
編者按:此篇文章屬於「解碼 AI 」系列,該系列文章會以簡單易懂的方式解碼 AI,同時展示適用於 RTX PC 和工作站使用者的全新硬體、軟體、工具和加速功能。
隨著生成式 AI 的進步並在各產業中普及,在本機 PC 和工作站上執行生成式 AI 應用程式的重要性也與日俱增。本機推論可為消費者帶來降低的延遲、消除他們對網路的依賴,並加強他們對資料的掌控。
NVIDIA GeForce 和 NVIDIA RTX GPU 搭載 Tensor 核心,這是專門的 AI 硬體加速器,可提供在本機執行生成式 AI 所需的強大效能。
Stable Video Diffusion 現在已針對 NVIDIA TensorRT 軟體開發套件最佳化,為超過 1 億台採用 RTX GPU 的 Windows PC 和工作站解鎖最高效能的生成式 AI。 您可以在 Hugging Face 下載最佳化的 Stable Video Diffusion 1.1 影像轉影片模型。
針對 Automatic1111 的 Stable Diffusion WebUI 所推出的 TensorRT 擴充功能,現在新增了對 ControlNet 的支援,讓使用者能透過新增其他影像作為指引,進一步控制並調整生成輸出。
TensorRT 加速可以在全新的 UL Procyon AI 影像生成基準測試中進行測試,內部測試顯示該基準測試準確地複製了真實世界的表現。與最快速的非 TensorRT 實作相比,TensorRT 在 GeForce RTX 4080 SUPER GPU 上可加速50%,且比最接近的競爭對手快 2 倍以上。
更有效率、更精準的 AI
TensorRT 讓開發者能夠使用提供全面最佳化 AI 體驗的硬體。與在其他框架上執行的應用程式相比 AI 效能通常會加倍。
這也能加速最熱門的生成式 AI 模型,例如 Stable Diffusion 和 SDXL。Stability AI 的影像轉影片生成式 AI 模型「Stable Video Diffusion」透過 TensorRT 體驗 40%的速度提升。
此外,Stable Diffusion WebUI 的 TensorRT 擴充功能可將效能提升高達 2 倍,大幅簡化 Stable Diffusion的 工作流程。
透過此擴充功能的最新更新,TensorRT 最佳化效果將延伸至 ControlNet,這是一組透過新增額外條件來協助引導漫射模型輸出的 AI 模型。有了 TensorRT,ControlNet 的速度提升了 40%。
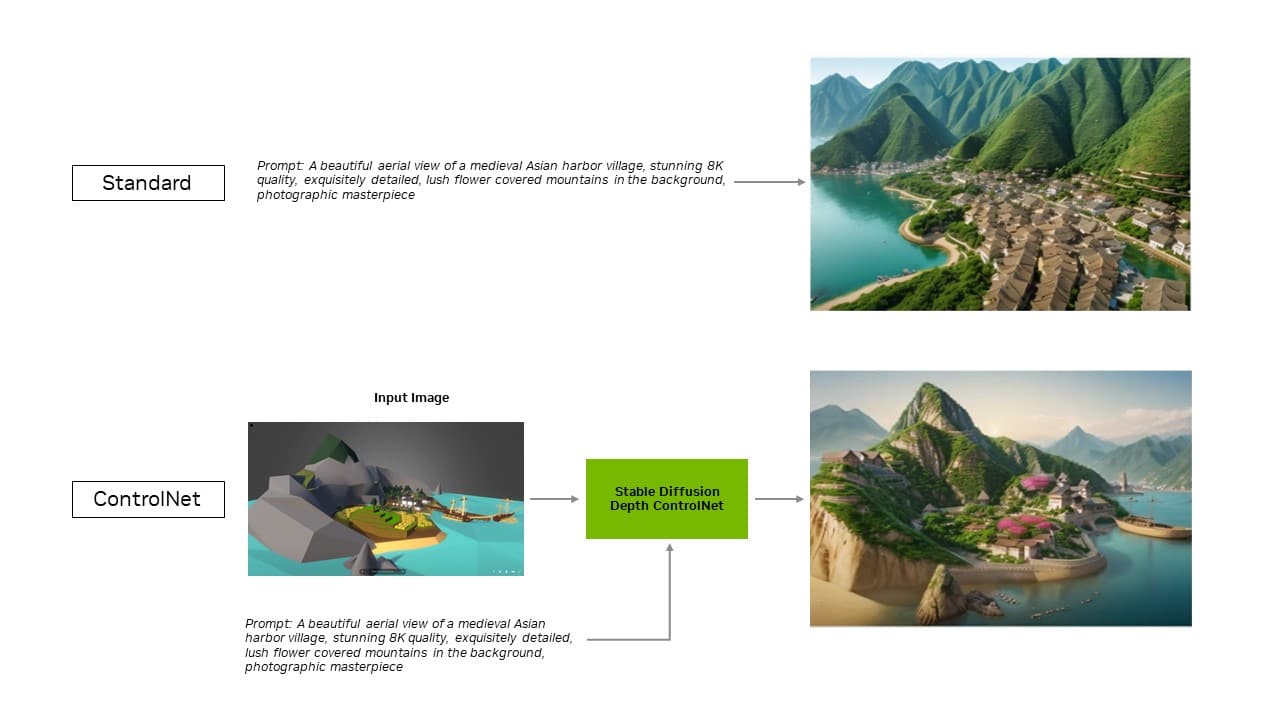
使用者可以引導輸出內容以符合輸入影像,進而控制最終影像。他們也可以同時使用多個 ControlNet,以更進一步控制內容。ControlNet 可以是深度圖、邊緣圖、法線圖或關鍵點偵測模型等。
立即在 GitHub 上下載適用於 Stable Diffusion Web UI 的 TensorRT 擴充功能。
TensorRT 加速的其他熱門應用程式
Blackmagic Design 在 DaVinci Resolve 更新 18.6 中採用 NVIDIA TensorRT 加速 。其 AI 工具 ,如 Magic Mask、Speed Warp 和 Super Scale,在 RTX GPU 上的執行速度比 Mac 快 50% 以上,最高達 2.3 倍。
此外,透過 TensorRT 整合, Topaz Labs 的 Photo AI 和 Video AI 應用程式效能提升高達 60%,例如相片雜訊消除、銳利化、相片超解析度、影片慢動作、影片超解析度、影片穩定功能等,全都可在 RTX 上執行。
結合 Tensor 核心與 TensorRT 軟體 ,為本機 PC 和工作站帶來無與倫比的生成式 AI 效能。在本機執行可發揮多項優勢:
- 效能:整個模型在本機執行時,延遲便與網路品質無關,因此使用者能體驗到較低的延遲。這對於遊戲或視訊會議等即時使用情境來說相當重要。NVIDIA RTX 提供最快速的 AI 加速器,可提升至超過 1,300 AI每秒兆次 (TOPS)。
- 成本:使用者不必為大型語言模型推論的雲端服務、雲端託管應用程式程式介面或基礎架構支付費用。
- 隨時開啟:使用者無論身在何處都可以使用 LLM 功能,無需仰賴高頻寬網路連線。
- 資料隱私:私人和專屬資料可以一直保留在使用者的裝置上。
專為 LLM 最佳化
TensorRT 為深度學習帶來的益處,就如 NVIDIA TensorRT-LLM 為最新的 LLM 帶來的益處。
TensorRT-LLM 是可加速並最佳化 LLM 推論的開放原始碼函式庫,包含對熱門社群模型的立即支援,包括 Phi-2、Llama2、Gemma、Mistral 和 Code Llama。從開發者、創作者,到企業員工和一般使用者,任何人都可以在 NVIDIA AI Playground 中實驗 TensorRT-LLM 最佳化模型。此外,透過 NVIDIA ChatRTX 技術展示,使用者可以查看在 Windows PC 本機上執行的各種模型效能。ChatRTX 以 TensorRT-LLM 為基礎打造,可在 RTX GPU 上提供最佳化效能。
適用於 Windows 的 TensorRT-LLM 透過全新的封裝工具,與 OpenAI 熱門的 Chat API 相容,可輕鬆地在雲端和本機 RTX 系統上切換正在執行的 LLM 應用程式。
NVIDIA 正與開放原始碼社群合作,開發適用於熱門應用程式框架 (包括 LlamaIndex 和 LangChain) 的原生 TensorRT-LLM 連接器。
這些創新技術讓開發者能輕鬆地在應用程式中使用 TensorRT-LLM,並透過 RTX 體驗最佳 LLM 效能。
訂閱解碼 AI 電子報,即可直接在收件箱中收到每週更新。