
機器學習是採用演算法和統計模型,讓電腦系統可以從大量資料中找出模式。之後,可以使用辨識這些模式的模型預測或描述新的資料。
如今,機器學習幾乎已使用在所有的產業中,包括零售、醫療、運輸、金融,以提高客戶滿意度、生產力和作業效率。但是,進入可以試用新工具和技術的環境通常很困難,最糟的情況會令人望之卻步。
本文將說明使用 RAPIDS 建立端對端機器學習服務的各個步驟,從資料處理到模型訓練,再到推論。利用 NGC 目錄之新的一鍵部署功能,可以存取 notebook 及試用機器學習工作流程,而無須自行啟動基礎架構與安裝套件。
利用 AI 軟體和基礎架構加快應用程式開發
如果您已經開始建構資料科學應用程式,那你與 RAPIDS 只有一步之差了。
RAPIDS:加快機器學習
RAPIDS 是一套可以完全在 GPU 上開發和執行端對端資料科學與分析工作流程的開放原始碼軟體函式庫套件。RAPIDS Python API 的外觀和風格與您熟悉的資料科學工具如 pandas 和 scikit-learn 相同,所以僅需要稍微變更程式碼即可獲得效益。
RAPIDS 消除了現代資料科學工作流程中的瓶頸,在擷取過程中直接將資料帶至及保存在 GPU 上,以進行探索、特徵工程和模型訓練。讓您可以在機器學習工作流程的早期階段快速進行迭代,並於固定之時間在 GPU 上試用更先進的技術。
RAPIDS 也與其他知名的框架整合,包括 XGBoost,提供了 API,以透過梯度提升決策樹進行訓練和推論。
NGC 目錄:GPU 最佳化軟體的中心
NVIDIA NGC 目錄提供 GPU 最佳化 AI 和機器學習框架、SDK 以及預先訓練模型。其同時包含用於各種應用程式的範例 Jupyter notebook,包括本文介紹的範例。現在,僅需要按一下 Vertex AI Workbench,即可輕鬆部署 notebook。
Google Cloud Vertex AI:GPU 加速雲端平台
Google Cloud Vertex AI Workbench 是適用於整體資料科學工作流程的單一開發環境。它與在實際環境中快速建構和部署模型需要的所有服務深度整合,以加快資料工程。
此一鍵功能是由NVIDIA 與 Google Cloud 合作開發,可以在 Vertex AI 上,以最佳配置啟動 JupyterLab 執行個體、預先載入軟體相依性,並一次下載 NGC notebook。讓您可以立即開始執行程式碼,不需要任何專業知識,即可配置開發環境。
如果您沒有 Google Cloud 帳戶,請註冊以獲得免費積分,建構和執行此應用程式。
開始建構
以下是開始 GPU 加速資料科學旅程需要的每一個步驟。
評估環境
在開始之前,確定已滿足下列先決條件:
- 已註冊 NGC 帳戶及登入。
- 已註冊 Google Cloud Platform 帳戶及登入。
在登入 NGC 後,即會呈現出精選內容。
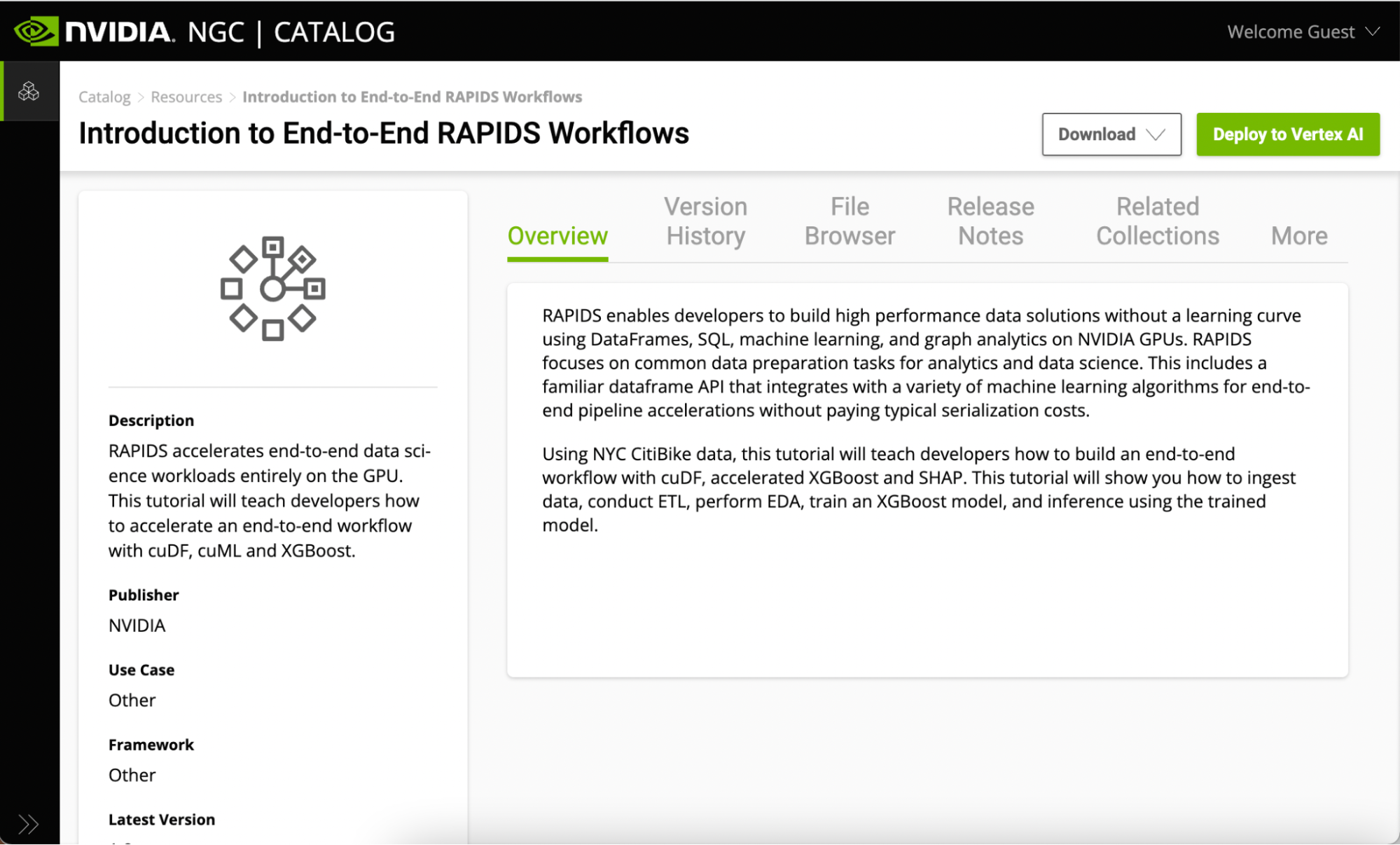
NGC 上的所有 Jupyter notebook 都包含在資源索引標籤下。請參見端對端 RAPIDS 工作流程簡介。此頁面包含與 RAPIDS 函式庫有關的資訊,並概述了 notebook 涵蓋的內容。
以下是開始使用此資源中的範例 Jupyter notebook 的幾種方式:
- 下載資源
- 一鍵部署至 Vertex AI。
如果已經具有啟用 GPU 的本機或雲端環境,則可以下載資源,並在您的基礎架構上執行。但是,在本文章中,是使用一鍵部署功能在 Vertex AI 上執行 notebook,無須手動安裝您的基礎架構。
一鍵部署功能可以取得 Jupyter notebook、配置 GPU 執行個體、安裝相依性,並提供 JupyterLab 介面以開始使用。
設定受管理 notebook
遵循簡要教學,以確保正確設定環境。
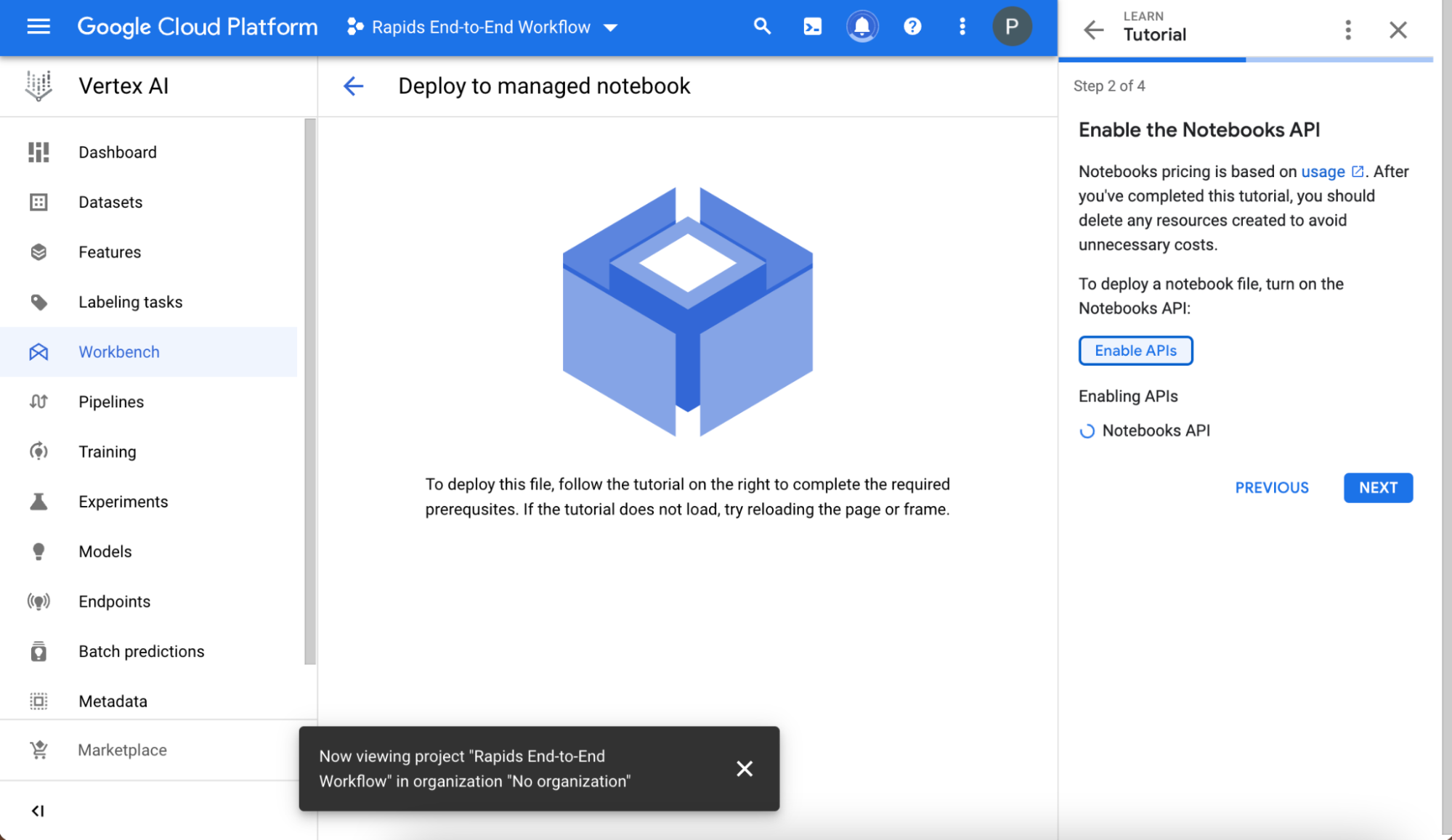
建立與命名專案,並在建立專案之後,於選擇專案欄位中選擇。記住專案名稱下方自動顯示的專案 ID 值,因為稍後將會使用。
然後,啟用 Notebooks API。
設定硬體
在選擇建立部署 notebook 之前,請選擇進階設定。下列資訊已預先配置,但是可以自訂,視資源要求而定:
- Notebook 名稱
- 地區
- Docker 容器環境
- 機器類型、GPU 類型、GPU 數量
- 磁碟類型和資料大小
在部署之前:
- 檢查以確保區域已預先配置 GPU。如果沒有 GPU,則會看到警告,且應變更區域。
- 確定已勾選自動幫我安裝 GPU 驅動程式按鈕。
現在一切都已就緒,且已具有 GPU 和驅動程式,請在頁面底部選擇建立。建立 GPU 運算執行個體及設定 JupyterLab 環境,大約需要數分鐘的時間。
啟動 Jupyter
選擇開啟 -> 開啟 JupyterLab,以啟動介面。JupyterLab 介面是從 NGC 提取資源(自訂容器和 Jupyter notebook)。提取核心可能需要一些時間,請耐心等候!
