如果曾撥打「123」致電中華電信 24 小時客服專線,應該都有體驗過全台首創聲音互動人工智慧(AI)客服,其藉由擬真的語音系統提供自助式客服,或是協助轉接專人客服,以解決進一步的需求。而這套系統背後採用的便是 NVIDIA 超大規模模型推論解決方案 Triton 推論伺服器,搭配旗下 GPU 加速深度學習系統,讓中華電信能以更高的效率完成語音模型訓練,進而建構高自然度的擬真語音互動體驗。
更擬真的客服專線,原本需要長時間訓練建立
中華電信研究院前瞻科技研究所所長汪世昌表示:「目前中華電信自行研發的中英雙語語音合成技術,歷年來已應用於多個領域,除了用在 24 小時客服專線,更應用在 166、167 天氣預報、視障輔助等相關應用,以及中華電信旗下i寶貝智慧音箱、AI 語意雲、智慧廣播助理等服務,同時也用於健保署、消防署的語音服務系統。」
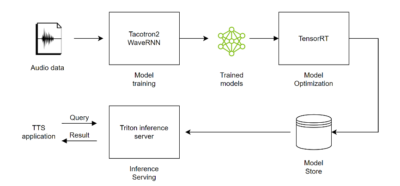
在還沒有導入 AI 技術時,中華電信就已著手投入擬真數位語音技術研究,從早期藉由語音拼接進行合成,以及後續透過語音參數方式進行合成,到現在已經可以利用深度學習等 AI 技術,透過足夠時間長度規模的聲音資料,以及相應的文字內容,訓練合成高度自然的語音模型,唯獨整個訓練流程仍須花費較長時間。
以目前深度神經網路 (Deep Neural Network;DNN) 技術推動的語音合成效果,已經可以實現逼近真人語調般的自然表現,但是藉由自我迴歸模型 (Autoregressive Model) 生成詮釋聲音語調特徵的梅爾頻譜 (Mel-Spectrogram),再透過人聲編碼器 (Vocoder) 合成語音內容的過程,往往需要處理大量資料數據,使得整體合成時間變得更長,因此與預期應用在實際服務上的流暢度表現將有所落差。
加上若要打造跨語言的語音系統,過去的作法是透過多種語音系統對應不同語言內容,但會導致不同語言內容以不同音色呈現,而造成使用體驗不一致,因此會透過同一人錄製多種語言的語音資料,藉此建立相同音調的語音系統。
不過,在此需求情況下,更代表需要花費更長時間進行訓練,才能順利建立出像是中華電信此次釋出的中英雙語語音合成模型,並順利應用在各類語音服務上。
借助NVIDIA技術大幅縮短訓練時間
汪世昌表示,將數位合成的語音系統用於客服,太重的機器合成語感會嚴重影響使用者的互動意願,尤其目前越來越多服務仰賴語音互動,自然的語感表現更容易吸引使用者互動。
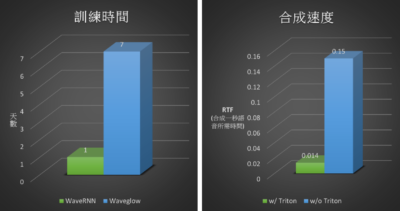
不過,要打造自然語感的合成語音表現,自然需要龐大的資料量進行深度訓練,以過往訓練模式須花費更長時間完成,但是藉由導入NVIDIA超大規模模型推論解決方案 Triton 推論伺服器,並搭配 TensorRT 深度學習推論平台,以及透過 GPU 加速的 cuDNN 函式庫等資源,同時,藉由NVIDIA Elite合作夥伴豐康科技協助導入 NVIDIA 的硬體設備,包括 NVIDIA DGX-1 超級電腦、RTX A6000 GPU 與多張 NVIDIA T4 Tensor 核心 GPU 等進行運算,即可讓原本需要花費多時才能完成的模型訓練,縮短至 1 天即可完成,更可在整個訓練過程中降低成本支出。
如此一來,即便語音模型需要重新訓練,或是加入不同參數等,都能在更短的時間內完成,藉此讓合成語音系統能更符合實際應用需求、同時也更自然,甚至反應速度更快。
擬真語調只是初期應用,未來計畫創造可聊天互動的 AI 對話系統
不僅侷限在中、英兩種語言,汪世昌進一步說明目前還有台語與客語,未來也會因應市場需求加入更多語言,以及語意理解與上下文銜接,讓數位語音系統可以結合 AI 對話助理,藉此實現更廣泛的代理服務應用模式,例如從當前的電話客服系統,進一步衍生能夠依照致電者需求自然應答的語音互動模式,讓餐廳等商家可以在無須增加人手的情況下,即可透過語音系統接下更多訂單或處理更多訂位需求。

汪世昌認為,由 AI 對話助理提供大量資料彙整分析的知識問答服務,可將傳統客服人力應用在需要更準確解決問題的情況,例如直接由 AI 對話助理協助回答哪些方案適合消費者當前的使用需求,而在此基礎下可以直接提供精準的漫遊方案選購建議,而其他人員則可聚焦在技術問題處理,或是較複雜的客訴情況。
為了建立更有智慧的 AI 對話助理,需要更龐大的資料與知識問答進行訓練,並且透過更強的算力縮短整體訓練時間,因此未來中華電信也會持續與 NVIDIA 合作,並藉其解決方案創造更符合自然語調、精準正確的語音互動體驗。
免費開放中英雙語語音合成模型及語料庫,希望推動更多台灣在地化智慧語音發展
而此次對外免費開放的中英雙語語料庫,計畫於 Q3 前發布在 NVIDIA DeepLearningExample 開源平台,主要是由一名女性專業錄音員錄製總長達 4.5 小時、總計 2,740 段中英雙語內容,內容更以科技產品相關語句為主,成為亞洲地區第一個免費開放使用的中英雙語語料庫,藉此讓更多業者能夠打造符合台灣人使用的語音系統,同時推動更多以語音為互動的 AI 應用發展。
汪世昌進一步表示,主要考量目前市面上適合中英雙語使用的語言模型資料稀少,同時取得成本較高、取得管道也相對複雜,因此希望透過此次釋出的開放中英雙語語音合成模型及語料庫,催化台灣產學研界打造更好的語音合成應用,未來也期待能透過更多「廣結盟」合作,強化本土技術應用發展。