NVIDIA Ampere GPU 架構導入了第三代 Tensor 核心,以新的 TensorFloat32(TF32)模式加快 FP32 卷積和矩陣乘法。TF32 模式是在 Ampere GPU 架構上使用 32 位元變數進行人工智慧訓練的預設選項。不需要變更任何模型指令碼,就可以將 Tensor 核心加速帶入單精度深度學習工作負載。使用原生 16 位元格式(FP16/BF16)進行混合精度訓練仍是最快的選項,在模型指令碼中只需要幾行程式碼。表 1 所示為 A100 Tensor 核心與 FP32 CUDA 核心之傳輸量的比較。同樣值得一提的是,在單精度訓練方面,A100 提供的傳輸量較上一代訓練 GPU V100 高出 10 倍。
| FP32 | TF32 | FP16 / BF16 |
| 1 倍 | 8 倍 | 16 倍 |
內部
TF32 是一個新的運算模式,新增於 Ampere 世代 GPU 架構中的 Tensor 核心。點積運算構成矩陣乘法和卷積的基礎,將 FP32 的輸入內容進位至 TF32,在無精度損失的情況下計算乘積,然後將這些乘積累加成 FP32 輸出(圖 1)。
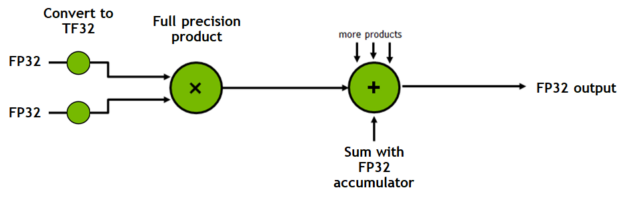
TF32 僅以 Tensor 核心運算模式的形式公開,而非類型。記憶體中的所有儲存體及其他運算完全維持於 FP32,僅有卷積和矩陣乘法,在乘法之前將其輸入轉換成 TF32。相反的,16 位元類型提供儲存體、各種數學運算子等等。
數值
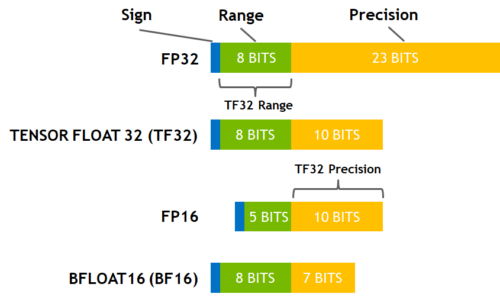
圖 2 所示為各種精度選項。Ampere 世代 GPU 的 TF32 模式是採用 8 個指數位元、10 個尾數位元,以及 1 個符號位元。因此其涵蓋的數值範圍與 FP32 相同。TF32 也維持比 BF16 高的精度以及保持與 FP16 相同的數量。TF32 與 FP32 的唯一差異仍是精度,且經過大量研究證實,對於人工智慧工作負載具有充足的餘裕。
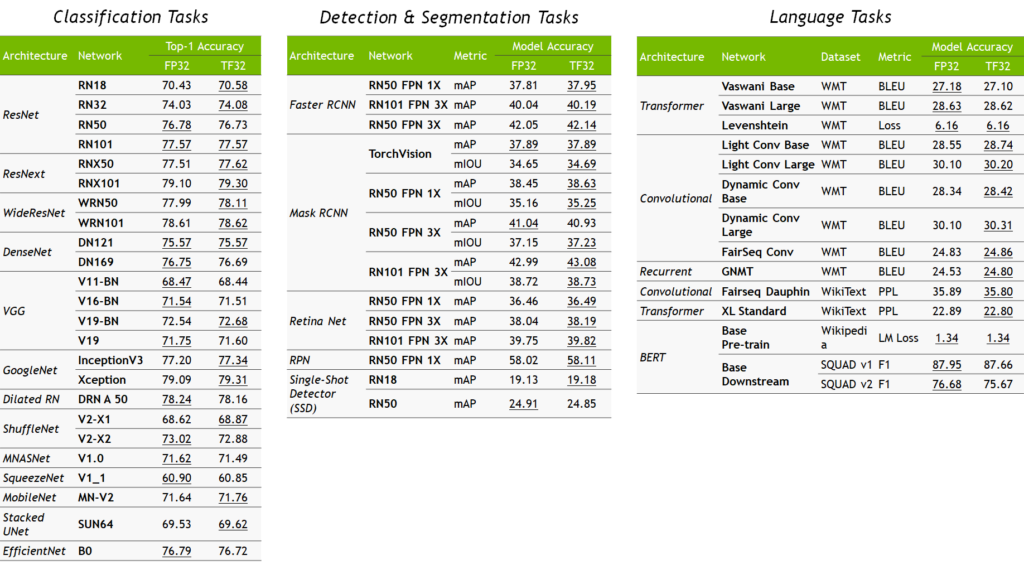
我們透過 TF32 模式在廣泛的人工智慧網絡上驗證單精度訓練,涵蓋電腦視覺、自然語言處理、推薦系統等各種應用。所有深度學習工作負載都符合 FP32 準確度、損失值和訓練行為,而未變更超參數或訓練指令碼。圖 3 所示為訓練網路範例。所有工作負載都是使用相同的超參數,以 FP32 和 TF32 模式進行訓練,且所有的精準度差都在各個網路之執行間的變化(不同的隨機種子等)範圍內。圖 4 所示為在訓練網路案例上之特定模型的訓練曲線。
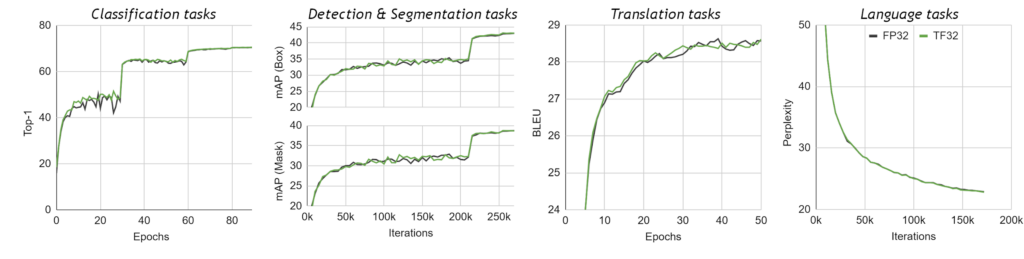
訓練加速
如前所述,TF32 數學模式是 Ampere 世代 GPU 上的單精度深度學習訓練預設選項,準確度與 FP32 訓練相同,不需要變更訓練指令碼的超參數,並提供比 Volta GPU 上之單精度快 10 倍,且立即可用的「張量數學」(卷積和矩陣乘法)。但是,實際觀察到的網路加速效果不同,因為所有的記憶體存取仍保持為 FP32,且 TF32 模式不會影響非卷積或矩陣乘法的層次。
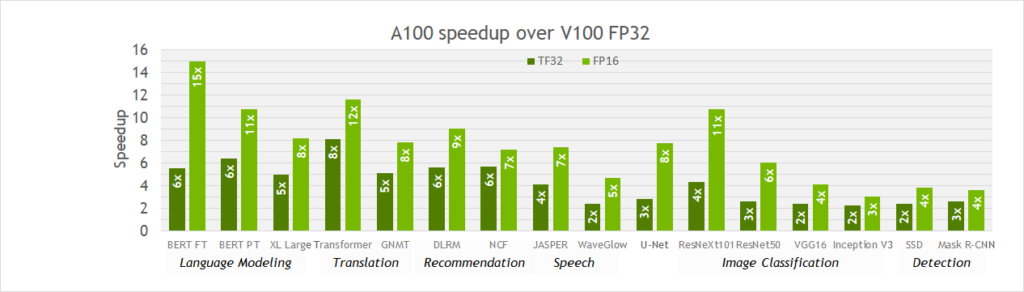
如圖 5 所示,從 V100 移轉至 A100 時,在各種工作負載之單精度訓練中,實際觀察到 2-6 倍的加速。此外,透過 FP16 切換至混合精度,可以進一步提供大約 2 倍的加速,因為 16 位元 Tensor 核心比 TF32 模式快 2 倍,且僅存取一半的位元組,減少了記憶體流量。因此,對於原在 Volta 或其他處理器上以 FP32 訓練的模型而言,TF32 是很好的起點,而混合精度訓練則是在 A100 上,可將訓練速度最大化的選項。
針對研究人員
在本節中,總結了使用 TF32 Tensor 核心加快深度學習工作負載需要瞭解的一切。
深度學習框架
從 NGC 提供的 20.06 版開始,當針對 TensorFlow、PyTorch 和 MXNet 使用 NVIDIA 最佳化的深度學習框架容器時,TF32 是在 A100 上的人工智慧預設模式。從 PyTorch 1.7、TensorFlow 2.4 以及 MXNet 1.8 版本開始,在框架儲存庫中針對 A100 會預設啟用 TF32。深度學習研究人員可以使用之前列出的框架儲存庫和容器,透過 TF32 Tensor 核心的效益訓練單精度模型。
運算
TF32 模式可以加快單精度卷積和矩陣乘法層,包括線性和全連接層、遞歸單元以及注意力區塊。TF32 無法加快在非 FP32 張量上運算的層,例如 16 位元、FP64 或整數精度。TF32 也不適用於非卷積或矩陣乘法運算(例如批次正規化),以及最佳化器或求解器運算的層。在使用 TF32 訓練時,張量儲存體不變。一切仍維持於 FP32,或指令碼中指定的任何格式。
針對開發人員
在整體 NVIDIA 函式庫中,可以看到 A100 上所有精度的 Tensor 核心加速,包括 FP16、BF16 和 TF32。其中包括 cuDNN 中的卷積、cuBLAS 中的矩陣乘法、cuSOLVER 中的因式分解和密集線性求解器,以及 cuTENSOR 中的張量收縮。在本文中,探討了於 NVIDIA 函式庫中啟用 Tensor 核心的各項注意事項。
cuDNN
cuDNN 是主要用於卷積運算的深度神經網路函式庫。cuDNN 中的卷積層具有描述執行之運算的描述元,例如數學類型。從 8.0 版開始,在使用預設數學模式 CUDNN_DEFAULT_MATH 或將數學類型指定為 CUDNN_TENSOR_OP_MATH 時,將使用 TF32 Tensor 核心執行卷積運算。在運算 32 位元資料時,如果適用的話,函式庫會在內部選擇 TF32 卷積核心。對於 Volta 和舊版 cuDNN 而言,預設選項仍是 FP32。
