
人類每天都會到處行動或做各種動作,例如行走、跑步和坐下等。這些動作是日常生活的自然延伸。建立擷取這些特定動作的應用程式,在分析運動領域、協助醫療業確保患者安全、協助零售業改善購物體驗等方面,可能具有極大的價值。 但是,要建立與部署可理解人類動作的人工智慧(AI)應用程式,則既困難又耗時,且一般需要大量的訓練和深厚的 AI 專業知識。 本文將說明如何取得經預先訓練的動作辨識模型,使用 NVIDIA TAO 工具套件,透過自訂資料和類別進行微調,並透過 NVIDIA DeepStream 部署進行推論,加速開發 AI 應用程式,而無須具備任何 AI 專業知識。
動作辨識模型
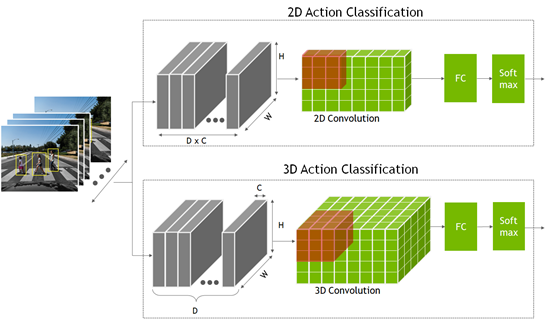
在辨識動作時,神經網路必須查看多個連續畫格,而不是僅查看單一靜態畫格。可以提供時間脈絡,以理解動作。相較於網路僅查看單一靜態畫格的分類或物件偵測模型,這是額外的時間維度。
這些模型是使用 2D 卷積神經網路進行建立,其中的維度是寬度、高度和通道數量。2D 動作辨識模型與其他的 2D 電腦視覺模型類似,但是現在的通道維度已包含時間資訊。
- 在 2D 動作辨識模型中,將時間畫格 D 乘以通道計數 C 以形成通道維度輸入。
- 在 3D 模型方面,增加了表示時間資訊的新維度 D。
從 2D 與 3D 卷積網路的輸出,進入一個全連接層,之後進入 Softmax 層,以預測動作。
預先訓練模型是一種已在代表性資料集上經過訓練,並透過權重和偏差進行微調的模型。NGC 目錄提供的動作辨識模型,已針對五個常見類別進行訓練:
- 行走
- 跑步
- 推動
- 騎自行車
- 跌落
這是一個範例模型。更重要的是之後可以使用自訂資料,輕鬆地重新訓練此模型,僅需要從零開始訓練之時間和資料的一小部分。 這個預先訓練模型是在 HMDB51 資料集的數百支短片上進行訓練。在訓練模型的五個類別方面,2D 模型的準確率達到 83%,3D 模型的準確率達到 86%。此外,如果選擇依據原樣部署模型時,不同 GPU 上的預期效能如下表所示。
| 推論效能 (FPS) | 2D ResNet18 | 3D ResNet18 |
| Nano | 30 | 0.6 |
| NVIDIA Xavier NX | 250 | 5 |
| NVIDIA AGX Xavier | 490 | 33 |
| NVIDIA A30 | 5,809 | 356 |
| NVIDIA A100 | 10,457 | 640 |
在此實驗中,模型是透過由伏地挺身、仰臥起坐、引體向上等簡單之動作組成的三個新類別進行微調。使用 HMDB51 資料集的子集,包含了 51 種不同的動作。
先決條件
在開始之前必須具備下列資源,才能進行訓練和部署:
-
- NVIDIA GPU 驅動程式版本:>470
- NVIDIA Docker:5.0-1
- 雲端或內部部署 NVIDIA GPU:
- NVIDIA A100
- NVIDIA V100
- NVIDIA T4
- NVIDIA RTX 30×0
- NVIDIA TAO 工具套件:3.0-21-11
- NVIDIA DeepStream:6.0
若需要更多資訊,請參閱 TAO 工具套件快速入門指南。
使用 TAO 工具套件進行訓練、調整和最佳化
在本節中,模型是使用 TAO 工具套件,透過新類別進行微調。
TAO 工具套件是使用遷移學習,將從現有之神經網路模型中學到的功能,應用在新模型上。TAO 工具套件是以 CLI 和 Jupyter notebook 為基礎的 NVIDIA TAO 框架解決方案,無須具備任何 AI 專業知識,即可為使用案例建立自訂和生產就緒模型。
您可以在 CLI 視窗中提供簡單的指令或使用統包式 Jupyter notebook,進行訓練和微調。並使用來自 NGC 的動作辨識 notebook 來訓練自訂的三類別模型。
