在過去幾個月,許多人已經習慣透過視訊通話就醫。當然這是一種很方便的方法,但是在通話結束之後,就開始忘記醫師提出的重要建議。我需要服用什麼新藥?是否需要注意任何副作用?
對話式 AI 可以協助建構轉錄語音,將語音文字化,並將轉錄中的關鍵短語特別標出。NVIDIA Riva 是一個強大的平台,可以加速建構和部署此類任務的先進深度學習模型。
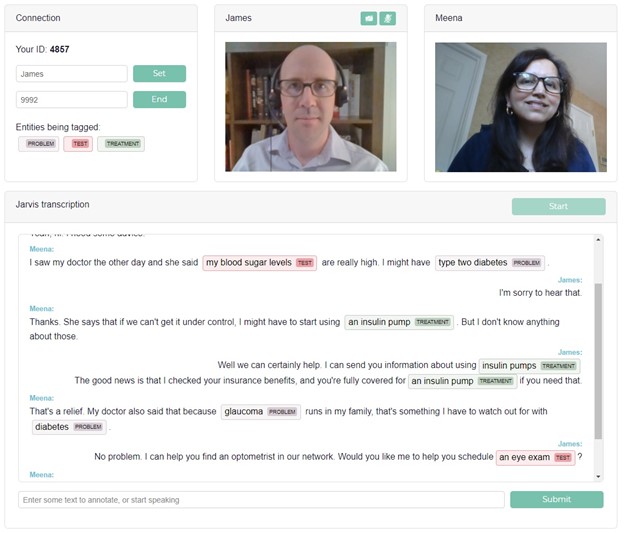
本文將說明如何建構即時視訊語音轉錄的網頁應用程式,並標記轉錄中之關鍵短語。視訊聊天使用的 PeerJS,是以 WebRTC 為基礎的開放原始碼點對點聊天框架。即時轉錄則是使用來自 Riva 的自動語音辨識(automatic speech recognition,ASR)。標記轉錄中的關鍵短語,是使用同樣來自於 Riva 的命名實體辨識(named entity recognition,NER)。我們將會示範如何使用來自醫學領域的資料,訓練 NER 模型。雖然已包含程式碼範例,但是為了能更清楚說明,我們將省略一些技術細節。因此,建議您參考 Riva 範例 Docker 容器。
此應用程式的起點,是一個簡單的點對點視訊通話網頁應用程式。包含下列資源:
- 一個 HTML 頁面
- 一個用戶端 JavaScript 檔案
- 一個伺服器 JavaScript 檔案,用於主控資產和建立點對點連線
我們是提供最基本的教學,請注意,實際的應用程式應該會更複雜。其將包括身分和工作階段管理、警報、分析,以及更穩健的網路處理。

本文是著重於如何為網頁應用程式增加 ASR 和 NLP 功能,並省略一些與應用程式結構有關的細節。概述一下此應用程式,它是一個簡單的伺服器,建置於 Node.js 中,使用 Express 主控網頁資產,以及使用 PeerJS 協助用戶端在點對點 WebRTC 視訊聊天中互相連線。在用戶端,瀏覽器會載入網頁,然後與伺服器對話,以協助建立與對方的連線。在建立該連線之後,兩個用戶端即可直接互相通訊。無須再透過伺服器傳遞視訊。
目前,使用者可以載入網頁、聯繫其他使用者以及進行即時視訊聊天。
增加 ASR 和 NLP
NVIDIA Riva 是可以快速部署高效能對話式 AI 服務的 SDK。Riva Quick Start 資源為部署至 Riva 推論伺服器提供了易於遵循的指南。將資源下載至伺服器後,需要幾個基本步驟:
- 在 config.sh 中配置部署。
- 執行 riva_init.sh,以下載、最佳化和準備模型。
- 使用 riva_start.sh 啟動 Riva 技能伺服器。
在啟動伺服器之後會建立多個 gRPC 端點,協助應用程式與 Riva 通訊。請嘗試從建立 Riva 的伺服器啟動用戶端容器,以確保一切都正常運作。呼叫 riva_start_client.sh,然後查看範例用戶端、探索 notebook,並瞭解 Riva 提供的功能。
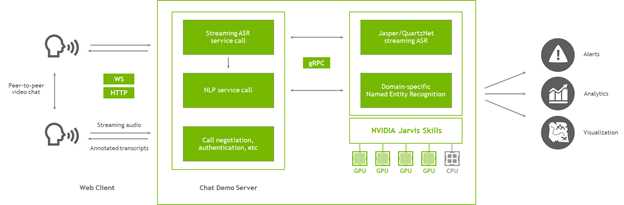
圖 3 為應用程式的主要元件,現在已增加 Riva。聊天示範伺服器(即為 Node.js 應用程式)持續在建立視訊通話,且現在也能與 Riva 伺服器通訊。
在應用程式中,使用 Riva 執行兩項功能:取得對話的串流轉錄,以及標記該轉錄中的關鍵短語(命名實體)。使用方式為從用戶端擷取音訊資料流,然後將該音訊傳遞至 Node.js 伺服器。伺服器是使用 gRPC 呼叫 Riva,以取得轉錄和命名實體,並將結果傳遞回用戶端。之後,用戶端可以在瀏覽器中呈現轉錄,並透過點對點連線傳遞轉錄,讓兩個使用者都可以查看整個對話。
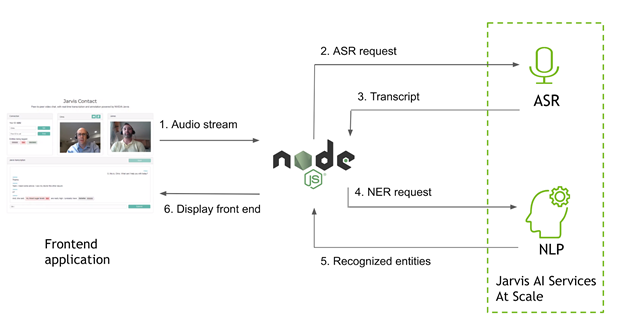
從網頁用戶端取得音訊
在用戶端,可以利用傳送給對方進行視訊聊天的本機 WebRTC 資料流,存取音訊資料流。當使用者選擇開始時,在用戶端 JavaScript 檔案中,將 Riva 與伺服器的連線初始化。首先確保已啟用通訊端,以便能透過通訊端連線傳送音訊資料:
socket = socketio.on('connect', function() {
console.log('Connected to speech server');
});
WebRTC 音訊是以處理圖表的概念運作。想要在瀏覽器中處理音訊時,請執行下述步驟:
- 從本機視訊聊天資料流連接至音訊來源。
- 建立處理節點,以處理該音訊。
- 在開始之前,將新節點連接至音訊的原始目的地。
在每一次獲得進入新處理節點的完整音訊緩衝區時,請使用網頁工作執行緒進行重新取樣,並透過通訊端連線,將重新取樣的緩衝區傳送至伺服器。建立音訊來源連線,並將重新取樣器初始化:
audio_context = new AudioContext();
sampleRate = audio_context.sampleRate;
let audioInput = audio_context.createMediaStreamSource(localStream);
let bufferSize = 4096;
let recorder = audio_context.createScriptProcessor(bufferSize, 1, 1);
let worker = new Worker(resampleWorker);
worker.postMessage({
command: 'init',
config: {
sampleRate: sampleRate,
outputSampleRate: 16000
}
});
每一次緩衝區填滿時,瀏覽器都會觸發事件,所以請指示處理器節點如何處理。使用工作執行緒進行重新取樣,然後使用通訊端連線,將其傳遞至伺服器。
recorder.onaudioprocess = function(audioProcessingEvent) {
let inputBuffer = audioProcessingEvent.inputBuffer;
worker.postMessage({
command: 'convert',
// You only need the first channel
buffer: inputBuffer.getChannelData(0)
});
worker.onmessage = function(msg) {
if (msg.data.command == 'newBuffer') {
socket.emit('audio_in', msg.data.resampled.buffer);
}
};
};
在將音訊傳送至 Riva 之前,無須針對音訊進行重新取樣。Riva 可以自行進行重新取樣。但是,在瀏覽器中執行,可以降低頻寬需求,以及簡化記錄來源之間的某些差異。現在,可以將新的處理器節點連接至音訊圖表,包括來源音訊和目的地:
audioInput.connect(recorder); recorder.connect(audio_context.destination);
截至目前為止,應用程式可以從使用者的麥克風提取音訊、針對資料流進行重新取樣,然後使用通訊端,將重新取樣的音訊傳送至伺服器。其次,說明如何在伺服器上使用此音訊。
將音訊傳遞至 Riva
在 Node.js 中建置主要伺服器指令碼,使用 Express 伺服器和 Socket.IO 處理傳入的連線。在初次連接通訊端時,請建立 Riva 連線。
io.on('connect', (socket) => {
console.log('Client connected from %s', socket.handshake.address);
// Initialize Riva
socket.handshake.session.asr = new ASRPipe();
socket.handshake.session.asr.setupASR();
socket.handshake.session.asr.mainASR(function(result){
var nlpResult;
if (result.transcript == undefined) {
return;
}
// Final transcripts also get sent to NLP before returning
if (result.is_final) {
nlp.getRivaNer(result.transcript)
.then(function(nerResult) {
result.annotations = nerResult;
socket.emit('transcript', result);
}, function(error) {
result.annotations = {err: error};
socket.emit('transcript', result);
});
} else {
socket.emit('transcript', result);
}
});
});
此時需要完成一些事項。建立新的 ASRPipe ,並附加至通訊端的 handshake.session 物件,以使個別的 Riva 資料流與各個用戶端連線具關聯性。使用 setupASR 進行一些基本的 Riva 設定,然後啟動 ASR 聆聽迴圈。
ASR 聆聽迴圈具有非同步性質。定期向其傳送大量的音訊資料,並透過回呼函式定期傳送結果。回呼是傳遞至 mainASR 的函式。在串流模式下,Riva 可以傳送兩種結果:隨著更多音訊進入(提供更多脈絡)而改變的臨時假設,以及最終轉錄。當音訊中出現短暫停頓時,例如說話者喘一口氣,轉錄就會以「最終」形式回傳。將兩種結果傳送回用戶端,但是會在獲得最終結果時,將這些轉錄傳送至 NLP 服務,以進行 NER。兩者都是使用 transcript 事件,透過相同的通訊端連線,將結果傳遞回用戶端。
使用 Socket.IO,為特定事件設定聆聽器。先前提到其中一個事件:在用戶端傳送大量音訊資料時觸發的 audio_in 事件。在伺服器端,將聆聽器增加至用於初始化 Riva的同一個 io.on(‘connect’) 範圍。
socket.on('audio_in', (data) => {
socket.handshake.session.asr.recognizeStream.write({audio_content: data});
});
此部分很簡單,因為需要做的事不多。由於已設定連接通訊端時的 Riva 資料流,因此僅需要傳遞新的音訊內容。
傳送語音辨識要求
現在,從 ASR 開始檢視 gRPC 介面本身。在使用 Node.js 連線至 gRPC 服務時,需要執行三個主要步驟:
- 使用協定緩衝區匯入 Riva API。
- 針對 API 編寫便利函式。
- 在用戶端與 Riva 函式之間中介資料。
在 asr.js 模組中定義先前呼叫的 ASRPipe 類別,首先匯入 Riva API:
const jAudio = require('./protos/src/riva_proto/audio_pb');
var asrProto = 'src/riva_proto/riva_asr.proto';
var protoOptions = {
keepCase: true,
longs: String,
enums: String,
defaults: true,
oneofs: true,
includeDirs: [protoRoot]
};
var asrPkgDef = protoLoader.loadSync(asrProto, protoOptions);
var jAsr = grpc.loadPackageDefinition(asrPkgDef).nvidia.riva.asr;
然後,定義 ASRPipe 類別以及先前呼叫的設定函式:
class ASRPipe {
setupASR() {
// the Riva ASR client
this.asrClient = new jAsr.RivaSpeechRecognition(process.env.RIVA_API_URL, grpc.credentials.createInsecure());
this.firstRequest = {
streaming_config: {
config: {
encoding: jAudio.AudioEncoding.LINEAR_PCM,
sample_rate_hertz: 16000,
language_code: ‘en-US’,
max_alternatives: 1,
enable_automatic_punctuation: true
},
interim_results: true
}
};
}
}
此時,可以建立 Riva ASR 用戶端,並定義一些配置參數,在開啟資料流時做為第一個要求,傳送至資料流。在相同的類別定義中指定 mainASR 函式,以設定實際的 ASR 資料流:
async mainASR(transcription_cb) {
this.recognizeStream = this.asrClient.streamingRecognize()
.on('data', function(data){
if (data.results == undefined || data.results[0] == undefined) {
return;
}
// transcription_cb is the result-handling callback
transcription_cb({
transcript: data.results[0].alternatives[0].transcript,
is_final: data.results[0].is_final
});
})
.on('error', (error) => {
console.log('Error via streamingRecognize callback');
console.log(error);
})
.on('end', () => {
console.log('StreamingRecognize end');
});
// First request to the stream is the configuration
this.recognizeStream.write(this.firstRequest);
}
streamingRecognize 函式具有非同步性質。當 Riva 有需要傳送的結果時,就會觸發資料事件,因此,請將這些結果重新封裝,並傳送至先前的回呼函式。
傳送 NER 要求
呼叫 Riva NER 服務比較簡單。與之前一樣載入 NLP API,然後針對需要處理的每一行文字,呼叫 ClassifyTokens 函式。每一個要求都會傳送文字以及需要使用的 Riva 部署模型。若有需要,則在稱為 computeSpans 的函式中進行一些後處理,然後遞交結果。
function getRivaNer(text) {
var entities;
req = { text: , model: {model_name: process.env.RIVA_NER_MODEL} };
return new Promise(function(resolve, reject) {
nlpClient.ClassifyTokens(req, function(err, resp_ner) {
if (err) {
reject(err);
} else {
entities = computeSpans(text, resp_ner.results[0].results);
resolve({ner: entities});
}
});
});
};
目前,已完成了呼叫 Riva 的 gRPC。您可以在用戶端擷取音訊、透過串流連線傳送至 Riva,以取得轉錄以及標記文字中的命名實體。當 Riva 傳回結果時,將會透過包含 transcript 事件的通訊端,將結果傳遞至使用者的網頁用戶端。現在,回到瀏覽器中處理這些結果,以完成迴路。
在瀏覽器中呈現結果
現在,包含註解的轉錄已回到網頁用戶端,請在瀏覽器中顯示。請記住,所有用戶端-伺服器通訊都是透過 Socket.IO 連線進行,因此請為包含結果的 transcript 事件設定聆聽器。
socket.on('transcript', function(result) {
document.getElementById('input_field').value = result.transcript;
if (result.is_final) {
// Erase input field
$('#input_field').val('');
showAnnotatedTranscript(username, result.annotations, result.transcript);
// Send the transcript to the peer to render
if (peerConn != undefined && callActive) {
peerConn.send({from: username, type: 'transcript', annotations: result.annotations, text: result.transcript});
}
}
});
input_field 元件在網頁 UI 中很方便,可以顯示出在您說話時即時更新的臨時轉錄。在整個應用程式中,都是使用相同的欄位傳送純文字要求。當轉錄標記為最終之後,會顯示於另一個方塊中,並會將轉錄複本傳送給通話中的對方,以便能看到對話的雙方。
呈現轉錄本身是標準 HTML 和 CSS。為了使生活更便利,請使用優質的 displaCy-ENT,根據文字標記命名實體。
微調醫學 NER 模型
Riva 是預設為提供可以處理地點、人員、組織、時間等實體的 NER 模型。對於許多應用而言非常有用,例如理解新聞內文和建構聊天機器人。之前,我們曾經討論對話式 AI 對遠距醫療應用程式的幫助。以下說明如何為 Riva 訓練 NER 模型,以標記醫學實體。
從零開始訓練模型通常需要很多時間。您可以使用現有的已訓練模型,並在自訂資料上進行微調,而無須從全新的模型開始。NVIDIA 遷移學習工具套件(TAO Toolkit)是以 Python 為基礎的人工智慧工具套件,專為縮短使用您的資料進行微調,以及自訂預先訓練模型需要的時間而設計。
由於醫學資料可能極度敏感,因此不一定能輕鬆地在線上找到資料。一個來自於 2010 i2b2/VA 挑戰賽優質的 NER 資料集,包含針對問題(例如疾病或症狀)、治療(包括藥物)和測試標記的去識別化醫師筆記。您可以申請存取該項做為醫學 NLP 社群使用之標準競爭基準的資料集。
NER 資料通常是以 IOB 標記的形式提供,文字中的各個權杖均標記為實體開始、實體內部(非第一個單字)或外部。在醫學文字方面,通常如下所示:
文字:
DISCHARGE DIAGNOSES : Coronary artery disease , status post coronary artery bypass graft .
標籤:
O O O B-problem I-problem I-problem O O O B-treatment I-treatment I-treatment I-treatment O
這是做為 TLT 輸入的資料。使用 TLT 訓練 NER 模型的詳盡指南,請參閱 TLT-Riva NER 集合中的訓練筆記。於此情形下,從經過預先訓練的語言模型檢查點 bert-base-uncased 開始,然後使用經過預處理的 i2b2 資料,調整 NER 任務。
訓練和部署自訂模型需要幾個步驟。從經過預先訓練的檢查點開始,使用資料在 TLT 中微調模型。再次使用 TLT,將模型匯出為 Riva 的最佳化形式。為 Riva 提供一些基本部署設定,建立一個繫結組態的中間形式。然後,部署該套件,以建立正在執行的 Riva 伺服器。若需要更多資訊,請參閱 NVIDIA Riva Speech Skills。

!tlt token_classification train \
-e $SPECS_DIR/train.yaml \ # Specification file
-g 1 \
-k $KEY \
-r $RESULTS_DIR/medical_ner \
data_dir={destination_mount}/data/i2b2 \
model.label_ids={destination_mount}/data/i2b2/label_ids.csv \
trainer.max_epochs=10
在完成之後,TLT 會將模型儲存在稱為 trained-model.tlt 的檔案中。下一步是將此模型匯出為Riva 可用於部署的 ejrvs 格式:
!tlt token_classification export \
-e $SPECS_DIR/export.yaml \ # Specification file
-g 1 \
-m $RESULTS_DIR/medical_ner/checkpoints/trained-model.tlt \
-k $KEY \
-r $RESULTS_DIR/medical_ner \
export_format=RIVA
現在,模型已匯出為 exported-model.ejrvs,可以在 Riva 中使用。
使用 Riva ServiceMaker Docker 映像,建構與部署新的模型。
docker pull nvcr.io/riva/riva-speech:1.0.0b1-rc5-servicemaker
docker run --gpus all -it --rm
-v $RESULTS_DIR/medical_ner:/servicemaker-dev
-v $RIVA_REPO_DIR:/data
--entrypoint="/bin/bash"
nvcr.io/ea-riva-stage/riva-service-maker:1.0.0b1-rc5
riva-build token_classification
--IOB=true
/data/med-ner.jmir
/servicemaker-dev/exported-model.riva
riva-deploy /data/med-ner.jmir /data/models -f
–IOB 旗標指示 Riva 將模型輸出解讀為具有 IOB 標記的 NER 模型,以簡化模型輸出。$RIVA_REPO_DIR 是從 Quick Start 指令碼執行 riva_init.sh 時建立之 Riva 儲存庫的位置。該儲存庫涵蓋所有已部署模型的模型子目錄,包括預設的一般領域 NER。在呼叫 riva-deploy 時,Riva 會將新的 NER 模型插入該位置。
擁有新的 NER 模型之後,即可在應用程式中進行醫學領域標記,並透過對話即時顯示。

部署至實際應用
Riva 是設計為具有高擴充性,且可以將使用 Riva 框架開發的應用程式,部署在雲端或內部的 Kubernetes 叢集中。Riva 提供了一個可用於開始的範例 Helm chart:
在叢集上安裝 Kubernetes、Helm 3.0,以及適用於 Kubernetes 的 NVIDIA GPU Operator。其次,從 NGC 下載 Riva人工智慧服務 Helm chart。
export NGC_API_KEY=<your_api_key> helm fetch https://helm.ngc.nvidia.com/ea-riva/charts/riva-api-0.1-ea.tgz --username='$oauthtoken' --password=<YOUR API KEY>
在將壓縮資料夾解壓縮之後,於 /Riva-api 下找出部署需要的檔案。
riva-api ├── Chart.yaml ├── templates │ ├── deployment.yaml │ ├── _helpers.tpl │ └── service.yaml └── values.yaml
Chart.yaml 檔案包含與 Helm 部署有關的資訊,例如名稱、版本等。想要變更部署配置時,請查看 values.yaml 檔案,並視需要變更配置:
- replicaCount:Riva 服務複本的數量。
- speechServices [asr | nlp | tts]:啟用語音服務的三個布林參數。
- ngcModelConfigs:可以從 NGC 下載的模型配置。
- service:可以在生產中部署的負載平衡服務。
從 values.yaml 檔案讀取值的 Kubernetes 部署檔案,是位於範本資料夾中。Kubernetes 叢集上的 Riva 範例部署執行下述操作:
- 找到 GPU 節點,並使用預先訓練模型提取 Riva Speech Docker 容器。
- 裝載包含模型目錄的 Docker 磁碟區。
- 提取、設定及執行 Triton 推論伺服器。
- 開啟傳入推論要求和傳出回應的連接埠。
- 設定 Prometheus 服務,以提取 GPU 和推論指標。
最後,想要部署 Riva 伺服器時,請執行以下命令:
helm install riva_server riva-api
或者,使用 –set 選項進行安裝而不修改 values.yaml 檔案。務必正確設定 NGC_API_KEY、ngcCredentials.email 和 model_key_string 值。在預設之情況下,model_key_string 選項是設為 tlt_encode。
helm install riva-api --set ngcCredentials.password=`echo -n $NGC_API_KEY | base64 -w0` --set ngcCredentials.email=your_email@your_domain.com --set modelRepoGenerator.modelDeployKey=`echo -n model_key_string | base64 -w0` > NAME: riva-api LAST DEPLOYED: Thu Jan 28 12:05:36 2021 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None
檢查紀錄,以查看是否已部署 Riva 伺服器,且無任何錯誤:
kubectl get pods kubectl logs
想要向 Riva 伺服器提出推論要求時,必須取得負載平衡器的 IP 位址:
kubectl get services
kubectl get services kubectl get services > NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE riva-api LoadBalancer 10.100.194.170 ac51c23e62d094aa68ac2adb98edb7eb-798330929.us-east-2.elb.amazonaws.com 8000:30034/TCP,8001:31749/TCP,8002:30708/TCP,50051:30513/TCP,60051:31739/TCP 2m19s kubernetes ClusterIP 10.100.0.1 <none> 443/TCP
RIVA_API_URL= <external-IP>
在理想的微服務部署架構中,Helm 部署應同時包含範例網頁應用程式。但是,本文是將 Node.js 應用程式留在叢集環境之外。在範例應用程式中,是使用上一個命令中的叢集 IP 位址,並大規模測試 Riva ASR 和 NLP 功能。
結論
針對使用案例自訂具有高效能和擴充性的對話式 AI 應用程式,是很困難的事。在本文章中,已探討了如何使用 NVIDIA Riva,輕鬆地為現有的應用程式增加音訊轉錄和命名實體辨識功能。我們也講解了如何使用遷移學習工具套件自訂應用程式,以及如何使用 Helm chart,大規模部署應用程式。您可以立即下載 Riva,以免費開始使用。