
- NVIDIA Blackwell 橫掃全新 SemiAnalysis InferenceMAX v1 基準測試,展現最高效能與最佳整體效率。
- InferenceMAX v1 是首個在多樣化模型與真實場景中衡量總運算成本的獨立基準測試。
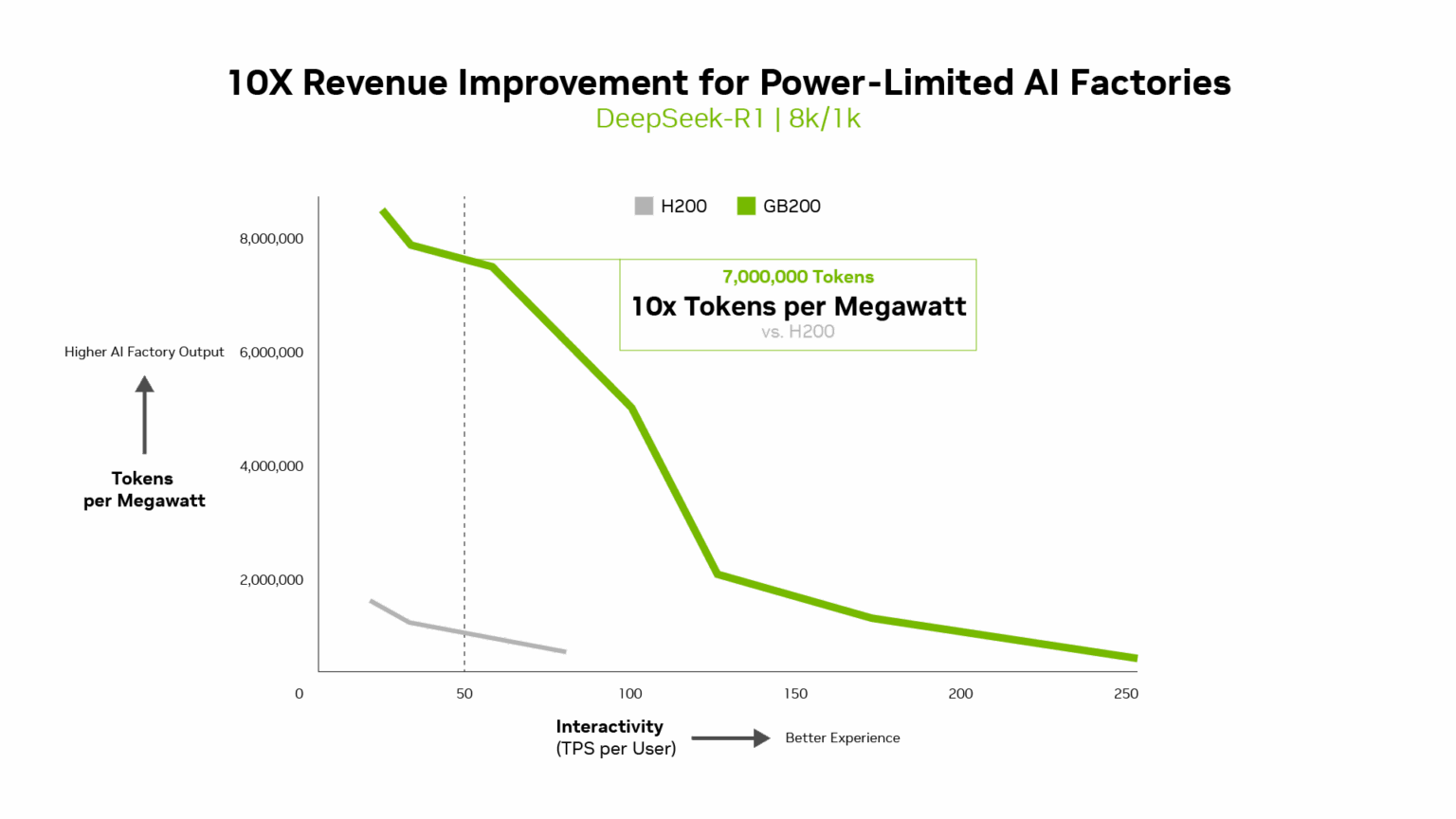
- 最佳投資報酬:NVIDIA GB200 NVL72 帶來無可比擬的 AI 工廠經濟效益。投資 500 萬美元可創造 7,500 萬美元的 DSR1 詞元收益,提供 15 倍投資報酬率。
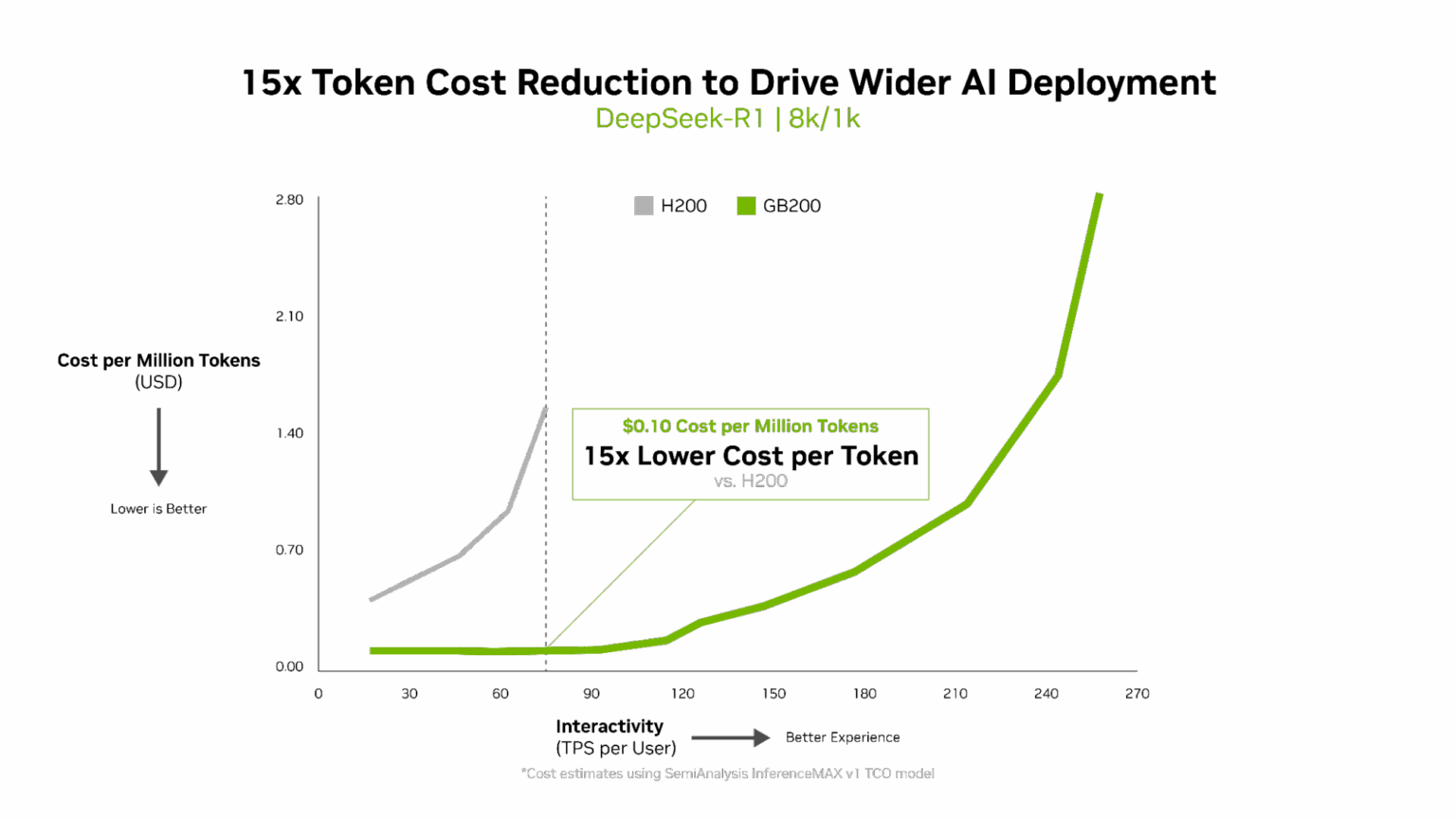
- 最低總擁有成本:NVIDIA B200 的軟體最佳化在 gpt-oss 上實現每百萬詞元兩美分,於兩個月內降低詞元成本5 倍。
- 最佳輸送量與互動性:搭載最新 NVIDIA TensorRT-LLM 技術架構的 NVIDIA B200,在 gpt-oss 上可達到每 GPU 每秒 60,000 個詞元、每使用者每秒 1,000 個 詞元 的效能水準。
隨著人工智慧(AI)從一次性回覆轉變成複雜推理(reasoning),推論(inference)的需求與其背後的經濟效益正急速成長。
全新的獨立 InferenceMAX v1是首個在真實場景中衡量總運算成本的基準測試。結果顯示,NVIDIA Blackwell 平台橫掃全場,為 AI 工廠實現無與倫比的效能與最佳整體效率。
投資 500 萬美元於 NVIDIA GB200 NVL72 系統,可創造 7,500 萬美元的詞元(token)收益,帶來15 倍投資報酬率 – 這是推論運算的新經濟模式。
NVIDIA 超大規模與高效能運算副總裁 Ian Buck 表示:「推論是 AI 每天創造價值的關鍵。這些結果證明,NVIDIA 的全端策略提供客戶在大規模部署 AI 時所需的效能與效率。」
InferenceMAX v1 登場
InferenceMAX v1 是 SemiAnalysis 於週一發布的全新基準測試,再次突顯了 Blackwell 在推論的領導地位。該基準在主要平台上運行熱門模型,測量多樣化使用情境下的效能,並公開任何人皆可驗證的結果。
為什麼這一類型的基準測試如此重要?
因為現代 AI 不僅關乎速度,更關乎效率與經濟規模。隨著模型從一次回覆轉變為多步驟推理與工具使用,每次查詢生成的詞元數大量增加,顯著推升了運算需求。
NVIDIA 與 OpenAI(gpt-oss 120B)、Meta(Llama 3 70B)及 DeepSeek AI(DeepSeek R1)在開源領域的合作,展示了社群驅動模型如何推進推理與效率的最先進成果。
透過與這些領先模型開發者及開源社群合作,NVIDIA 確保最新模型能針對全球最大規模的 AI 推論基礎設施進行最佳化。這反映 NVIDIA 對開放生態系的承諾,共享創新以為所有人加速進展。
與 FlashInfer、SGLang 和 vLLM 社群的深度合作,使得共同開發的增強核心與運行時,能大規模驅動這些模型。
軟體最佳化持續推升效能
NVIDIA 透過硬體與軟體協同設計來持續提升效能。gpt-oss-120B 在搭載 NVIDIA TensorRT-LLM 函式庫的NVIDIA DGX Blackwell B200 系統上,初始效能即為業界領先,但 NVIDIA 團隊與社群進一步對針對開源大型語言模型,大幅最佳化了 TensorRT LLM 的效能表現。
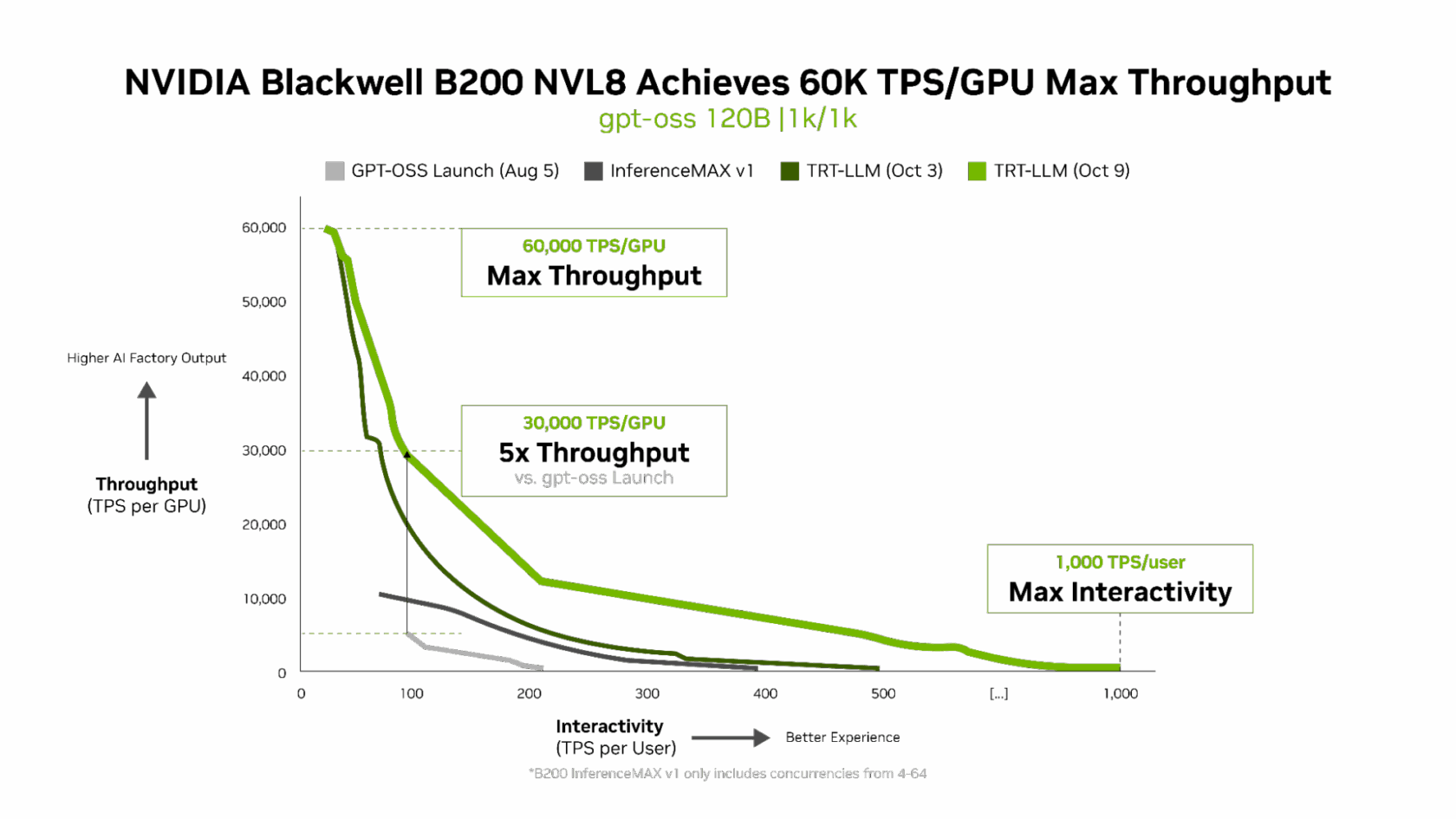
TensorRT-LLM v1.0 的發布,是推動大型 AI 模型更快速、更具回應性的重大突破。
透過先進的平行化技術,它運用 B200 系統與 NVIDIA NVLink Switch 的 1,800 GB/s 雙向頻寬,大幅提升 gpt-oss-120B 模型的效能。
創新不僅於此。全新發布的 gpt-oss-120b-Eagle3-v2 模型引入「推測式解碼 (speculative decoding)」,這個聰明的方法能一次預測多個詞元,降低延遲並提升速度,將每使用者輸送量提升三倍,達每用戶每秒100 詞元(TPS / user),每 GPU 速度從 6,000 提升至 30,000 詞元。
對於 Llama 3.3 70B 等密集 AI 模型,由於其龐大參數需於推論中同時運作而需要大量的運算資源,NVIDIA Blackwell B200 在 InferenceMAX v1 基準測試中創下全新效能標準。
Blackwell 在每 GPU 達10,000 TPS、每使用者50 TPS互動性的條件下,提供較 NVIDIA H200 高 4 倍的每GPU輸送量。
效能效率帶來價值
每瓦輸出詞元量、每百萬詞元成本與每使用者TPS等指標與輸送量同等重要。對功率受限的 AI 工廠而言,Blackwell 每兆瓦輸送量比上一代提升 10 倍,能轉化為更的高詞元收益。
每詞元成本是衡量 AI 模型效率的關鍵,直接影響營運支出。NVIDIA Blackwell 架構將每百萬詞元成本較上一代降低 15 倍,帶來可觀節省並推動更廣泛的AI應用。
多維效能
InferenceMAX 採用帕雷托前沿(Pareto frontier)展示資料中心輸送量與回應性等因素間的最佳權衡,並比較效能。
但這不僅是一張圖表,它展現 NVIDIA Blackwell 如何在成本、能源效率、輸送量與回應性等考量中取得平衡,從而在真實工作負載中實現最高投資報酬率。
只針對單一場景最佳化的系統雖可能在孤立測試中達巔峰,但經濟性無法擴展。Blackwell 的全端設計在實際生產中提供關鍵的效率與價值。
若要深入了解這些曲線的構建方式,以及其對總體擁有成本與服務水準協議規劃的意義,可參考深度技術報告以查看完整圖表與研究方法。
成就關鍵
Blackwell 的領先地位來自極致的硬體與軟體協同設計。這是一套為速度、效率與規模而生的全端架構:
- Blackwell 架構特色包括:
- NVFP4 低精度格式,在不犧牲準確度的情況下提升效率
- 第五代 NVIDIA NVLink,連接 72 個 Blackwell GPU如同一個大型 GPU共同運作
- NVLink Switch 透過先進的張量、專家系統與 data parallel attention演算法支援高度並行
- 年度硬體更新節奏與持續軟體最佳化。NVIDIA 自發表以來僅透過軟體便使 Blackwell 效能提升兩倍以上
- NVIDIA TensorRT-LLM、NVIDIA Dynamo、SGLang 與 vLLM 等開源推論框架皆經過最佳化以實現巔峰效能
- 龐大生態系:數百萬 GPU 部署、700 萬 CUDA 開發者,並對超過 1,000 個開源專案貢獻
更宏觀的視野
AI 正從試點階段邁向 AI 工廠時代,這些基礎設施能即時將資料轉化為詞元與決策。
開放且定期更新的基準測試協助團隊在每詞元成本、延遲性服務水準協議與動態工作負載利用率間做出正確平台選擇。
NVIDIA 的 Think SMART 架構協助企業面對這一轉變,說明 NVIDIA 全端推論平台如何將效能轉化為實際投資報酬率,讓表現變成收益。