請下載 TAO 工具套件電腦視覺範例工作流程 1.3 版,並將封裝解壓縮。在 /action_recognition_net 目錄中,找出用於動作辨識訓練的 Jupyter notebook(actionrecognitionnet.ipynb),以及 /specs 目錄,包含訓練、評估和模型匯出的所有規格檔案。配置這些規格檔案以進行訓練。
啟動 Jupyter notebook,並開啟 action_recognition_net/actionrecognitionnet.ipynb 檔案:
jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root
步驟 1:設定與安裝 TAO 工具套件
在 Jupyter notebook 中執行所有的訓練步驟。在啟動 notebook 之後,執行 notebook 中提供的 Set up env variables and map drives 和 Install TAO launcher 步驟。
步驟 2:下載資料集和預先訓練模型
在安裝 TAO 之後,下一步是下載及準備進行訓練的資料集。Jupyter notebook 提供了下載和預處理 HMDB51 資料集的步驟。如果已具備自訂資料集,則可以在步驟 2.1 中使用。
在本文中,是使用來自 HMDB51 資料集的三個類別。修改幾行以新增伏地挺身、引體向上和仰臥起坐類別。
$ wget -P $HOST_DATA_DIR http://serre-lab.clps.brown.edu/wp-content/uploads/2013/10/hmdb51_org.rar $ mkdir -p $HOST_DATA_DIR/videos && unrar x $HOST_DATA_DIR/hmdb51_org.rar $HOST_DATA_DIR/videos $ mkdir -p $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/pushup.rar $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/pullup.rar $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/situp.rar $HOST_DATA_DIR/raw_data
各類別的影片檔案是儲存在 $HOST_DATA_DIR/raw_data 下各自的目錄中。這些是經過編碼的影片檔案,必須解壓縮成畫格才能訓練模型。已提供指令碼,協助您準備進行訓練的資料。
下載輔助函式指令碼及安裝相依性:
$ git clone https://github.com/NVIDIA-AI-IOT/tao_toolkit_recipes.git $ pip3 install xmltodict opencv-python
將影片檔案解壓縮成畫格:
$ cd tao_recipes/tao_action_recognition/data_generation/ $ ./preprocess_HMDB_RGB.sh $HOST_DATA_DIR/raw_data \ $HOST_DATA_DIR/processed_data
各類別之輸出,如以下程式碼範例所示。f cnt:82 表示該影片已解壓縮成 82 個畫格。針對目錄中的所有影片執行此操作。視類別數量以及資料集和影片大小而定,此過程可能需要一些時間。
Preprocess pullup f cnt: 82.0 f cnt: 82.0 f cnt: 82.0 f cnt: 71.0 ...
已處理資料的格式,如以下程式碼範例所示。如果在自己的資料上訓練時,請確保資料集符合此目錄格式。
$HOST_DATA_DIR/processed_data/ |--> |--> |--> rgb |--> 000001.png |--> 000002.png |--> 000003.png …
下一步是將資料分割成訓練和驗證集。HMDB51 資料集可為各類別提供分割檔案,因此僅需要下載該檔案,並將資料集分成 70% 的訓練和 30% 的驗證即可。
$ wget -P $HOST_DATA_DIR http://serre-lab.clps.brown.edu/wp-content/uploads/2013/10/test_train_splits.rar $ mkdir -p $HOST_DATA_DIR/splits && unrar x \ $HOST_DATA_DIR/test_train_splits.rar $HOST_DATA_DIR/splits
使用輔助函式指令碼 split_dataset.py 分割資料。僅適用於 HMDB 資料集隨附的分割檔案。如果是使用自己的資料集,則不適用。
$ cd tao_recipes/tao_action_recognition/data_generation/ $ python3 ./split_dataset.py $HOST_DATA_DIR/processed_data \ $HOST_DATA_DIR/splits/testTrainMulti_7030_splits $HOST_DATA_DIR/train \ $HOST_DATA_DIR/test
用於訓練的資料在 $HOST_DATA_DIR/train 下,用於測試和驗證的資料在 $HOST_DATA_DIR/test 下。
在備妥資料集之後,從 NGC 下載預先訓練模型。依據 Jupyter notebook 2.1 中的步驟操作。
$ ngc registry model download-version "nvidia/tao/actionrecognitionnet:trainable_v1.0" --dest $HOST_RESULTS_DIR/pretrained
步驟 3:配置訓練參數
規格 YAML 檔案中提供了訓練參數。在 /specs 目錄中,找出所有用於訓練、微調、評估、推論和匯出的規格檔案。在訓練時,使用 train_rgb_3d_finetune.yaml。
針對此實驗,我們示範了一些可以修改的超參數。欲深入瞭解各種參數,請參閱 ActionRecognitionNet。
您也可以在執行階段期間覆寫任何參數。大多數的參數都會保留預設值。在以下程式碼區塊中會醒目提示變更的部分。
## Model Configuration
model_config:
model_type: rgb
input_type: "3d"
backbone: resnet18
rgb_seq_length: 32 ## Change from 3 to 32 frame sequence
rgb_pretrained_num_classes: 5
sample_strategy: consecutive
sample_rate: 1
# Training Hyperparameter configuration
train_config:
optim:
lr: 0.001
momentum: 0.9
weight_decay: 0.0001
lr_scheduler: MultiStep
lr_steps: [5, 15, 25]
lr_decay: 0.1
epochs: 20 ## Number of Epochs to train
checkpoint_interval: 1 ## Saves model checkpoint interval
## Dataset configuration
dataset_config:
train_dataset_dir: /data/train ## Modify to use your train dataset
val_dataset_dir: /data/test ## Modify to use your test dataset
## Label maps for new classes. Modify this for your custom classes
label_map:
pushup: 0
pullup: 1
situp: 2
## Model input resolution
output_shape:
- 224
- 224
batch_size: 32
workers: 8
clips_per_video: 5
步驟 4:訓練 AI 模型
在訓練時,請依據 Jupyter notebook 中的步驟 4 進行操作。設定環境變數。
訓練動作辨識的 TAO 工具套件任務稱為 action_recognition。在訓練時,請使用 tao action_recognition train 命令。指定訓練規格檔案,並提供輸出目錄和預先訓練模型。或者,可以在 model_config 規格中設定預先訓練模型。
$ tao action_recognition train \
-e $SPECS_DIR/train_rgb_3d_finetune.yaml \
-r $RESULTS_DIR/rgb_3d_ptm \
-k $KEY \
model_config.rgb_pretrained_model_path=$RESULTS_DIR/pretrained/actionrecognitionnet_vtrainable_v1.0/resnet18_3d_rgb_hmdb5_32.tlt
ognition train \
視 GPU、序列長度或期數而定,可能需要幾分鐘到幾小時。因為儲存了每一期,所以看到的模型檢查點與期數一樣多。
模型檢查點是儲存為 ar_model_epoch=<EPOCH NUM>-val_loss=<VAL LOSS>.tlt。選擇最後一期進行模型評估和匯出,但是可以使用驗證損失最低的任何一期。
步驟 5:評估已訓練模型
評估影片的已訓練模型,有兩種不同的取樣策略:
-
-
- 中心模式:挑選序列的中間畫格進行推論。例如,如果模型需要 32 格做為輸入,而影片有 128 格,則從索引 48 至索引 79 中選擇畫格進行推論。
- 卷積模式:從單一影片中以卷積方式取樣 10 個序列,並進行推論。結果經過平均化。
-
在評估時,使用 /specs 目錄中提供的評估規格檔案(evaluate_rgb.yaml)。類似於訓練配置。修改 dataset_config 參數以使用正在訓練的三個類別。
dataset_config:
## Label maps for new classes. Modify this for your custom classes
label_map:
pushup: 0
pullup: 1
situp: 2
使用 tao action_recognition evaluate 命令進行評估。針對 video_eval_mode,可以選擇中心模式或卷積模式,如前所述。使用執行訓練時最後儲存的模型檢查點。
$ tao action_recognition evaluate \
-e $SPECS_DIR/evaluate_rgb.yaml \
-k $KEY \
model=$RESULTS_DIR/rgb_3d_ptm/ar_model_epoch=-val_loss=.tlt \
batch_size=1 \
test_dataset_dir=$DATA_DIR/test \
video_eval_mode=center
評估輸出:
100%|███████████████████████████████████████████| 90/90 [00:03<00:00, 29.82it/s] ******************************* pushup 56.67 pullup 100.0 situp 90.0 ******************************* Total accuracy: 82.222 Average class accuracy: 82.222 2021-11-17 17:46:52,590 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.
在 90 支影片資料集中有三種動作的影片上進行評估。整體準確率大約為 82%,以資料集的大小來說,準確率還不錯。資料集越大,模型的概化能力越好。您可以嘗試使用自己的影片測試準確率。
步驟 6:匯出以進行 DeepStream 部署
最後一步是匯出模型以進行部署。在匯出時,請執行 tao action_recognition export 命令。必須提供包含在 /specs 目錄中,名稱為 export_rgb.yaml的匯出規格檔案。修改 export_rgb.yaml 中的 dataset_config 值以使用訓練的三個類別。這與 evaluate_rgb.yaml 中的 dataset_config 類似。
$ tao action_recognition export \ -e $SPECS_DIR/export_rgb.yaml \ -k $KEY \ model=$RESULTS_DIR/rgb_3d_ptm/ar_model_epoch=-val_loss=.tlt \ /export/rgb_resnet18_3.etlt
恭喜,您的自訂 3D 動作辨識模型已經成功完成訓練。現在,可以使用 DeepStream 部署此模型。
使用 DeepStream 進行部署
本節將說明如何使用 NVIDIA DeepStream 部署已進行微調的模型。
DeepStream SDK 可以協助您快速建立高效率、高效能的影像 AI 應用程式。DeepStream 應用程式可以在搭載 NVIDIA Jetson 的邊緣裝置上、內部部署伺服器上或雲端執行。
為了支援動作辨識模型,DeepStream 6.0 新增了 Gst-nvdspreprocess 外掛程式。將此外掛程式載入自訂函式庫(custom_sequence_preprocess.so),以執行時間序列捕捉和關注區域(region of interest,ROI)部分批次處理,之後,將經過批次處理的張量緩衝區轉送至下游推論外掛程式。
修改 DeepStream SDK 中包含的 deepstream-3d-action-recognition 應用程式,以測試使用 TAO 微調的模型。
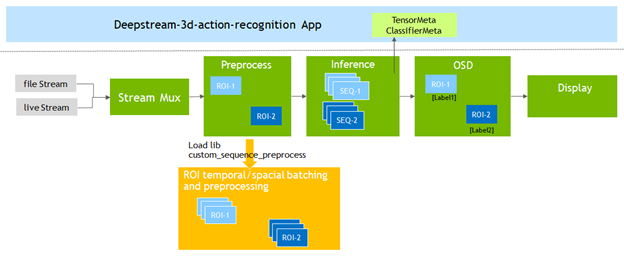
範例應用程式同時針對四個影片檔案執行推論,並以 2×2 並排顯示出呈現的結果。
先執行標準應用程式,再進行修改。首先,啟動 DeepStream 6.0 開發容器:
$ xhost + $ docker run --gpus '"'device=0'"' -it -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -w /opt/nvidia/deepstream/deepstream-6.0 nvcr.io/nvidia/deepstream:6.0-devel
欲深入瞭解 NVIDIA 提供的 DeepStream 容器,請參閱 NGC 目錄。
從容器中前往 3D 動作辨識應用程式目錄,然後從 NGC 下載及安裝標準 3D 與 2D 模型。
$ cd sources/apps/sample_apps/deepstream-3d-action-recognition/ $ wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/tao/actionrecognitionnet/versions/deployable_v1.0/zip -O actionrecognitionnet_deployable_v1.0.zip $ unzip actionrecognitionnet_deployable_v1.0.zip
現在可以使用 3D 推論模型執行應用程式與檢視結果。
$ deepstream-3d-action-recognition -c deepstream_action_recognition_config.txt

預處理器外掛程式配置
在修改應用程式之前,請先熟悉執行應用程式需要之預處理器外掛程式的關鍵配置參數。
從 /app/sample_apps/deepstream-3d-action-recognition 資料夾中開啟 config_preprocess_3d_custom.txt 檔案,並檢視 3D 模型的預處理器配置。
第 13 行定義之 3D 模型需要的 5 維度輸入形狀:
network-input-shape = 4;3;32;224;224
針對此應用程式,使用四個輸入,每一個輸入各具有一個 ROI:
-
-
- 批次號碼為 4(輸入數量 * 每一個輸入的 ROI 數量)。
- 輸入 RGB,所以通道數量為 3。
- 序列長度為 32,輸入解析度為 224×224(HxW)。
-
第 18 行是將使用的自訂序列告知預處理器函式庫:
network-input-order = 2
第 51 和 52 行是定義將畫格傳遞至推論引擎的方式:
stride=1 subsample=0
-
-
- subsample 值為 0,表示依序(畫格 1、畫格 2,依此類推)將畫格傳遞至推論步驟。
- stride 值為 1,表示序列之間存有單一畫格的差異。例如:
- 序列 A:畫格 1、2、3、4,依此類推
- 序列 B:畫格 2、3、4、5,依此類推
-
最後,第 55 – 60 行是定義輸入和 ROI 數量:
src-ids=0;1;2;3 process-on-roi=1 roi-params-src-0=0;0;1280;720 roi-params-src-1=0;0;1280;720 roi-params-src-2=0;0;1280;720 roi-params-src-3=0;0;1280;720
更多與所有應用程式和預處理器參數有關的資訊,請參閱 DeepStream 文件的動作辨識一節。
執行新模型
現在已準備好修改應用程式配置以及測試運動動作辨識模型。
因為是使用 Docker 映像,所以在主機檔案系統與容器之間傳輸檔案的最佳方式是在啟動容器時,使用 -v mount 旗標設定可分享位置。例如,使用 -v /home:/home,將主機的 /home 目錄裝載至容器的 /home 目錄。
將新模型、標籤檔案和文字影片複製到 /app/sample_apps/deepstream-3d-action-recognition 資料夾。
# back up the original labels file $ cp ./labels.txt ./labels_bk.txt $ cp /home/labels.txt ./ $ cp /home/Exercise_demo.mp4 ./ $ cp /home/rgb_resnet18_3d_exercises.etlt ./
開啟 deepstream_action_recognition_config.txt,並變更第 30 行,以指向運動測試影片。
uri-list=file:////opt/nvidia/deepstream/deepstream-6.0/sources/apps/sample_apps/deepstream-3d-action-recognition/Exercise_demo.mp4
開啟 config_infer_primary_3d_action.txt,變更第 63 行上用於推論的模型,並將第 68 行上的批次大小從 4 變更為 1,以便從四個輸入變成單一輸入:
tlt-encoded-model=./rgb_resnet18_3d_exercises.etlt .. batch-size=1
最後,開啟 config_preprocess_3d_custom.txt。變更第 35 行上的 network-input-shape 值,以反映運動辨識模型的單一輸入和配置:
network-input-shape= 1;3;3;224;224
針對單一輸入和 ROI,修改第 77 – 82 行的來源設定:
src-ids=0 process-on-roi=1 roi-params-src-0=0;0;1280;720 #roi-params-src-1=0;0;1280;720 #roi-params-src-2=0;0;1280;720 #roi-params-src-3=0;0;1280;720
現在可以使用以下命令測試新模型:
$ deepstream-3d-action-recognition -c deepstream_action_recognition_config.txt

應用程式原始碼
動作辨識範例應用程式讓您可以靈活地變更輸入來源、輸入數量和使用的模型,而無須修改應用程式原始碼。
在檢視應用程式的建置方式時,請參閱 /sources/apps/sample_apps/deepstream-3d-action-recognition 資料夾中之應用程式的原始碼,以及預處理器外掛程式使用的自訂序列函式庫。
總結
本文是說明分別使用 TAO 工具套件和 DeepStream 微調及部署動作辨識模型的端對端工作流程。TAO 工具套件和 DeepStream 都是已排除 AI 框架複雜性的解決方案,無須具備任何 AI 專業知識,即可在生產中建立和部署 AI 應用程式。
從 NGC 目錄下載模型,開始使用動作辨識模型。
更多的相關資訊,請參閱下列資源: