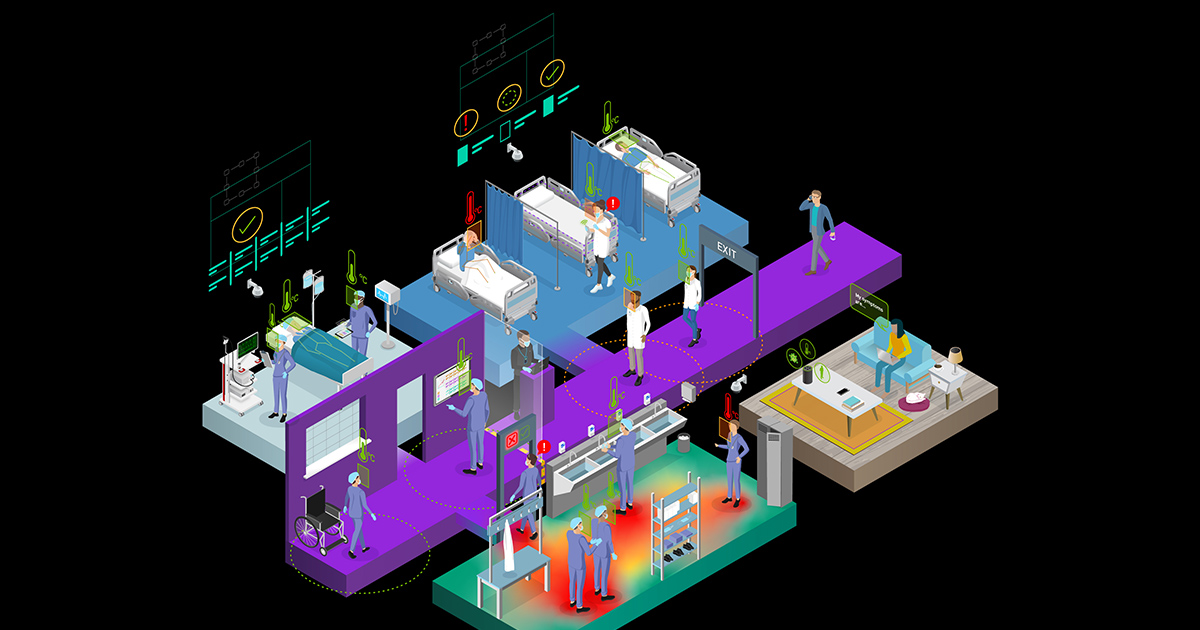
現在的醫院都在設法改造現有的數位基礎架構,以改善內部流程,提供更好的患者照護,並降低營運支出。如果醫院想要應對迅速成長的人口需求、醫學患者資料累積以及疫情,就必須經歷此類轉變。
目標包括將現有的基礎架構數位化、將工作流程效率最佳化、匯集大量的患者資料,以及創造出篩檢和診斷的新工具。醫院可以透過來自智慧感測器的資料饋送至以邊緣為基礎的系統,即時滿足患者和工作人員的需求。
智慧醫院生態系統的關鍵部分是獨立軟體供應商(ISV),他們為醫院建構和部署最先進的應用程式。ISV 資料科學家和開發人員需要能輕鬆存取軟體構件,包括兼具安全性與高效能的模型和容器。這些構件可賦予開發人員建立 AI 模型和基礎架構的起步優勢。
在建立應用程式之後,必須將其部署在大量的邊緣裝置上,以獲得即時的見解。但是,在邊緣裝置上部署、監控和管理軟體具有特殊的挑戰。DevOps 和 IT 管理者必須全面管理各個位置的所有實體裝置以及軟體部署。
在這一篇文章中,我們將示範如何使用來自 NVIDIA NGC 目錄的智慧醫院應用程式框架 NVIDIA Clara Guardian 建構應用程式,以及如何使用 NVIDIA Fleet Command 安全地將應用程式部署在邊緣。
利用 NGC 加快 AI 工作流程
NGC 目錄是為了加快 AI 工作流程而建立。它是雲端原生 GPU 最佳化 AI 與 HPC 應用程式和工具的中樞,可以加快存取效能最佳化容器的速度、透過預先訓練模型縮短解決時間,並提供產業專用的軟體開發套件,以建構端對端 AI 解決方案。此目錄包含各種應用及使用案例的資源,包含可用於電腦視覺、語音辨識、推薦系統等的各式各樣資源。
在醫療保健領域中,預先訓練模型涵蓋註解、分割、分類等關鍵功能。您可以將轉移學習應用在模型,並針對自己的資料進行重新訓練,以建立自訂模型。
NGC 目錄上的 AI 容器和模型經過調整、測試和最佳化,將可讓現有的 GPU 基礎架構發揮最大的效能。這些容器和模型是使用自動混合精度,讓您使用此功能時不需要變更程式碼或僅需要極少的變更。自動混合精度是使用 NVIDIA GPU 上的 Tensor 核心,可以大幅加快模型訓練速度。多 GPU 訓練是在所有使用 Horovod 和 NCCL 函式庫進行分散式訓練和高效率通訊之 NGC 模型上建置的標準功能。
NGC 上的 NVIDIA Clara Guardian
NVIDIA Clara Guardian 是在 NGC 目錄上容器化的框架之一。Clara Guardian 是屬於 NGC 目錄早期試用計畫的一部分,為現有的眾多醫療應用程式框架之一。主要元件包括用於電腦視覺和語音的醫療預先訓練模型、訓練工具、部署 SDK,以及 NVIDIA Fleet Command,這些都是讓 ISV 可以快速建構和部署解決方案,以供醫院使用。
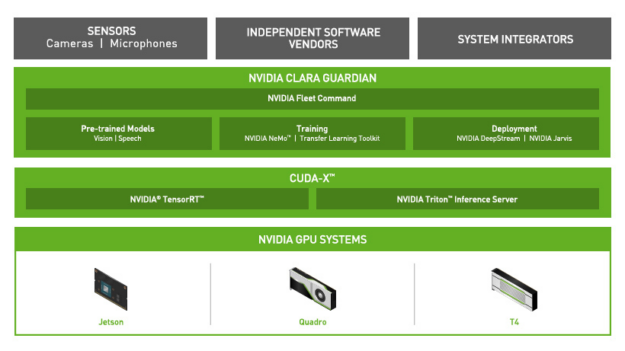
您可以輕鬆地將 AI 功能加入常見感測器中,監測人群,以確保安全社交距離、測量體溫、偵測是否缺少口罩等防護裝備,或與高風險患者遠端互動,讓醫療機構中的每一個人都能在安全的情況下瞭解資訊。應用程式和服務可以在 NVIDIA Jetson Nano、NVIDIA T4 伺服器等各種硬體上運行,讓您能安全地在任何位置部署,從邊緣到雲端。
NVIDIA Fleet Command
NVIDIA Fleet Command 是可以在數十個或多達數百萬個伺服器或邊緣裝置上,管理和擴充 AI 部署的混合雲端平台。Fleet Command 可以讓 IT 部門安全地遠端管理大量的已部署系統。管理員可以在短短數分鐘內,將 AI 導入網路化醫院,而無須花數週的時間規劃和執行部署計畫。管理員可以新增或刪除應用程式、以無線方式更新系統軟體,以及從單一控制面板監控分散在各處之裝置的狀態。
安全性是所有企業的需求。NGC 目錄中的代管應用程式會經過公共漏洞與暴露掃描、密碼編譯金鑰、私密金鑰以及中繼資料掃描,確保已準備好進行量產層級部署。在邊緣端,將對所有已處理資料進行靜態加密,並安全、可靠的啟動,防止 AI 執行階段遭到竄改。此外,由於系統採用內部部署處理近端感測器饋送,因此組織可以控制感測器資料的儲存位置。
Clara Guardian 實際應用
NVIDIA Inception 醫療 AI 新創公司 Whiteboard Coordinator 是使用 Clara Guardian,為西北紀念醫院(Northwestern Hospital)等頂尖醫院打造虛擬患者助理解決方案。患者安全一直很重要,而在 COVID-19 疫情期間更是至關重要。
減少身體接觸等措施是減少傳播,以及確保患者和醫護人員安全的關鍵。對話式 AI 有助於減少身體直接接觸,同時可以繼續提供高品質的照護。患者可以立即從 AI 虛擬助理獲得答案,而無須等待臨床工作人員提供服務。
建構應用程式
您已經瞭解 Clara Guardian 的實際應用情形,以下將說明如何建構應用程式。
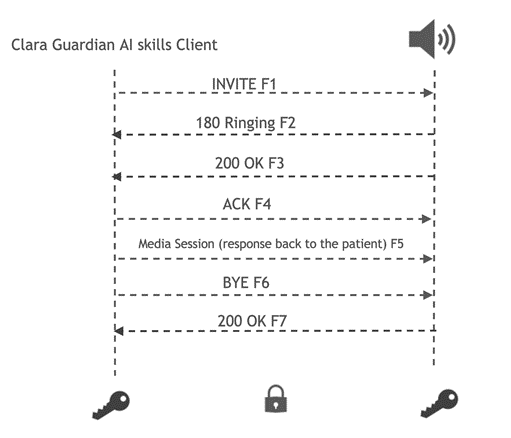
虛擬患者助理應用程式是屬於 Clara Guardian 用戶端應用程式,可接收患者的輸入查詢、擷取意圖和相關資訊,以解讀患者的詢問,並以自然的語音即時運算給予回應。患者可能提出任何問題,從對於日常排程的一般問題,到治療計畫或醫療程序等更多領域的相關問題。
Clara Guardian 用戶端應用程式是使用 gRPC 協定與 Clara Guardian SDK 互動。以此虛擬患者助理應用程式為例,該方法是針對自動語音辨識、自然語言理解,以及文字轉語音所定義的請求和回應。用戶端具有虛設程式,提供與伺服器相同的方法,並在同一個主控端上執行。Python 繫結用於和 Clara Guardian AI 服務互動。用戶端也可以使用 protobuf 檔案,以任何官方 gRPC 支援的語言與伺服器通訊。
Clara Guardian 自動語音辨識(automated speech recognition,ASR)技能,可以針對以 16 位元 LPCM 編碼的傳入、串流音訊、RTP 資料流進行即時英語轉錄。為了方便與病房中的各種麥克風整合,並適應不同的頻率響應、極性型態和近接效應,我們提供 RTP 連接器做為用戶端應用程式的一部分,將傳入的麥克風資料編碼成與 Clara Guardian ASR 相容的輸入。ASR 的核心代表了以 Jasper 模型為基礎的端對端語音辨識管道。
ASR 技能已針對低延遲進行最佳化,讓卷積層的整個子區塊,皆能以高準確度(在醫學資料集上,WER 大約為 2%)融合至單一 GPU 核心。您也可以依據此逐步指示,使用 NeMo 訓練自己的聲學模型。若想要使用 Clara Guardian 部署已訓練模型,則必須將編碼器和解碼器檢查點匯出至 ONNX。
Clara Guardian 自然語言理解(natural language understanding,NLU)服務是以 ASR 轉錄的文字做為輸入,並根據預先訓練的 BERT 模型擷取患者意圖和相關資訊,以進行聯合意圖分類和資訊填充。若想要使用自己的資料訓練此模型,請參閱發布在 GitHub 上的 nlp/intent_slot_classification 範例。
Clara Guardian 文字轉語音(text-to-speech,TTS)技能是以兩個神經網路模型為基礎:
- 經過修改的 Tacotron 2 模型,是以 Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions 論文為根據。
- 以流為基礎的神經網路模型,則是以 WaveGlow: A Flow-based Generative Network for Speech Synthesis 論文為根據。
NGC 目錄中的 Tacotron 2 和 WaveGlow 模型構成了文字轉語音工作流程,可以合成自然語音,而無須任何其他資訊,例如語音型態或節奏。Tacotron 2 模型是透過採用編碼器-解碼器架構的意圖分類器和資訊標記器,從輸入的 NLU 文字產生梅爾聲譜圖,而WaveGlow 是產生語音,以回應患者。
您可以依據 NeMo 文件,使用自己的資料訓練 Tacotron 2 和 WaveGlow。為了將回應傳回病房中的揚聲器,我們提供了 TLS 安全 Session Initiation Protocol(SIP)連接器。傳輸經過加密,可以防止將回應串流回患者時,發生竊聽、竄改和訊息偽造。
若想要建構應用程式,則必須使用 gRPC 編寫與 Clara Guardian AI 技能伺服器通訊的 Python 用戶端。用戶端轉錄傳入的 RTSP 流,並將串流回應傳送至 Clara Guardian AI 技能伺服器,是第一個處理步驟:
#import all the libraries
#setup the channel and the client
channel = grpc.insecure_channel(clara_guardian_server)
client = risr_srv.RivaSpeechRecognitionStub(channel)
...
#set the streaming config parameters
config = risr.RecognitionConfig(
encoding=clara_guardian_encodi
sample_rate_hertz=16000,
language_code="en-US",
max_alternatives=1,
enable_automatic_punctuation=True)
streaming_config = risr.StreamingRecognitionConfig(config_parameters)
mic_rtsp = open_stream(IP_of_device)
#send client requests to generate responses
...
mic_rtsp.close_stream()
在轉錄音訊之後,用戶端會傳送 NLP 技能伺服器要求,以偵測和確定患者查詢。例如,當患者詢問「我今天需要接受什麼療程?」時,資訊標記器將會擷取相關的語意實體,例如「day_of_week」。
intent {
class_name: "procedure_inquiry"
score: 0.9931640625
}
slots {
token: "today"
label {
class_name: "day_of_week"
score: 0.56298828125
}
}
domain_str: "healthcare"
domain {
class_name: "healthcare"
score: 0.9866989850997925
最後,將串流要求傳送至 TTS 串流技能伺服器,再將加密後的回應傳送至病房中的 IP 裝置:
responses = client.SynthesizeOnline(req)
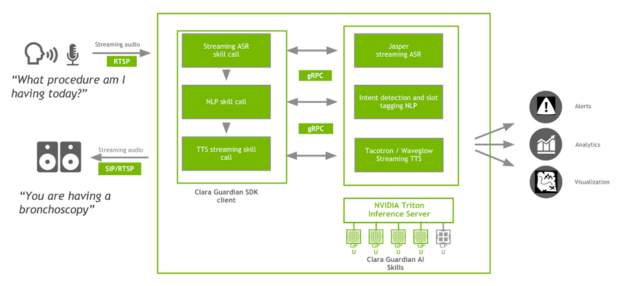
Clara Guardian AI 服務是透過 NVIDIA Triton 推論伺服器進行部署。Triton 推論伺服器是針對 NVIDIA GPU 最佳化的雲端推論解決方案,支援部署透過所有主要框架(包括 TensorRT、TensorFlow、PyTorch、ONNX Runtime 甚或自訂框架)訓練的 AI 模型,並提供使用 gRPC 端點的推論伺服器。當推論要求抵達使用 gRPC 的伺服器之後,即會傳遞至適當的模型調度器。模型調度器會針對推論要求進行批次處理,並將要求轉送至後端給對應的 ASR、NLP 或 TTS 模型。Triton 同時透過可觸發整個 ASR-NLP-TTS 模型管道執行的單一推論要求,提供整體支援。透過存取端點,可以取得數個指標,例如 GPU 利用率、延遲、推論要求數量、執行的推理次數。
部署應用程式
本節說明如何使用 NVIDIA Fleet Command 在搭載 NVIDIA T4,且經驗證可以執行各種 AI 工作負載,並經過安全性和遠端管理協定測試的 NTC-Ready for Edge 伺服器上,部署虛擬患者助理應用程式。
您也可以使用 Helm chart 部署應用程式。Helm 是 NVIDIA 推薦的 Kubernetes 套件管理器,可以讓您輕鬆地在 Kubernetes 上配置、部署和更新應用程式。提供給 Clara Guardian 的 Helm chart 是負責下載模型成品、建立模型儲存庫,以及啟動 ASR、NLU 和 TTS 服務。
若想要開始使用 NVIDIA Fleet Command,則必須存取 貴組織的 NGC Private Registry。NGC Private Registry 提供安全的雲端代管環境,讓開發人員可以從單一入口網站,自訂來自 NGC 的預先訓練模型、SDK 及 Helm chart、加密、簽署、分享和部署專有軟體。您可以透過使用者管理、自訂模型建立等其他功能,促進團隊之間的協作,並改善整體開發與部署流程。按一下此處,以深入瞭解如何設定 NGC Private Registry。
在設定 NGC Private Registry 之後,即可登入 NGC 帳戶。若想要從 Fleet Command 存取 NGC Private Registry 中的應用程式,請輸入 NGC API 金鑰進行驗證以達到同步。
將所有自訂內容上傳至 NGC Private Registry 之後,請新增需要部署應用程式的邊緣裝置位置。在此範例中,是在西北紀念醫院中安裝 T4 伺服器。
若想要使用 Clara Guardian Helm chart 新增部署在 Kubernetes 叢集上的虛擬患者助理應用程式,請選擇應用程式、新增應用程式。在表單中輸入應用程式的相關資訊,包括 Helm chart 的名稱。
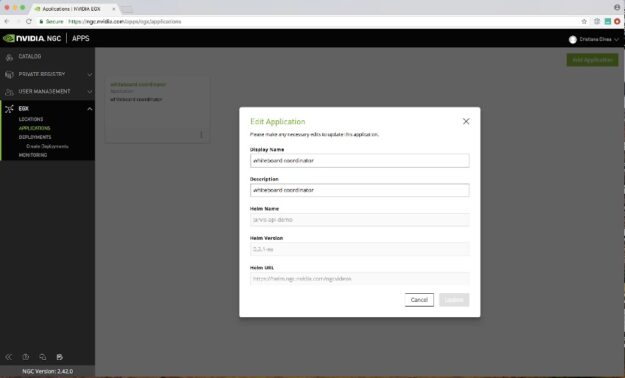
riva-api-demo Helm chart 的樹狀結構,如下所示:
├── Chart.yaml ├── templates │ ├── _helpers.tpl │ ├── artifactSecret.yaml │ ├── deployment.yaml │ ├── registrySecret.yaml │ └── service.yaml └── values.yaml
Helm chart 是範本,values.yaml 檔案則提供需要注入 chart 中的執行階段配置。將可視為類似用於自定義 chart 的發布參數。
/templates 目錄包含與 values.yaml 中的配置值以及自訂配置結合,並呈現在 Kubernetes 清單中的範本檔案。
最後一步是建立部署。Helm 部署使用了兩個 Kubernetes 秘密存取 NGC:一個用於 Docker 映像,另一個用於模型成品。在預設的情況下,兩者的名稱分別為 riva-ea-regcred 和 imagepullsecret。在 values.yaml 檔案中可以修改秘密的名稱。在新增 API 金鑰(使用 Fleet Command 位置選項)時,會將稱為 imagepullsecret 的 Kubernetes 秘密新增至位置中的所有 EGX 系統。

在選擇部署之後,即會將應用程式成功部署至醫院內部的伺服器。在部署應用程式時,將會看到狀態變成綠色(或使用中),即表示已部署成功。
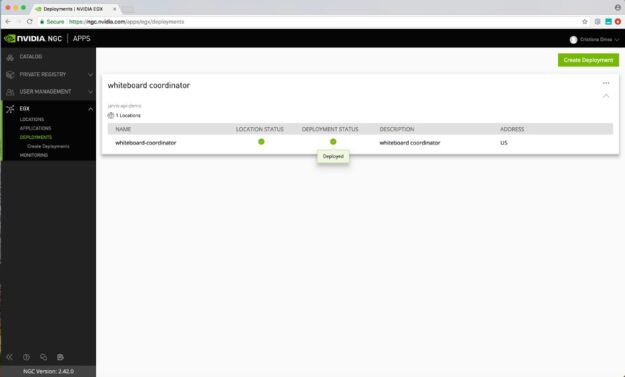
總結
使用 Clara Guardian 可以輕鬆建構虛擬患者助理應用程式,並可透過 NVIDIA Fleet Command 安全地部署、管理和擴充,以實現智慧醫院。參加 NGC 目錄提供的 Clara Guardian 試用,立即開始使用。
歡迎參加「利用 Clara 建置智慧醫院所需之 AI 應用」線上研討會,我們將分享想要導入人工智慧用、成為智慧醫院會需要那些技術與平台支援。