模型。TAO 工具套件能使常見之網路架構和骨幹適應您的資料,以便您能訓練、微調、修剪和匯出高度最佳化與準確的 AI 模型,以進行邊緣端部署。TAO 工具套件是所有預先訓練模型的標準功能。請使用自己的資料,微調這些預先訓練模型。可以大幅加快模型開發時間,加快幅度將近 10 倍:從大約 80 週縮短至大約 8 週。
加速訓練效能
本節介紹預先訓練模型採用之關鍵技術的突破:自動混合精度和多 GPU 訓練。
自動混合精度
深度神經網路通常可以透過採用 FP16 和 FP32 精度的混合精度策略,進行訓練。將可大幅降低運算時間和記憶體頻寬的需求,同時維持模型的準確度。若需要更多資訊,請參閱 NVIDIA 研究部門的混合精度訓練論文。透過自動混合精度(automatic mixed precision,AMP)可以啟用混合精度,而無須變更程式碼或僅需要微幅變更。
AMP 是所有 NGC 模型的標準功能。它會自動使用 NVIDIA Volta、NVIDIA Turing 和 NVIDIA Ampere 架構上的 Tensor 核心。Tensor 核心可以將訓練加快 3 倍。
多 GPU 訓練
多 GPU 訓練是建置在所有 NGC 模型上的標準功能。其中的 Horovod 和 NCCL 函式庫,適用於分散式訓練和高效率通訊。對於大多數模型而言,在設定 GPU 數量之後,即可在多個同質 GPU 上進行多 GPU 訓練。
手勢辨識人工智慧應用程式
在此範例中是從預先訓練偵測模型開始,使用 TAO 工具套件 3.0 將用途改為手部偵測,並與專用的手勢辨識模型搭配使用。在訓練之後,將此模型部署在 NVIDIA Jetson 上。
設定環境
- Ubuntu 18.04 LTS
- python >=3.6.9 < 3.8.x
- docker-ce >= 19.03.5
- docker-API 1.40
- nvidia-container-toolkit >= 1.3.0-1
- nvidia-container-runtime >= 3.4.0-1
- nvidia-docker2 >= 2.5.0-1
- nvidia-driver >= 455.xx
您必須同時擁有 NGC 帳戶和 API 金鑰即可以免費使用。在註冊之後,開啟設定頁面,以取得更多說明。硬體需求,請參閱需求和安裝。
使用 virtualenv 和 virtualenvwrapper 設定 Python 環境:
pip3 install virtualenv pip3 install virtualenvwrapper
在殼層啟動檔案(.bashrc、.profile 等)中加入以下幾行,以設定虛擬環境的位置、開發專案目錄的位置,以及隨著該封裝一併安裝的指令碼位置:
export WORKON_HOME=$HOME/.virtualenvs export PROJECT_HOME=$HOME/Devel export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3 export VIRTUALENVWRAPPER_VIRTUALENV=/home/USER_NAME/.local/bin/virtualenv source ~/.local/bin/virtualenvwrapper.sh
建立虛擬環境:
mkvirtualenv tao_gesture_demo
啟動虛擬環境:
workon tao_gesture_demo
如果忘記 virtualenv 名稱,請輸入:workon。
若需要更多資訊,請參閱 virtualenvwrapper 5.0.1.dev2。
設定 TAO 工具套件 3.0
在 TAO 工具套件 3.0 中,我們已在容器上建立抽象層。請從啟動器啟動所有的訓練工作。無須手動提取對應的容器,因為 tao-launcher 會處理。您可以使用 pip 安裝啟動器,命令如下:
pip3 install nvidia-pyindex pip3 install nvidia-tao
同時必須安裝 Jupyter notebook 才能執行此示範。
pip install notebook
準備 EgoHands 資料集
為了訓練手部偵測模型,我們使用印第安納大學 IU 電腦視覺實驗室提供的公開取用資料集 EgoHands。EgoHands 包含 48 個不同的自我中心互動影像,其中具有 4,800 個畫格和 15,000 多隻手的像素層級基準真相註解。想要將此資料集與 TAO 工具套件搭配使用時,必須先轉換成 KITTI 格式。在此範例中,我們改寫了 JK Jung 的開放原始碼指令碼。
針對原始指令碼套用小幅變更,使其與 TAO 工具套件相容。在 function box_to_line(box) 行中,使用以下命令取代回傳陳述式,以移除分數元件:
return ' '.join(['hand',
'0',
'0',
'0',
'{} {} {} {}'.format(*box),
'0 0 0',
'0 0 0',
'0'])
想要轉換資料集,請下載 prepare_egohands.py 檔案,套用上述修改,設定正確路徑,然後依據此專案的 egohands_dataset/kitti_conversion.ipynb 中的指示操作。除呼叫原始轉換指令碼外,此 notebook 會依據 TAO 工具套件的要求,將資料集轉換成 training 和 testing 集合。
訓練偵測模型
我們在 TAO 工具套件 3.0 中提供多個 Jupyter notebook,示範各種模型的訓練工作流程。您可以在 gesture_recognition_tao_deepstream GitHub 儲存庫的 training_tao 目錄中,找到此示範的 notebook。
在啟動虛擬環境之後,請前往目錄,啟動 notebook,然後在瀏覽器中,依據 training_tao/handdetect_training.ipynb notebook 中的指示操作。
cd training_tao jupyter notebook
在透過 PeopleNet 初始化的 DetectNet V2 上執行 TAO 工具套件訓練
首先微調來自 NGC 目錄的預先訓練 PeopleNet 模型。PeopleNet 模型是經過訓練的 DetectNet V2 模型,可以辨識三類物件:人、包包和臉孔。在訓練之後,這些類別會被單一類別覆寫:手。我們選擇使用 PeopleNet 將模型初始化,因為手是屬於人類的元素,網路應該已經學習此類別的一些表示。
現在,DetectNet V2 可以支援從檢查點重新開始。如果過早終止訓練工作時,可以重新執行相同的命令,從最近的檢查點繼續訓練。在重新開始訓練時,請務必使用檢查點。
在訓練之後應評估模型,以檢查是否可以在準確度方面達到需要的效能。為此,TAO 工具套件提供了可以透過執行以下命令,在 notebook 中執行的評估工具:
!tao detectnet_v2 evaluate -e $SPECS_DIR/egohands_train_resnet34_kitti.txt\
-m $USER_EXPERIMENT_DIR/experiment_dir_unpruned_peoplenet/weights/resnet34_detector.tao \
-k $KEY
參數如下:
- 配置檔(與訓練時使用的檔案相同)
- 已訓練模型檔案
- 訓練時使用的唯一金鑰
修剪模型
在微調模型之後,請進行修剪,以建立更小的模型進行推論。修剪是指移除神經網路中不必要的連線,即無須執行對應的運算,進而可釋放記憶體及加快模型速度。
但是,修剪會損害模型的準確度。通常,僅需要調整準確度和模型大小取捨的閾值。較高的閾值產生的模型較小,但是準確度較低。使用的閾值視資料集而定。請選擇一些值做為起點。如果重新訓練的準確度良好,則可以提高此值,以獲得較小的模型。否則,請降低此值,以獲得更好的準確度。我們在一些內部研究中發現,在 DetectNet V2 模型方面,0.01 的閾值是很好的起點。
# Create an output directory if it doesn't exist.
!mkdir -p $LOCAL_EXPERIMENT_DIR/experiment_dir_pruned
!tao detectnet_v2 prune \
-m $USER_EXPERIMENT_DIR/experiment_dir_unpruned_peoplenet/weights/resnet34_detector.tao \
-o $USER_EXPERIMENT_DIR/experiment_dir_pruned/resnet34_nopool_bn_detectnet_v2_pruned.tao \
-eq union \
-pth 0.0000052 \
-k $KEY
在修剪之後必須重新訓練模型,以恢復準確度。應使用預先訓練權重建立重新訓練規格,做為已修剪模型。
在載入已修剪模型圖,以進行重新訓練時,請將 model_config 中的 load_graph 選項設為「true」,並載入已修剪模型圖。在重新訓練之後,如果模型的 mAP 下降,可能是因為最初訓練的模型過度修剪而造成。您可以降低修剪閾值和修剪比例,然後使用新模型進行重新訓練。
現在,DetectNet V2 可以支援量化感知訓練(quantization aware training,QAT),進一步將模型最佳化。此步驟通常是在修剪後的重新訓練期間執行。
使用 QAT 在修剪後重新訓練
所有未修剪和已修剪 DetectNet 模型都可以轉換成 QAT 模型,方式是將規格檔案之 training_config 元件中的 enable_qat 參數設為「true」。
!tao detectnet_v2 train -e $SPECS_DIR/egohands_retrain_resnet34_kitti_qat.txt \ -r $USER_EXPERIMENT_DIR/experiment_dir_retrain_qat \
-k $KEY \
-n resnet34_detector_pruned_qat \
--gpus $NUM_GPUS
評估經過 QAT 轉換的模型
本節評估啟用 QAT、經過修剪和重新訓練的模型。此模型的 mAP 與無 QAT 的已修剪重新訓練模型應相當。但是,因為量化,有時候可能會看到某些資料集的 mAP 值下降。想要評估新模型,請在 notebook 中執行以下命令:
!tao detectnet_v2 evaluate -e $SPECS_DIR/egohands_retrain_resnet34_kitti_qat.txt \ -m $USER_EXPERIMENT_DIR/experiment_dir_retrain_qat/weights/resnet34_detector_pruned_qat.tao \
-k $KEY \
-f tao
從 NGC 目錄取得手勢辨識模型
在此應用程式方面,請使用與來自 NGC 之手勢辨識模型 GestureNet 串聯的已訓練手部偵測模型。您可以使用 wget 方法,從 NGC 目錄下載 GestureNet 模型:
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/tao_gesturenet/versions/deployable_v1.0/zip -O tao_gesturenet_deployable_v1.0.zip
或者,您可以使用 CLI 命令:
ngc registry model download-version "nvidia/tao_gesturenet:deployable_v1.0"
由於不重新訓練此模型,並直接用於部署,請選擇 deployable_v1.0 版本。
使用 DeepStream SDK 在 NVIDIA Jetson 上部署
現在已微調偵測網路,並已下載手勢辨識模型,之後將這些模型部署在目標邊緣裝置 Jetson 上。本節將示範如何使用適合影像分析應用程式的多平台可擴充框架 DeepStream SDK 部署模型。
先決條件
這些先決條件專門針對 Jetson 部署。想要重新使用此解決方案,在獨立 GPU 上執行,請參閱 DeepStream 入門。
- CUDA 10.2
- cuDNN 8.0.0
- TensorRT 7.1.0
- JetPack >= 4.4
如果您的 JetPack 版本未安裝 DeepStream SDK 時,請依據 DeepStream 快速入門指南中的 Jetson 安裝說明操作。
準備部署模型
使用 DeepStream SDK 部署模型的方式有兩種。第一種方式是仰賴 TensorRT 執行階段,必須將模型轉換成 TensorRT 引擎。第二種方式是仰賴 Triton 推論伺服器。Triton 推論伺服器是可以做為獨立解決方案的伺服器,但是,也可以整合至 DeepStream 應用程式中使用。此設定具有高靈活性,因為可以接受各種格式的模型,而無須轉換成 TensorRT 格式。本文章中示範了兩種類型,使用 TensorRT 執行階段,以及 Triton 推論伺服器分別部署手部偵測器和手勢辨識模型。
想要使用 TensorRT 執行階段,將模型部署至 DeepStream 時,請確定模型可以轉換成 TensorRT。TensorRT 應該可以支援模型中的所有層和運算。欲深入瞭解支援的層和運算,請參閱 TensorRT 支援表。
將模型轉換成 TensorRT
想要在目標邊緣裝置上利用硬體和軟體加速,必須將 .etao 模型轉換成 NVIDIA TensorRT 引擎。TensorRT 是適用於高效能深度學習推論的 SDK。其包含深度推論最佳化工具和執行階段,可以為深度學習推論應用程式提供低延遲和高傳輸量。
將模型轉換成 TensorRT 引擎的方式有兩種。您可以直接使用 DeepStream,或使用 tao-converter 公用程式。我們示範了兩種方式。
在初次執行時,DeepStream 會自動轉換已訓練偵測器模型。在後續執行時,可以在對應的 DeepStream 配置中指定產生引擎的路徑。我們將會一併提供 DeepStream 配置與此專案。
由於 GestureNet 模型比較新,此示範使用的 DeepStream 5.0 版不支援轉換。但是,您可以使用更新後的 tao-converter 進行轉換。想要下載時,請選擇 JetPack 版本:
欲深入瞭解如何將 tao-converter 與不同的硬體和軟體搭配使用,請參閱 TAO 工具套件入門。
在 Jetson 上安裝 tao-converter 之後,使用以下命令轉換 GestureNet 模型:
./tao-converter -k nvidia_tao \
-t fp16 \
-p input_1,1x3x160x160,1x3x160x160,2x3x160x160 \
-e /EXPORT/PATH/model.plan \
/PATH/TO/YOUR/GESTURENET/model.etao
由於未變更模型,並依據原樣使用,因此模型金鑰與 NGC 上指定的金鑰相同,没有改變 (nvidia_tao)。
將模型轉換成 FP16 格式,因為可部署模型沒有任何 INT8 校正檔案。務必為模型路徑和匯出路徑提供正確的值。
確保為 Triton 推論伺服器配置 GestureNet
想要使用 Triton 推論伺服器部署模型時,請準備採用指定格式的模型儲存庫。應具有以下結構:
└── trtis_model_repo
└── hcgesture_tao
├── 1
│ └── model.plan
└── config.pbtxt
在此結構中,model.plan 是透過 trt-converter 產生 .plan 檔案,config.pbtxt 的內容如下:
name: "hcgesture_tao"
platform: "tensorrt_plan"
max_batch_size: 1
input [
{
name: "input_1"
data_type: TYPE_FP32
dims: [ 3, 160, 160 ]
}
]
output [
{
name: "activation_18"
data_type: TYPE_FP32
dims: [ 6 ]
}
]
dynamic_batching { }
欲深入瞭解如何配置 Triton 推論伺服器儲存庫,請參閱模型儲存庫。
自訂 deepstream-app
您可以靈活地配置範例 deepstream-app:做為主要偵測器、分類器,甚至串聯多個模型,例如偵測器和分類器。於此情況下,偵測器會將裁切後的目標物件,傳遞至分類器。此過程是發生於 DeepStream 工作流程中,其中每一個元件都利用 Jetson 裝置中的硬體元件。
圖 5 所示為應用程式工作流程。
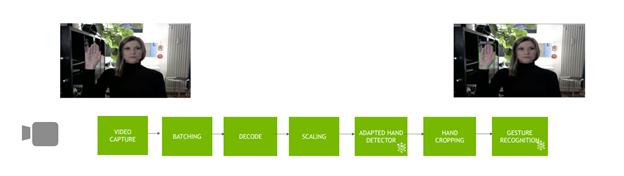
本文章中使用的 GestureNet 模型,會在目標區域(region of interest,ROI)周圍具有較大邊界的影像上訓練。同時,經過訓練的偵測器模型會在目標物件(於此範例中為手部)周圍產生窄框。首先,會導致傳遞至分類器的物件與分類器學習的表示不同。解決此問題的方式有兩種:
- 使用反映設定的新資料集進行重新訓練。
- 將裁切後的 ROI 延伸一些適合的邊界。
由於我們想要依據原樣使用 GestureNet 模型,因此選擇第二種方式,必須修改原始應用程式。
想要修改偵測器回傳的中繼資料,以裁切更大的定界框時,請執行以下函式:
#define CLIP(a,min,max) (MAX(MIN(a, max), min))
int MARGIN = 200;
static void
modify_meta (GstBuffer * buf, AppCtx * appCtx)
{
int frame_width;
int frame_height;
get_frame_width_and_height(&frame_width, &frame_height, buf);
NvDsBatchMeta *batch_meta = gst_buffer_get_nvds_batch_meta (buf);
NvDsFrameMetaList *frame_meta_list = batch_meta->frame_meta_list;
NvDsObjectMeta *object_meta;
NvDsFrameMeta *frame_meta;
NvDsObjectMetaList *obj_meta_list;
while (frame_meta_list != NULL) {
frame_meta = (NvDsFrameMeta *) frame_meta_list->data;
obj_meta_list = frame_meta->obj_meta_list;
while (obj_meta_list != NULL) {
object_meta = (NvDsObjectMeta *) obj_meta_list->data;
object_meta->rect_params.left = CLIP(object_meta->rect_params.left - MARGIN, 0, frame_width - 1);
object_meta->rect_params.top = CLIP(object_meta->rect_params.top - MARGIN, 0, frame_height - 1);
object_meta->rect_params.width = CLIP(object_meta->rect_params.left + object_meta->rect_params.width + MARGIN, 0, frame_width - 1);
object_meta->rect_params.height = CLIP(object_meta->rect_params.top + object_meta->rect_params.height + MARGIN, 0, frame_height - 1);
obj_meta_list = obj_meta_list->next;
}
frame_meta_list = frame_meta_list->next;
}
}
想要顯示原始定界框時,請執行以下函式,將中繼定界框恢復成原始大小:
static void
restore_meta (GstBuffer * buf, AppCtx * appCtx)
{
int frame_width;
int frame_height;
get_frame_width_and_height(&frame_width, &frame_height, buf);
NvDsBatchMeta *batch_meta = gst_buffer_get_nvds_batch_meta (buf);
NvDsFrameMetaList *frame_meta_list = batch_meta->frame_meta_list;
NvDsObjectMeta *object_meta;
NvDsFrameMeta *frame_meta;
NvDsObjectMetaList *obj_meta_list;
while (frame_meta_list != NULL) {
frame_meta = (NvDsFrameMeta *) frame_meta_list->data;
obj_meta_list = frame_meta->obj_meta_list;
while (obj_meta_list != NULL) {
object_meta = (NvDsObjectMeta *) obj_meta_list->data;
// reduce the bounding boxes for output (copy the reserve value from detector_bbox_info)
object_meta->rect_params.left = object_meta->detector_bbox_info.org_bbox_coords.left;
object_meta->rect_params.top = object_meta->detector_bbox_info.org_bbox_coords.top;
object_meta->rect_params.width = object_meta->detector_bbox_info.org_bbox_coords.width;
object_meta->rect_params.height = object_meta->detector_bbox_info.org_bbox_coords.height;
obj_meta_list = obj_meta_list->next;
}
frame_meta_list = frame_meta_list->next;
}
此外,請執行此輔助函式,從緩衝區取得畫格寬度和高度。
static void
get_frame_width_and_height (int * frame_width, int * frame_height, GstBuffer * buf) {
GstMapInfo map_info;
memset(&map_info, 0, sizeof(map_info));
if (!gst_buffer_map (buf, &map_info, GST_MAP_READ)){
g_print("Error: Failed to map GST buffer");
} else {
NvBufSurface *surface = NULL;
surface = (NvBufSurface *) map_info.data;
*frame_width = surface->surfaceList[0].width;
*frame_height = surface->surfaceList[0].height;
gst_buffer_unmap(buf, &map_info);
}
}
建構應用程式
想要建構自訂應用程式時,請將 deployment_deepstream/deepstream-app-bbox 複製到 /opt/nvidia/deepstream/deepstream-5.0/sources/apps/sample_apps。
安裝需要的相依性:
sudo apt-get install libgstreamer-plugins-base1.0-dev libgstreamer1.0-dev \ libgstrtspserver-1.0-dev libx11-dev libjson-glib-dev
建立可執行檔:
cd /opt/nvidia/deepstream/deepstream-5.0/sources/apps/sample_apps/deepstream-app-bbox make
配置 DeepStream 工作流程
在執行應用程式之前,必須提供配置檔。若需要更多與配置參數有關的資訊,請參閱應用程式架構。您可以在 deployment_deepstream/egohands-deepstream-app-trtis/ 下,找到此示範的配置檔。在同一個目錄中,同時可以找到模型需要的標籤檔案。
最後,必須將應用程式設為可供模型探索。根據配置,儲存模型之 deployment_deepstream/egohands-deepstream-app-trtis/ 下的目錄結構,如下所示:
├── tao_models
│ ├── tao_egohands_qat
│ │ ├── calibration_qat.bin
│ │ └── resnet34_detector_qat.etao
└── trtis_model_repo
└── hcgesture_tao
├── 1
│ └── model.plan
└── config.pbtxt
您可能會發現目前的設定,缺少在配置 config_infer_primary_peoplenet_qat.txt 中指定的檔案 resnet34_detector_qat.etao_b16_gpu0_int8.engine。它會在初次執行時產生,並會直接使用於後續執行。
執行應用程式
一般而言,執行命令如下所示:
./deepstream-app-bbox -c
於此範例中是使用提供的配置,命令如下所示:
./deepstream-app-bbox -c source1_primary_detector_qat.txt
現在應用程式應正常執行。
總結
本文章示範了如何透過來自 NGC 目錄的預先訓練模型,使用 DeepStream SDK 微調、最佳化和部署手勢辨識應用程式。
除此範例使用的 PeopleNet 和 GestureNet 模型外,在 NGC 目錄中也可以找到其他使用案例的模型,例如對話式 AI、語音和語言理解。 若需要更多資訊,請參閱以下資源: