資料在建立智慧應用程式中扮演關鍵角色。想要建立高效率人工智慧(AI)/機器學習(ML)應用程式時,必須使用高品質、有標籤的資料集訓練機器學習模型。從零開始產生和標記此類資料,一直是企業的關鍵瓶頸。許多公司都是選擇一站式解決方案,支援從資料產生、資料標記、模型訓練/微調,到部署的 AI/ML 工作流程。 為了加快開發人員的端對端工作流程,NVIDIA 與許多專門產生龐大、多樣與高品質之有標籤資料的合作夥伴合作。他們的平台可以與 NVIDIA TAO 工具套件和 NVIDIA NeMo 完美整合,以訓練和微調模型。之後即可使用 NVIDIA DeepStream 或 NVIDIA Riva,部署這些經過高效率訓練和最佳化的模型,建立可靠的電腦視覺或對話式 AI 應用程式。
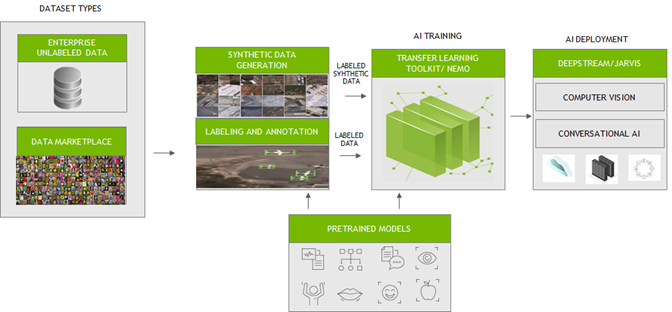
本文章概述了資料準備和訓練的主要挑戰。我們同時將介紹如何透過我們的合作夥伴服務,輕鬆整合資料,以微調 AI/ML 模型。
電腦視覺
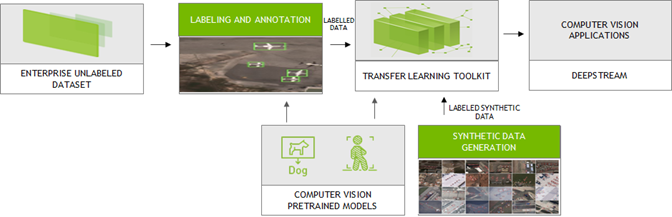
訓練電腦視覺神經網路模型,需要大量的有標籤資料。這些資料可以從真實世界收集或透過模型進行合成。高品質有標籤資料,使神經網路模型可以將資訊脈絡化及產生準確的結果。 NVIDIA 與以下合作夥伴的平台整合,產生和標記採用 TAO 工具套件相容格式的合成自訂資料進行訓練。TAO 工具套件是採用針對預先訓練模型的零編碼轉移學習工具套件。可以使用 DeepStream SDK 部署已訓練的模型,將開發時間加快 10 倍。
AI Reverie 和 Sky Engine
合成有標籤資料已逐漸普及,尤其是物件偵測、影像分割等電腦視覺任務。利用 AI Reverie 和 Sky Engine 的平台,可以產生合成有標籤資料。AI Reverie 提供的合成資料套件,是使用 3D 環境進行模型訓練和驗證,將神經網路模型暴露在從真實世界收集之資料中無法找到的各種情境下。Sky Engine 使用光線追蹤影像渲染器技術,在虛擬環境中產生能與 TAO 工具套件搭配使用,以進行訓練的有標籤合成資料。
Appen
透過 Appen,可以產生和標記自訂資料。Appen 是使用 API 和人類智慧產生有標籤訓練資料。Appen 資料註解平台和服務與 NVIDIA TAO 工具套件整合,可以節省耗時的註解及建立適合的訓練資料,以針對使用案例,透過 TAO 工具套件進行訓練。
Hasty、Labelbox 及 Sama
少數供應商提供簡單的標註工具。僅需要在影像上按幾下,並選擇物件周圍的區域,即可快速產生標註。透過 Hasty、Sama 及 Labelbox,可以標記採用 TAO 工具套件相容格式的資料集。 Hasty 提供 DEXTR、GrabCut 等工具,建立有標籤資料。使用 DEXTR,僅需要按一下物件的東、西、南、北,神經網路就會尋找遮罩。透過 GrabCut,可以選擇物件所在區域及新增或移除有標記的區域,以改善結果。 使用 Labelbox,可以上傳想要註解的資料,並使用 Python SDK,輕鬆地將已註解資料匯出至 TAO 工具套件進行訓練。 Sama 遵循不同的標記機制,並使用經過預先訓練的物件偵測模型(圖 2)執行推論。IT 可以使用這些註解進一步加強標籤,以產生準確的結果。 這些工具與 TAO 工具套件緊密結合進行訓練,以開發生產品質的視覺模型。
對話式人工智慧
典型的對話式 AI 應用程式,可能具備自動語音辨識(automatic speech recognition,ASR)、自然語言理解(natural language understanding,NLU)、對話管理(dialog management,DM)和文字轉語音(text-to-speech,TTS)服務。對話式 AI 模型龐大與需要大量資料進行訓練,才能在嘈雜之環境中辨識不同的語言或口音、理解語言的每一個細微差別,並產生擬人語音。 NVIDIA 與 DefinedCrowd、LabelStudio 和 DataSaur合作。您可以使用他們的平台建立大型有標籤資料集,然後直接導入 NVIDIA NeMo 進行訓練或微調。NeMo 是開發先進對話式 AI 模型的開放原始碼工具套件。您可以輕鬆地將 NeMo 模型匯出至 Riva 進行推論,將可在不到 300 毫秒的時間內,執行端對端對話式 AI 工作流程。
DefinedCrowd
外包是產生/標記資料的常見方法。DefinedCrowd 是透過線上平台 Neevo,將專案分成一連串的微型任務,利用來自全球超過 500,000 位貢獻者,收集、標註和驗證訓練資料。之後使用資料訓練各種語言、口音和領域的對話式 AI 模型。現在,可以使用 DefinedCrowd API 快速下載資料,並轉換成 NeMo 可以接受的格式,以進行訓練。
LabelStudio
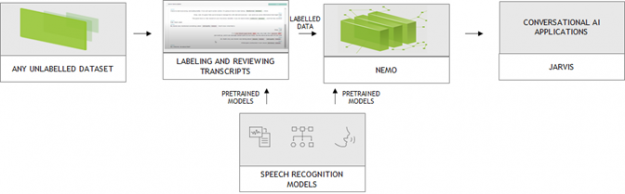
機器學習模型的進步,使 AI 輔助資料標註成為可能,進而大幅降低了標記成本。越來越多供應商開始整合 AI 功能,以擴增標記流程。NVIDIA 與 Heartex 合作,由 Heartex 負責維護開放原始碼 LabelStudio,並執行適用於語音的 AI 輔助資料標註。現在可以利用此工具,標記與 NeMo 相容的語音資料(圖 3)。Heartex 同時將 NeMo 整合至他們的工作流程中,以使您能選擇經過預先訓練的 NeMo 模型進行語音預先註解。
Datasaur
在文字標記方面,有一些簡單易用的工具可以提供預先定義標籤,讓您能快速地為資料加上註解。欲深入瞭解如何為文字資料加上註解以及執行 Datasaur 與 NeMo,以進行訓練,請觀看 Datasaur x NVIDIA NeMo 整合 影片。
結論
NVIDIA 與許多領先業界的資料產生和註解供應商合作,以加快電腦視覺與對話式 AI 應用程式工作流程。此合作讓您可以快速產生優質資料,立即將資料與 TAO 工具套件和 NeMo 搭配使用,以訓練模型,然後透過 DeepStream SDK 和 Riva 在 NVIDIA GPU 上部署模型。 若需要更多資訊,請參閱以下資源: