
對語音辨識技術感興趣嗎?請訂閱我們的語音 AI 電子報。
語音 AI 是一種可以使用語音與電腦系統通訊的技術。想要對車內助理下令或操作智慧居家裝置?您無須在螢幕上輸入或點按,AI 語音介面可以協助您與裝置互動。
語音 AI相對較新的領域。但是隨著語音互動日漸成熟,並擴展至新的裝置與平台,對開發人員來說,最重要的是認識不斷演變的術語。
本指南係介紹語音 AI 領域的主要概念、說明它在廣大的 AI 宇宙中的所在位置,並探討它與其他科技領域的關係。
基礎概念
您可能已經聽過,甚至已熟悉這些技術,但是為了能完整說明,以下提供了基礎知識:
- 人工智慧 (AI) 指創造可媲美或超越人類認知水準能力之智慧機器的廣泛學科。
- 機器學習 (ML) 是 AI 的次領域,創造學習如何使用過去資料執行特定任務的方法和系統。
- 深度學習 (DL) 是以一系列多層人工神經網路為基礎的 ML 方法,通常使用大量的資料進行訓練。
語音 AI 系統與 AI、ML 和 DL 有何關係?
語音 AI 是指將 AI 運用於以語音為基礎的技術。語音 AI 系統的核心元件包括:
- 自動語音辨識 (ASR) 系統,又稱為語音轉文字或語音辨識。可以將語音聲音訊號轉換成文字。
- 文字轉語音 (TTS) 系統,又稱為語音合成。可以將文字變成口語聲音形式。
語音 AI 是對話式 AI (Conversational AI)中的次領域,主要利用來自於 DL 和 ML 領域的技術。AI、ML、DL 和語音 AI 之間的關係可以使用圖 1 的文氏圖表示。
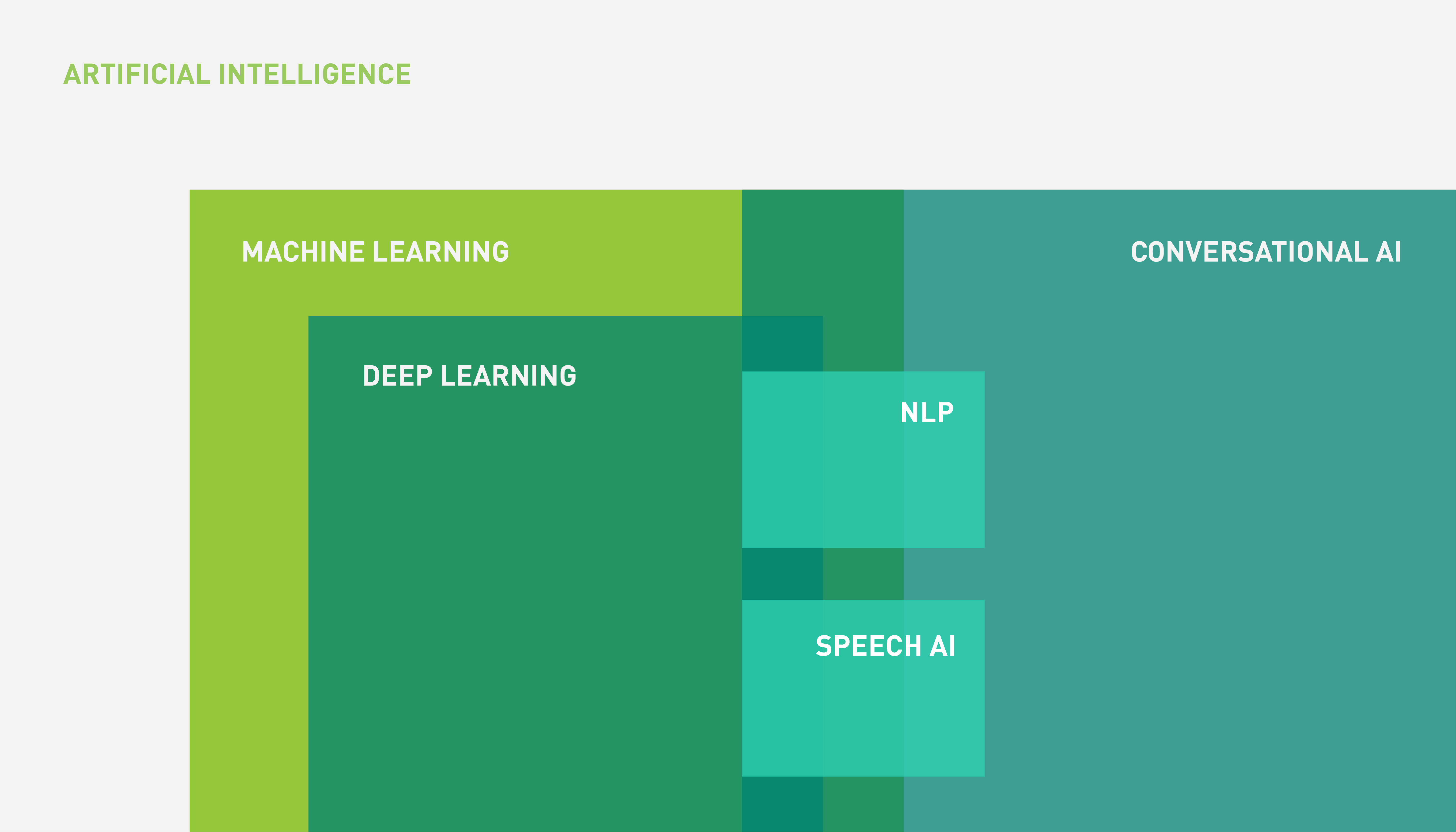
圖 1. AI、ML、DL 和語音 AI 之間的關係
如圖 1 所示,對話式 AI 是較大的宇宙,由以語言為基礎的應用組成,非全部都包含語音元件 (語音)。
以下說明語音 AI 技術如何與其他工具和技術結合成完整的對話式 AI 系統。
對話式 AI
對話式 AI是一種設計能以對話方式,透過自然語言與人類使用者互動之智慧系統的學科。商業範例包括居家助理和聊天機器人 (例如保險理賠聊天機器人或旅行社聊天機器人)。
具有多種對話方式,包括聲音、文字、手語,但是當輸入和輸出口語自然語言時,即需要以語音為基礎的對話式 AI 系統 (圖 2)。
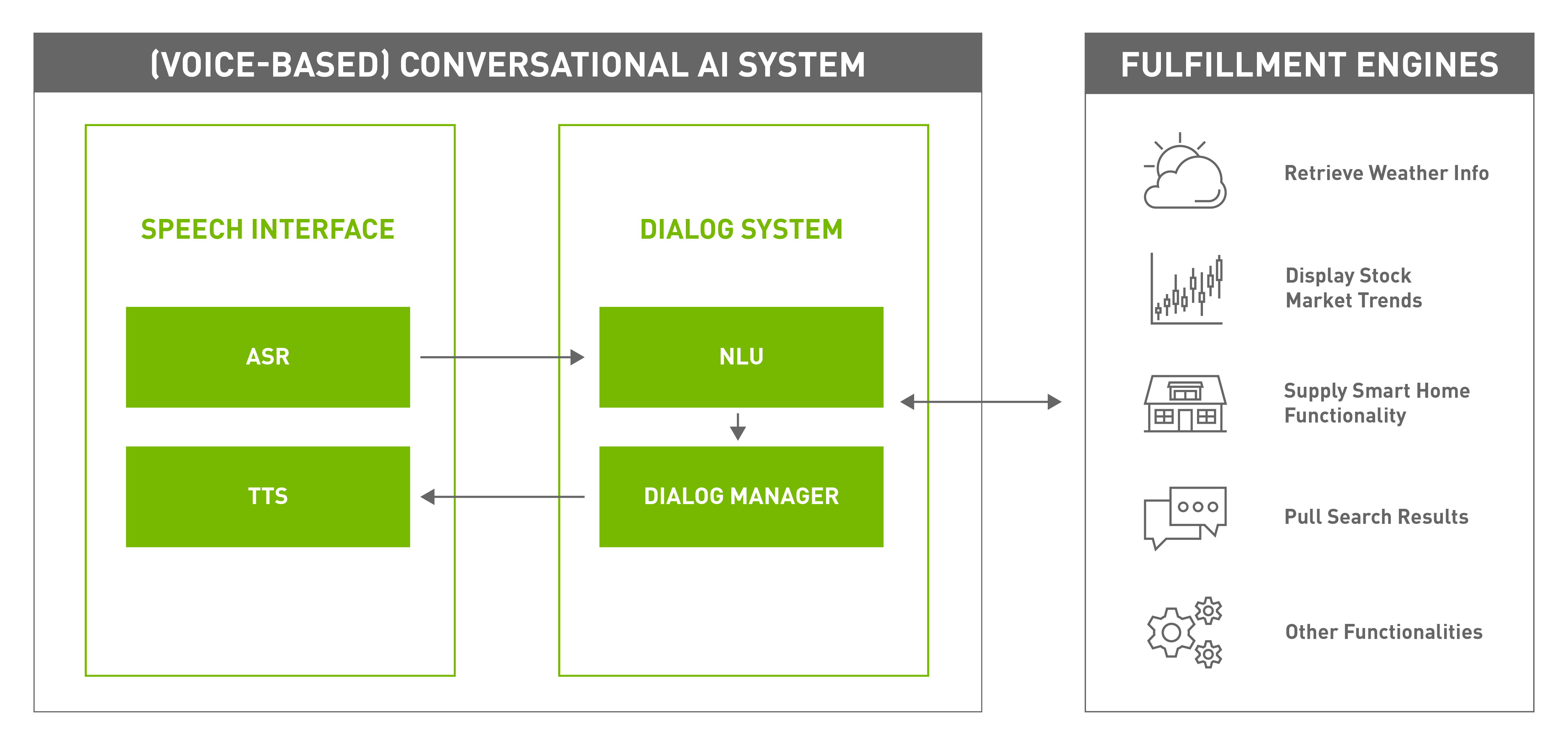
以語音為基礎的典型對話式 AI 系統的元件,包括:
- 搭載語音 AI 技術的語音介面可以讓系統透過口語自然語言形式與使用者互動。
- 對話系統是管理與使用者的對話,同時與外部履行系統互動,以滿足使用者的需求。它是由兩個元件組成:
- 履行引擎執行對話式 AI 系統負責的任務,例如:擷取天氣資訊、閱讀新聞、訂票、提供股票市場資訊、回答一般問題等等。它們通常不是被視為對話式 AI 系統的一部分,而是密切合作,滿足使用者的需求。
語音 AI 概念
本節探討了語音 AI 的概念:自動語音辨識和文字轉語音。
自動語音辨識
以深度學習為基礎的典型 ASR 管道,包含五個主要元件 (圖 3)。
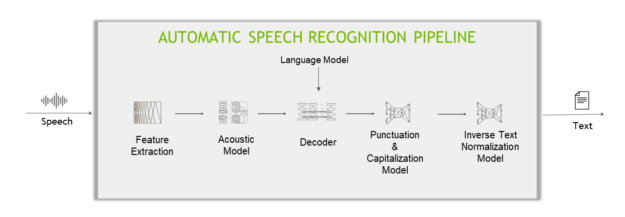
圖 3. 以深度學習為基礎的 ASR 管道結構
特徵擷取(Feature Extraction)
特徵擷取可以將聲音訊號分成固定長度區塊 (又稱時間步階),然後將區塊從時域轉換到頻域。
聲學模型(Acoustic Model)
此機器學習模型 (通常是多層深度神經網路) 是在聲音資料的各個時間步階,預測字元出現的機率。
解碼器(Decoder)和語言模型
解碼器是將聲學模型提供的機率矩陣轉換成一連串的字元,進而構成單字和句子。
語言模型 (LM) 可以提供分數,表示出現訓練語料庫中之句子的可能性。例如,在英文語料庫上訓練的 LM 在判定句子時,「Recognize speech」的可能性將會高於「Wreck a nice peach」,且不可能會出現「Je suis un étudiant」(因為這是法文句子)。
當解碼器與 LM 結合時,可以將「聽到」的句子 (「I’ve got rose beef for lunch」) 修正為較合理的句子 (「I’ve got roast beef for lunch」),因為 LM 給予第二句的分數將會高於第一句。
標點符號(Punctuation)和大寫化模型
標點符號和資本化模型加入標點符號,以及將解碼器產生的文字大寫化(Capitalization)。
反向文字正規化模型
最後,套用反向文字正規化 (ITN) 規則,將口語格式文字轉換成需要的書面格式,例如將「ten o’clock」轉換成「10:00」,或將「ten dollars」轉換成「$10」。
其他 ASR 概念
單字錯誤率 (WER) 和字元錯誤率 (CER) 是 ASR 系統的典型效能指標。
WER 是將錯誤數量除以口語單字總數。例如,如果總共 50 個口語單字中有五個錯誤,則 WER 為 25%。
CER 的運作方式類似,不同之處在於針對字元而不是單字。日文、中文等語言沒有以特定標記或分隔符號 (例如英文空格) 分隔的「單字」。
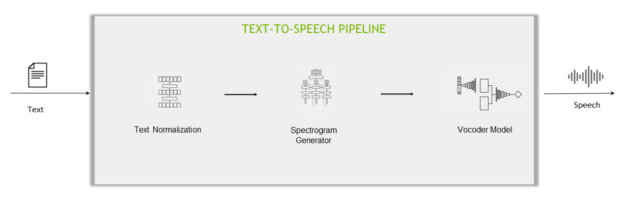
文字轉語音 (TTS)
通常使用兩種不同的方法完成文字轉語音步驟:
- 兩階段管道:分別訓練兩個不同的網路,將語音轉換為文字:聲譜圖產生器網路和聲碼器網路。
- 端對端管道:使用一個模型直接從文字產生聲音。
兩階段管道的元件為:
- 文字正規化模型:將書面格式的文字轉換成口語格式,例如將「10:00」轉換成「ten o’clock」、將「$10」轉換成「ten dollars」。此過程與 ITN 相反。
- 聲譜圖產生器網路:TTS 管道的第一階段是使用神經網路從文字產生聲譜圖。
- 聲碼器網路:TTS 管道的第二階段是將來自聲譜圖產生器網路的聲譜圖視為輸入,並產生聽起來自然的語音。
語音合成標記語言
其他 TTS 概念包括語音合成標記語言 (SSML),一種以 XML 為基礎的標記語言,讓您可以指定如何將輸入文字轉換為合成語音。您的配置可以使用音高、發音、說話速度、音量等參數,使產生的合成語音變得更生動。
常見的 SSML 標籤包括:
- 韻律可以自訂產生之語音的音高、說話速度和音量。
- 音素可以手動覆蓋產生之合成語音中的單字發音。
平均意見分數
通常是使用平均意見分數 (MOS) ,評估 TTS 引擎的品質。MOS 是源自於電信領域,定義為人類評估者在主觀品質評估測試中針對特定刺激進行評分的算術平均值。
例如,常見的 TTS 評估設定是由一群人聆聽產生的樣本,並給予每一個樣本0 到 5 的分數。然後根據整體評估者和測試樣本的平均分數計算出 MOS。
如何開始使用語音 AI
現在語音 AI 已成為主流,是消費者日常生活中不可或缺的一部分。企業正在整合語音 AI 功能,探索為產品帶來附加價值的新方法。
獲得語音 AI 專業知識的最佳方式是進行體驗。更多與如何為對話式 AI 應用程式建立和部署即時語音 AI 管道有關的資訊,請參閱免費的 Building Speech AI Applications 電子書。
或者立即下載NVIDIA 對話式AI開發套件包。