在載入後,即可從核心選擇器中選擇 RAPIDS 核心。在完成核心載入之後,按兩下左側窗格中的 notebook 名稱。
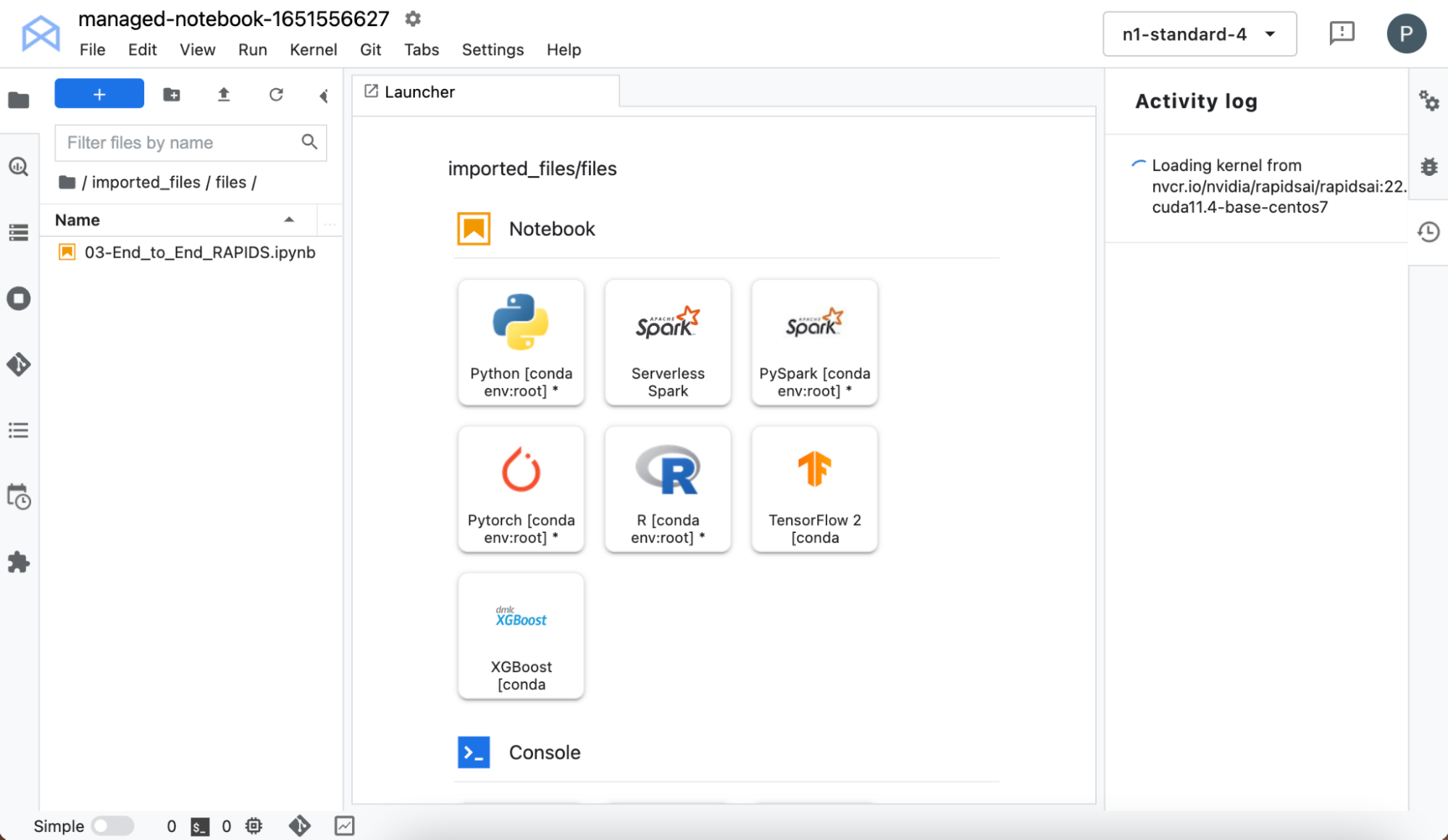
現在,您可以存取預先安裝 RAPIDS 函式庫的 notebook 環境,而無須設定自己的基礎架構,所以可以直接開始和自行嘗試。
使用工作流程
專案是使用來自紐約市 CitiBike 自行車共享計畫的資料。Notebook 本身提供了更多詳細資訊。
在深入探索資料處理之前,可以使用 NVIDIA SMI 命令查看與 GPU 有關的詳細資訊。將會顯示出預期的資訊:VertexAI 已分配 V100 T4 GPU,具有 16 GB 的記憶體。
必須安裝一些函式庫,以便從 Google BigQuery 載入資料。此資料集是在 BigQuery 上公開,所以不需要任何憑證即可載入。使用 Python API,從大型查詢載入資料。
將資料轉換成 cuDF 資料框架。cuDF 是 RAPIDS GPU DataFrame 函式庫,提供在 GPU 上有效率地轉換、載入及聚合資料時需要的一切。cuDF 資料框架是儲存在 GPU 上,這是其餘工作的資料保留位置。將可利用 GPU 的速度,以及降低在 CPU 與 GPU 之間傳輸的成本,提供大幅加速的效果。
在執行 notebook 之前,請將命令 os.environ.setdefault 取消註解,並將專案 ID 放入第二個引數。如果不記得設定專案時分配給專案的 ID 時,它會在您選擇專案後顯示在 Workbench 主頁上。請務必使用 ID,而不是名稱。
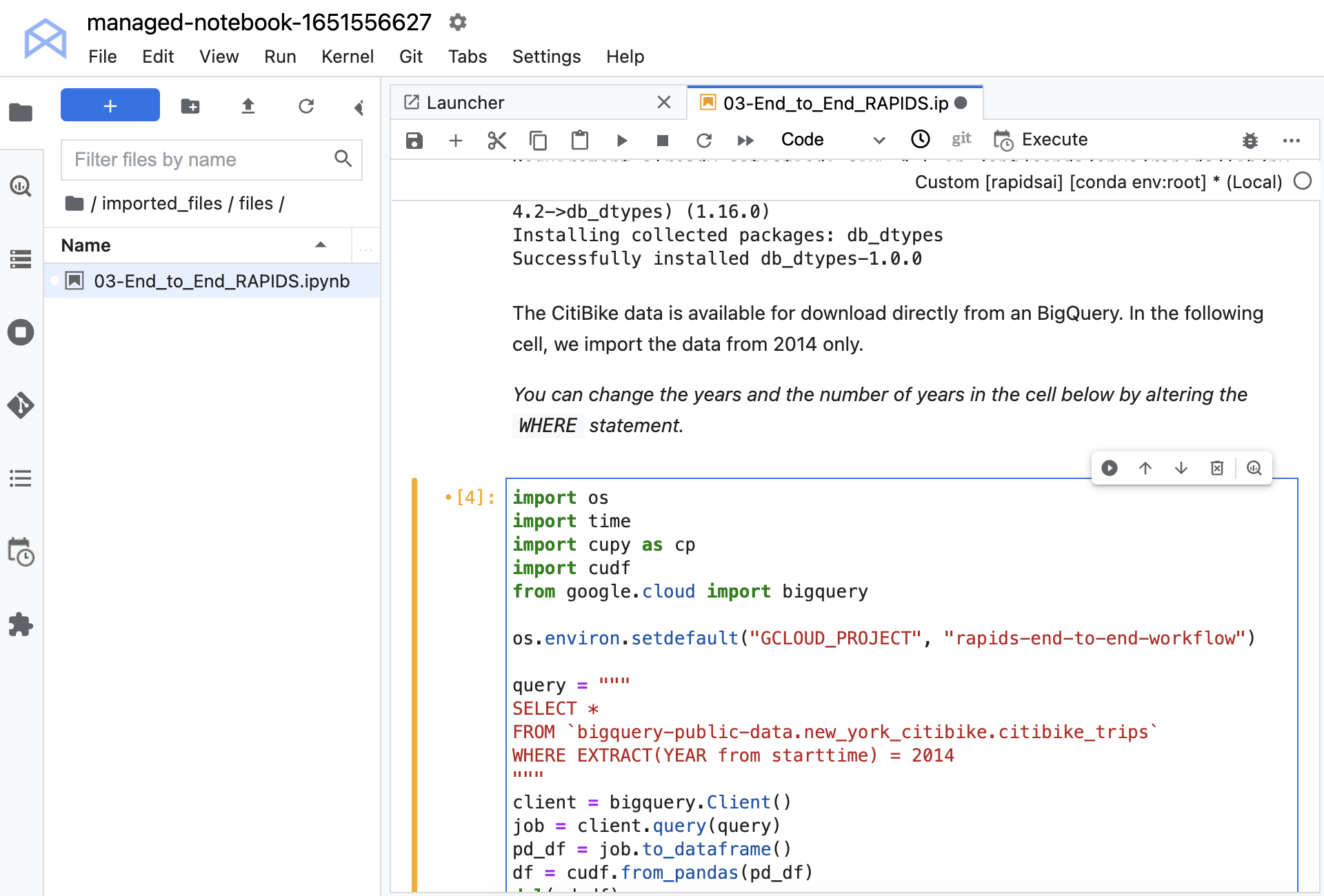
現在已載入資料。您可以檢查資料以及查看資料類型和特徵摘要。每一個項目都包含開始時間、停止時間、表示取車位置的站點 ID,以及表示還車位置的站點 ID。同時具有其他與自行車、取車和還車位置,以及使用者人口統計有關的資訊。
資料處理
在後續的單元中會處理資料,以建立特徵向量,這些向量擷取是用於訓練機器學習模型的重要資訊。
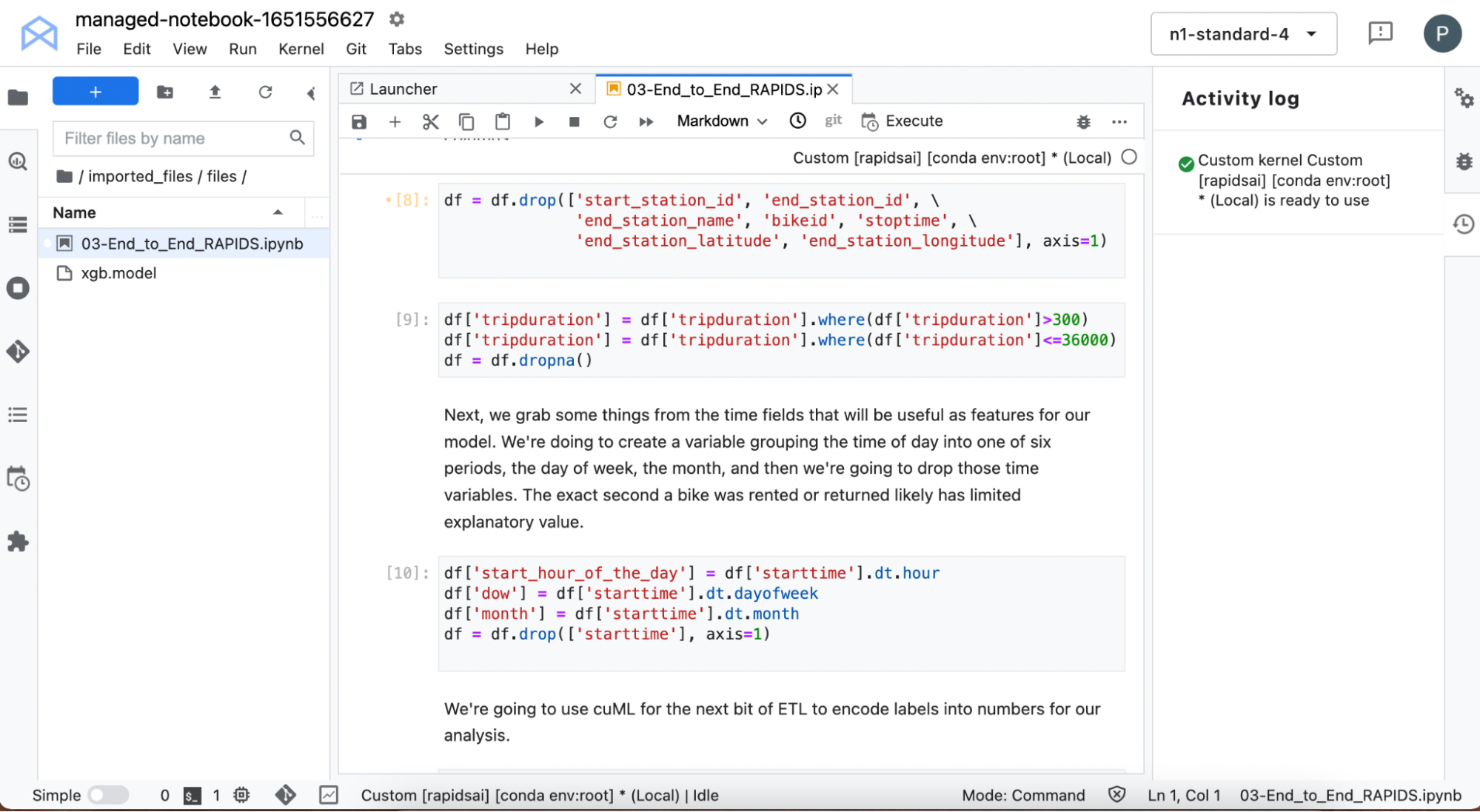
處理開始時間以擷取資訊,例如租用自行車的日期以及時間。從資料中移除所有的特徵,包含與騎乘結束有關的資訊,因為目標是在取車點預測騎乘持續時間。
同時可以過濾掉極短途騎乘(如立即歸還的故障自行車)以及持續超過 10 小時的極長途騎乘。城市自行車應使用於市區周圍相對較短的旅行,不適合長途旅行,所以不要讓這些資料扭曲模型。
使用一些 cuDF 內建時間功能擷取關於還車時間的詳細資訊。進行一些其他資料處理,例如使用 cuML為某些文字變數自動建立標籤編碼。
模型訓練
在之後訓練 XGBoost 模型。XGBoost 提供了一個 API,可以透過梯度提升決策樹進行訓練和推論。
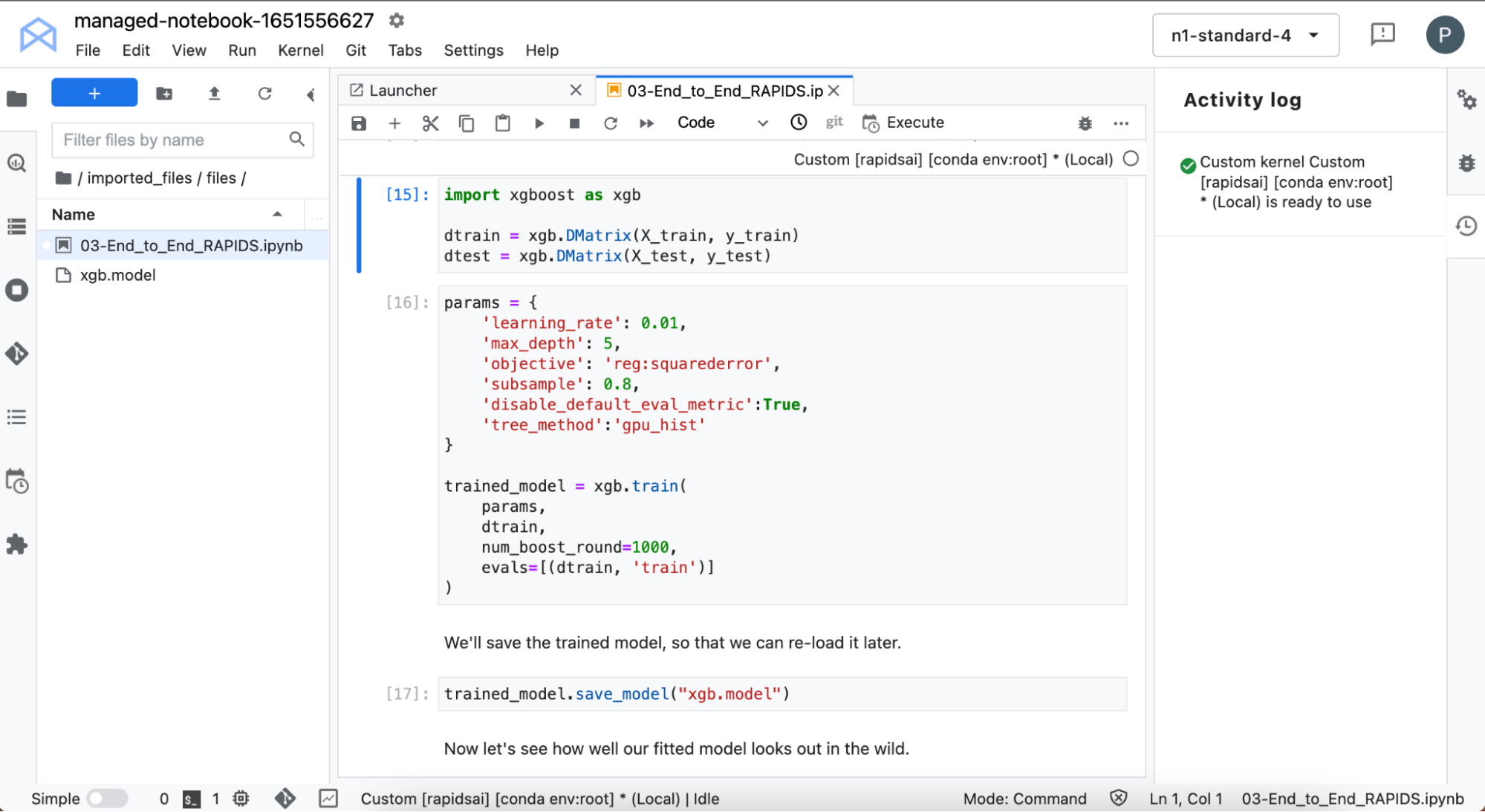
這是在 GPU 上訓練:超快速。直接從 cuDF 接受資料,無須變更格式。
既然已經訓練了模型,則可讓模型預測一些非訓練使用之資料的騎乘時間,並與基準真相進行比較。在未調整任何超參數的情況下,模型在預測騎乘時間方面的表現尚可。可以進行一些改進,但是現在先看一看哪些特徵影響了模型的預測。
模型解釋
當使用 XGBoost 等複雜的模型時,可能不容易理解模型的預測。在本節中,將使用 SHapley Additive exPlanation(SHAP)值深入分析機器學習模型。
計算 SHAP 值的運算成本高昂,但是可以在 NVIDIA GPU 上執行,以加快此過程。請在資料子集上計算 SHAP 值,以節省更多時間。
之後,查看個別特徵的影響以及特徵的組合。
加快推論
訓練模型通常被視為工作流程中運算成本高昂的部分,所以 GPU 可以在此時發揮價值。在實務中的確如此。但是 GPU 也可以大幅加快對某些模型進行預測需要的時間。
重新載入模型,因為 XGBoost 針對先前的預測進行快取,並在 CPU 和 GPU 上進行預測時開始計時。
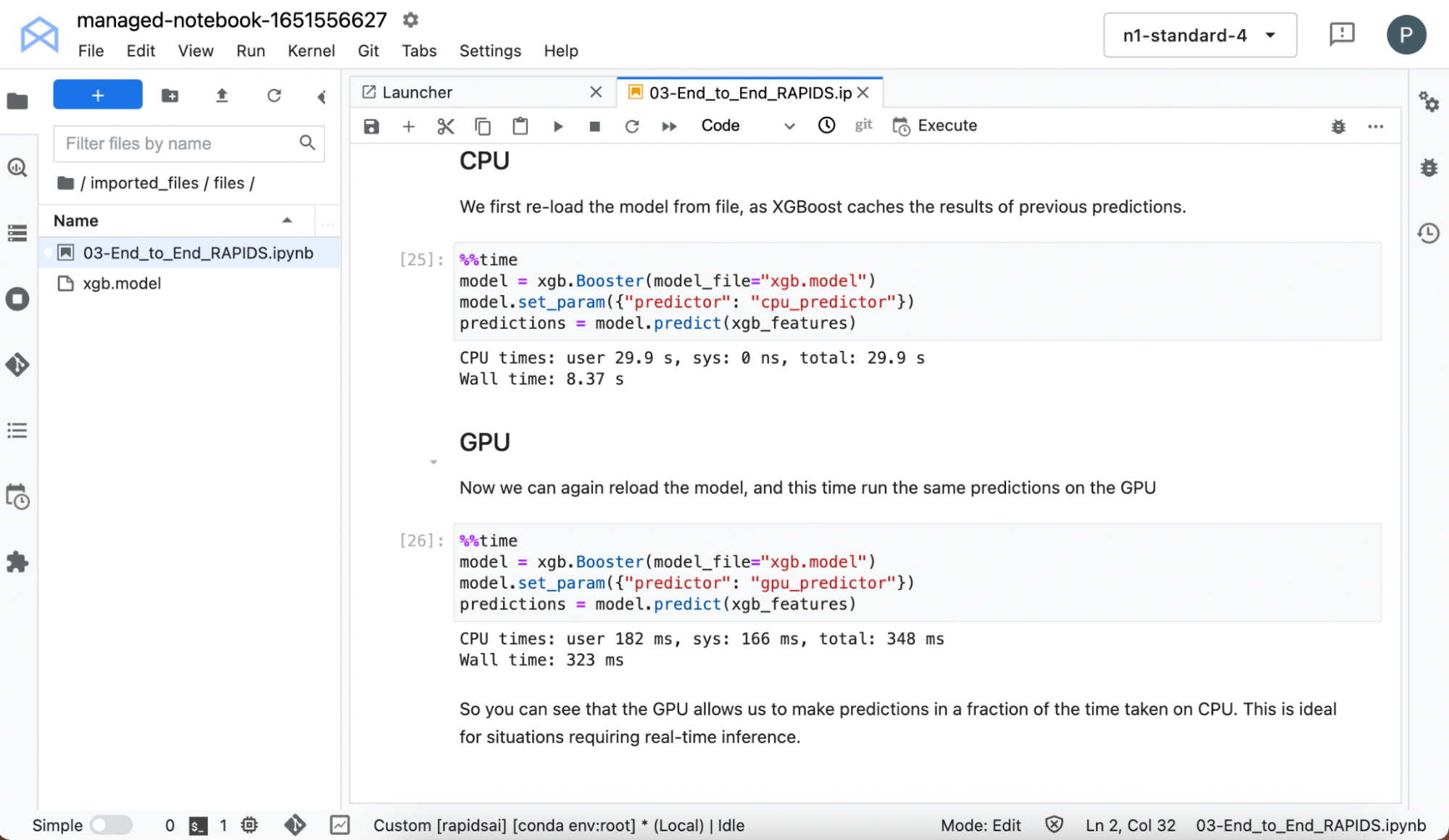
即使在小型資料集和簡單模型上,也可以看到在 GPU 上執行時,推論大幅加速。
結論
RAPIDS 讓您可以在 GPU 上執行端對端工作流程,考量更複雜的技術以及更快洞悉資料。
利用 NGC 目錄的一鍵部署功能,可以在短短數分鐘內存取 RAPIDS 環境及開發機器學習工作流程,而無須啟動您的基礎架構或自行安裝函式庫。
輕鬆上手!依據這些步驟,可以加快所有的資料科學工作,免除設定基礎架構的麻煩。
深入瞭解 RAPIDS,並在 Twitter 上聯繫 RAPIDS 團隊。當然,請搜尋 NGC 目錄,以取得更多易於部署的模型和範例。