
NVIDIA NGC 團隊舉辦了包含即時問答的線上研討會,深入探討 NGC 目錄提供的 Jupyter notebook。深入瞭解如何利用這些資源展開 AI 之旅,請造訪: NVIDIA NGC Jupyter Notebook Day: Recommender System。
推薦系統是根據歷史行為預測使用者對產品的偏好,並在線上零售中廣泛運用於產品推薦、在社交媒體中提供針對性廣告、在串流影音平台中提供以使用者為中心的內容等。
我在上一篇文章使用 NGC 提供的 Jupyter notebook 更快速地建構影像分割中,探討了一些先進模型建構、訓練和最佳化的固有問題。我同時提到現在 NGC 已增加了 Jupyter notebook 範例,並說明如何使用 NGC 目錄提供的成品,訓練和部署模型。
在本文章中,將會示範如何使用推薦系統 notebook 範例。此 notebook 中的已訓練模型可以為使用者預測電影評分,並推薦電影。
推薦系統
變分自動編碼器(Variational Autoencoder,VAE)是《Variational Autoencoders for Collaborative Filtering》所述架構的最佳化建置,可以用於推薦任務。Jupyter notebook 呈現出訓練和測試 VAE 模型的過程。模型是由兩個部分組成:編碼器和解碼器。編碼器將包含特定使用者互動的向量,轉換成 n 維變分分布。您可以使用此變分分布取得使用者的潛在表示。之後,此潛在表示將會傳送至解碼器,產生之結果為特定使用者的項目互動機率向量。
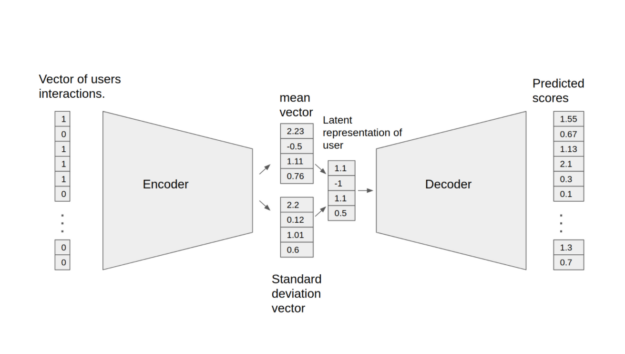
在此模型中建置下列功能:
- 稀疏矩陣支援
- 資料平行多 GPU 訓練
- 具有後移的動態損耗縮放,可用於張量核心(混合精度)訓練
- 功能支援矩陣
請確保您具有下列資源,才能遵循此教學:
- NVIDIA Docker
- TensorFlow 20.12-tf1-py3 NGC 容器
- 使用搭載 NVIDIA GPU 的系統
複製儲存庫
您可以在 NGC 目錄資源頁面上找到與此模型有關的資源。您可以從右上角選單或使用 wget resource 命令,手動下載資源。
請依據下述步驟,使用命令列介面下載資源及解壓縮:
- 使用 mkdir 建立新資料夾。
- 使用 cd 前往新資料夾。
- 使用 wget 將資源壓縮檔下載至資料夾內。
- 使用 unzip 將壓縮檔解壓縮。
mkdir VAE cd VAE wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/vae_for_tensorflow/versions/20.06.0/zip -O vae_for_tensorflow_20.06.0.zip unzip vae_for_tensorflow_20.06.0.zip
建立容器
使用剛才下載之資源資料夾內的 Dockerfile 建立容器:
docker build . -t < tagname>
您可以使用任何名稱標記容器。
docker build . -t vae
執行容器
啟動容器。將會為容器內的資料裝載資料夾。將電影評分資料集下載至此資料夾內。針對此容器設定連接埠 8888:8888,未來即可使用該連接埠存取容器內的 Jupyter notebook。
docker run -it --rm --runtime=nvidia -v /data/vae-cf:/data -p 8888:8888 vae /bin/bash
資料集
在本文章中,是使用 MovieLens 20m 資料集訓練模型。MovieLens 20M 為電影評分資料集,包含 138,000 位使用者套用至 27,000 部電影的 2,000 萬筆評分和 465,000 個標籤。模型之目標是考量使用者先前的設定:電影、評分等等,為使用者預測新電影的評分。
如果未下載資料集,請執行以下命令,以下載 MovieLens 資料集及解壓縮至 /data/ml-20m/extracted/ 資料夾。您可以在 Docker 容器中執行以下命令,針以對資料集進行預處理:
python prepare_dataset.py
在預設之情況下,資料集是儲存在 /data 目錄中。請將需要的位置傳遞至 –data_dir 引數,以便將資料儲存在不同的位置。
mkdir /data/ml-20m mkdir /data/ml-20m/extracted wget http://files.grouplens.org/datasets/movielens/ml-20m.zip unzip ml-20m.zip
如果已將資料集下載及解壓縮至其他位置時,請執行以下命令,先退出目前的 VAE-CF Docker 容器,再裝載 MovieLens 資料集位置,以重新啟動 VAE-CF Docker 容器。
exit docker run -it --rm --gpus all -v /data/vae-cf:/data -v <ml-20m folder path>:/data/ml-20m/extracted/ml-20m -p 8888:8888 vae /bin/bash
在容器內訓練和測試模型
當容器正在運行,且容器內的資料集可以存取時,使用 Jupyter notebook 執行其餘命令。在容器中開啟 Jupyterlab 工作空間。之後,將 VAE 模型 notebok 上傳與執行 notebook 的單元,針對該模型進行訓練、測試和推論。
jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root
準備資料集
將資料集下載至解壓縮的資料夾之後,返回主要工作空間,並執行 prepare_dataset.py。此命令會劃分 ml-20m 資料集,以用於訓練、驗證和測試。
python prepare_dataset.py
訓練模型
使用 train 引數執行 main.py 指令碼,以開始進行訓練。產生的檢查點(包含已訓練模型權重)之後將儲存在 –checkpoint_dir 目錄選項指定的目錄中。在預設之情況下,不儲存檢查點。
此外,–results_dir 命令列引數(預設為 None)是指定使用 JSON 格式儲存以下統計資料的位置。命令列引數的完整清單以及訓練期間記錄的驗證指標和效能指標的字典,是儲存為 /args.json。
在執行訓練命令時,將會看到每一期訓練過程的詳細資訊。此外,可以變更 main.py 的引數,以變更模型的訓練超參數。欲深入瞭解 main.py 引數,請參閱 notebook 的最後一個單元。
在50 期之後執行推論,以查看模型的召回率(Recall)。召回率指標將模型效能表示為正確預測評分占所有正確評分的百分比:真陽性/(真陽性 + 假陰性)。
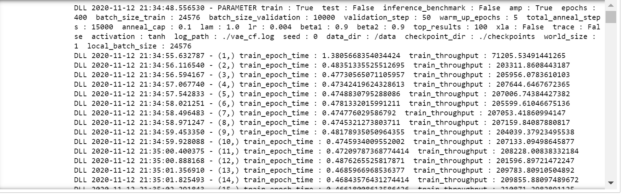
mpirun --allow-run-as-root -np 1 -H localhost:8 python main.py --train --amp --checkpoint_dir ./checkpoints
圖 3 為執行上一個命令的輸出。
測試模型
模型匯出至預設的 model_dir 位置,可以使用以下命令載入和測試。使用已儲存在檢查點資料夾中的已訓練模型權重及測試資料,以取得處理隱藏資料的效能。
在此步驟中,是使用預留的資料集測試已訓練模型,以測試模型的效能。您也可以檢視召回率指標,以檢視預測準確度。
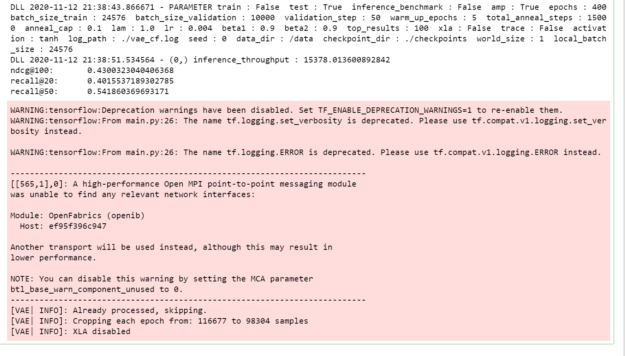
python main.py --test --amp --checkpoint_dir ./checkpoints
圖 4 為測試命令的輸出。
Main.py
此模型是使用一些預設超參數和小型資料集進行訓練,總計 400 期。您可以使用更大的資料集、增加訓練期數,並選擇不同的超參數,以提升模型效能。Main.py –help 命令會呈現使用該特定模型的不同選項。main.py 指令碼也會提供所有功能的進入點,例如訓練、測試和推論。指令碼的行為是由下一節列出的命令列引數控制。prepare_dataset.py 指令碼可以針對 MovieLens 20m 資料集進行預處理。
參數
最重要的命令列參數包括:
- –data_dir- 指定 Docker 容器內用於儲存資料的目錄,覆蓋預設位置/資料。
- –checkpoint_dir- 控制是否以及在何處儲存檢查點。
- –amp- 啟用混合精度訓練。
同時有許多參數可以控制訓練過程的各種超參數,例如學習率、批次大小等。想要查看可用選項及其描述的完整清單,請使用 -h 或 –help 命令列選項。
python main.py --help
圖 5 為可自訂 main.py 的選項。

總結
本文是說明如何提取 VAE 模型,並使用與此模型有關的資源建構容器。之後,將 notebook 上傳至容器中,以訓練和測試模型。
請造訪 NGC 目錄,下載用於推薦系統的 Jupyter notebook,並將其應用在您的使用案例。
NVIDIA 深度學習機構(DLI)提供人工智慧、加速運算和加速資料科學的實作訓練課程,歡迎參加由專業講師的帶領的建造智慧推薦系統實作坊,涵蓋了建立高效推薦系統所需的基本工具和技術,並會說明如何部署 GPU 加速的解決方案以即時提供推薦。取得 NVIDIA DLI 認證證書,協助自我專業職涯成長。