
眾家企業刷新訓練人工智慧 (AI) 模型速度的紀錄,包括戴爾科技 (Dell Technologies)、浪潮 (Inspur Electronic Information)、美超微 (Supermicro),以及首度在 MLPerf 基準測試中亮相的 Azure,均採用 NVIDIA AI。
我們的平台在今日公布的 MLPerf 訓練 1.1 結果中,創下所有八項熱門作業負載中的紀錄。
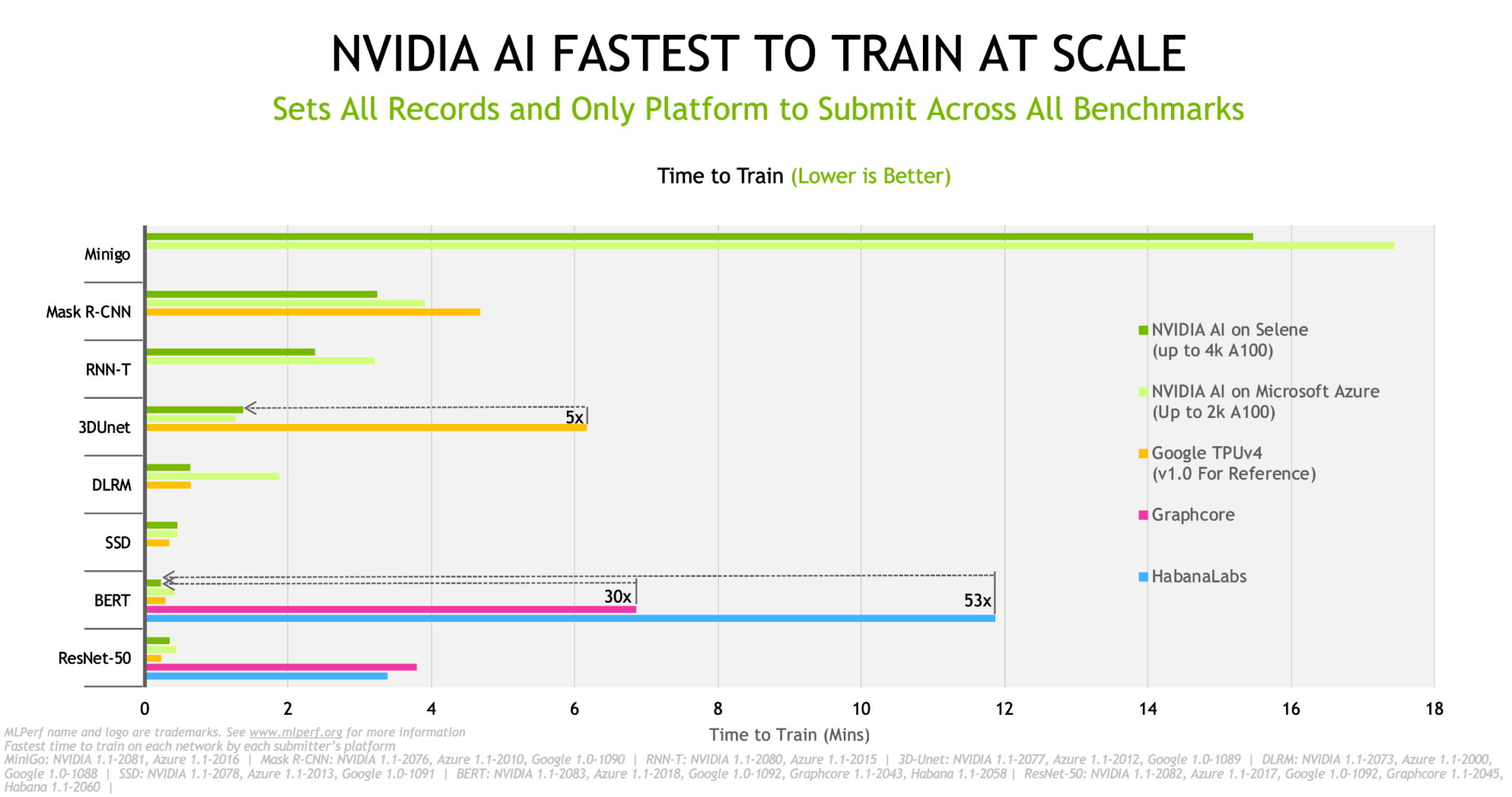
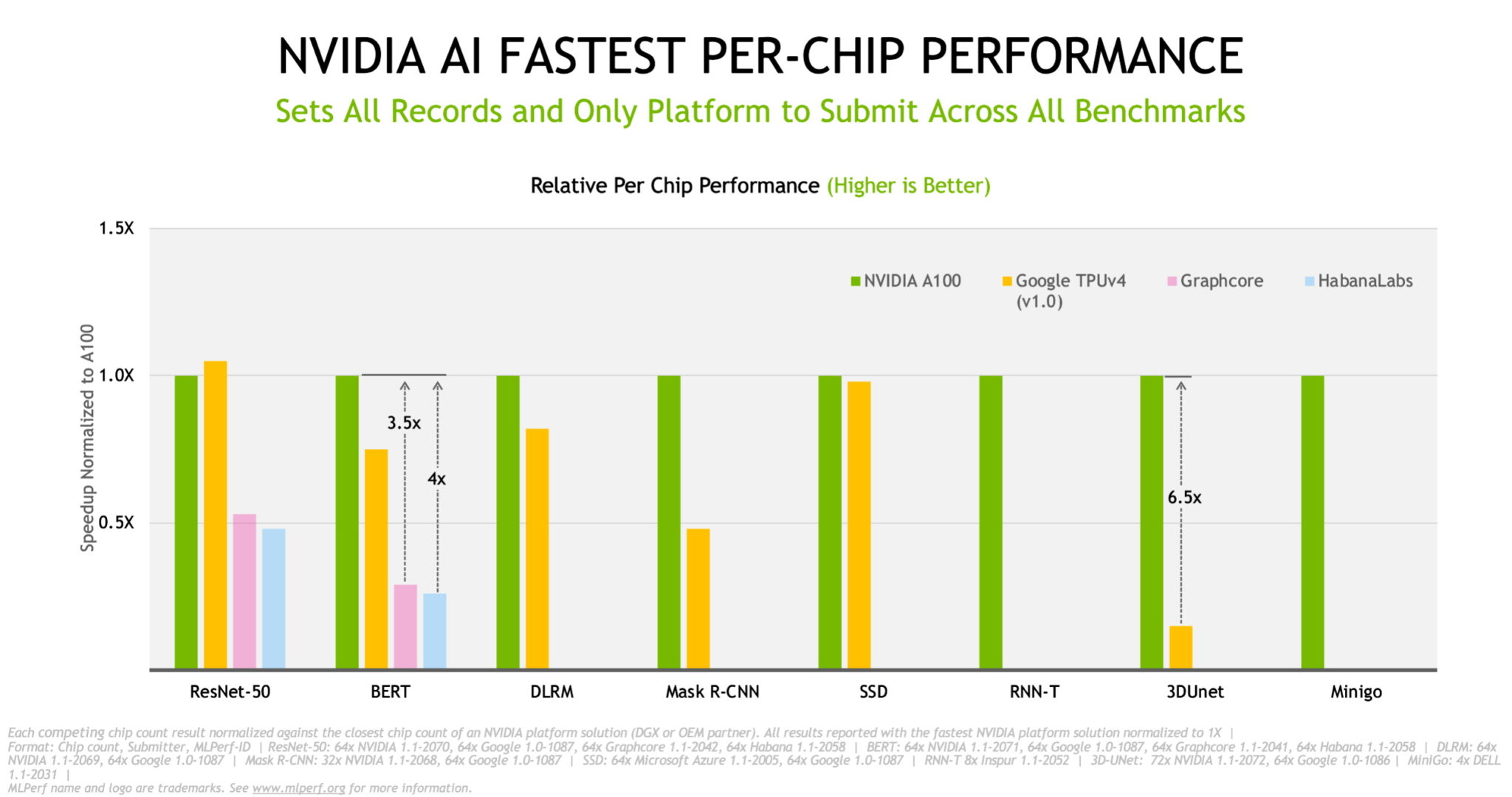
NVIDIA A100 Tensor 核心 GPU 不僅提供最佳的標準化單晶片效能,並透過 NVIDIA InfiniBand 連網技術及軟體堆疊進行擴充,在 Selene 系統上提供最快的訓練時間。Selene 是 NVIDIA 基於模組化 NVIDIA DGX SuperPOD 的 AI 超級電腦。
邁向巔峰的雲端
根據最新公布的結果,在訓練 AI 模型方面,Azure 的 NDm A100 v4 是當今全球最快的執行個體。其在最新一輪完成每一項測試,並能擴充至 2,048 個 A100 GPU。
Azure 不僅展現絕佳的效能,現在更於全美六個地區供任何人租用與使用。
AI 訓練是一項艱鉅的任務,因此需要強大的軟硬體支援。我們希望用戶能運用其所挑選的服務或系統,在破紀錄的速度下完成模型訓練。因此,我們透過 NVIDIA AI 為雲端服務、託管服務,以及企業與科學運算中心提供產品支援。
伺服器製造商展現強大的實力
在 OEM 廠商中,浪潮運用其 8 個 (8-way) GPU 系統,包含 NF5488A5 與液體冷卻 NF5688MB,刷新最多單節點效能紀錄。戴爾科技與美超微則憑藉搭載 4 個 (4-way) A100 GPU 的系統刷新紀錄。
此次共有十家 NVIDIA 合作夥伴提交測試結果,包含八家 OEM 廠商及兩家雲端服務供應商,其所提交的件數占總數 90% 以上。
這是第五輪的效能測試,也是至今 NVIDIA 商業生態系在 MLPerf 效能訓練基準測試中表現最為亮眼的一次。
我們的合作夥伴積極參與這項測試,因 MLPerf 是唯一業界標準且經同業審核的 AI 訓練與推論基準,其為客戶評估 AI 平台和廠商的寶貴工具。
速度經過認證的伺服器
百度 Paddle Paddle、戴爾科技、富士通 (Fujitsu)、技嘉 (GIGABYTE)、慧與科技 (Hewlett Packard Enterprise;HPE)、浪潮、聯想 (Lenovo) 以及美超微皆提交於單節點和多節點的本地端資料中心測試結果。
幾乎所有我們的 OEM 合作夥伴皆在 NVIDIA 認證系統上執行效能測試,我們為需要加速運算的企業客戶進行伺服器驗證。
各方提交的結果展現出 NVIDIA 平台應用的廣度與成熟度,並且能為任何規模的企業提供最佳的解決方案。
既快速又具彈性的系統
NVIDIA AI 是唯一提交數據於所有測試項目與使用案例的平台參與者,充份展現 NVIDIA AI 的多元性及絕佳效能。既快速又具彈性的系統,提供客戶加快作業速度所需的生產力。
訓練基準測試涵蓋當今最熱門的八項 AI 作業負載與情境,包括電腦視覺、自然語言處理、推薦系統,以及強化學習等。
MLPerf 的測試透明且客觀,因此用戶可以依據結果做出採購決策。此業界基準測試小組成立於 2018 年 5 月,並取得數十家業界領導廠商的全力支持,包括阿里巴巴 (Alibaba)、安謀 (Arm)、Google、英特爾 (Intel),以及 NVIDIA 等。
三年內速度提升 20 倍
過往的測試數據顯示我們的 A100 GPU 於過去 18 個月內效能提升 5 倍。這都要歸功於持續創新的軟體,而這也是我們近期著重發展的領域。
自三年前 MLPerf 測試推出以來,NVIDIA 的效能提升超過 20 倍。如此可觀的加速反映出我們在 GPU、網路、系統,以及軟體的全端產品中取得的進步。

持續優化的軟體
我們的最新進展來自多方面的軟體優化。例如採用全新類別記憶體複製模式,讓我們在醫學成像的 3D-Unet 基準測試中創下2.5 倍的速度提升。
藉由針對平行處理校正 GPU 的方法,我們在物體偵測的 Mask R-CNN 測試中獲得 10% 的速度提升,並在推薦系統中獲得 27% 的提升。我們將這些重複運用在各項獨立測試,而在涉及多 GPU 運算作業時尤其能反映出加速成效。
我們擴大 CUDA 繪圖的運用以盡可能縮短與主機 CPU 的傳輸時間,使得在影像分類的 ResNet-50 項目中獲得 6% 的效能提升。
此外,我們亦在 NCCL 執行兩項全新技術,其為最佳化 GPU 間傳輸作業的函式庫,讓 BERT 等大型語言模型獲得 5% 的效能提升。
運用我們努力的成果
我們使用的所有軟體皆能透過 MLPerf 資料庫取得,因此所有人都能取得我們世界級的研發成果。我們持續將這些最佳化結果整合至我們的 GPU 應用程式軟體中心 NGC 上的各項容器。
這些成果是全端平台的一部分,於最新發表的業界基準測試取得認證,並可透過各領域的合作夥伴取得,以處理當今的 AI 作業。