cuBLAS
cuBLAS 是用於執行基本的密集線性代數運算,例如深度神經網路中的矩陣乘法。cuBLAS 針對 CUBLAS_DEFAULT_MATH 仍預設為 FP32 運算,因為在 HPC 應用程式中傳統使用 cuBLAS,需要較高精度。
從 11.0 版開始,cuBLAS 透過 cublasSetMathMode 函式支援 TF32 Tensor 核心運算,方式是針對舊版 BLAS API,將數學模式設為 CUBLAS_TF32_TENSOR_OP_MATH,並針對 cublasGemmEx 和 cublasLtMatmul API,將運算類型設為 CUBLAS_COMPUTE_32F_FAST_TF32。在選擇這些選項之後,於運算 32 位元資料時,如果適用的話,函式庫會在內部選擇 TF32 核心。
NVIDIA 最佳化深度學習框架是使用 cublasSetMathMode,將 cuBLAS 控點上的全域數學模式狀態設為 CUBLAS_TF32_TENSOR_OP_MATH,以獲得 TF32 的效益。但是,深度學習中仍有一些線性代數運算,所以 cuBLAS 需要完整的 FP32 精度,以保留用於訓練或推論的數值。框架會預防此類運算,例如執行求解器運算,並將數學模式設定為回到使用 FP32 核心的 CUBLAS_DEFAULT_MATH。
cuSOLVER
cuSOLVER 主要是使用於求解器運算,例如因式分解和密集線性求解器。某些深度學習框架是使用 CUDA 工具套件中的 cuSOLVER。由於一律使用 API 呼叫定義的精度,因此無須變更預設的數學運算。
cuTENSOR
cuTENSOR 主要是使用於張量基元,例如收縮、縮減和元素運算。精度一律由 API 呼叫定義。從 1.1.0 版開始,cuTENSOR 是透過運算類型 CUTENSOR_COMPUTE_TF32 支援 TF32 Tensor 核心運算。
進位選項
BF16 在 cuBLAS 11.0 中是導入為 Tensor 核心數學模式,在 CUDA 11.0 中是導入為數值類型。深度學習框架和 AMP 即將可支援 BF16。在為混合精度訓練設計自訂層時,通常會在 16 位元與 FP32 格式之間進行轉換。建議使用類型轉換或內在函式,如以下範例所示。必須包含對應的標頭檔案 cuda_fp16.h 和 cuda_bf16.h。
half a = (half)(1.5f);
half b = (half)(1.0f);
half c = a + b;
#include <cuda_bf16.h>
nv_bfloat16 a = (nv_bfloat16)(1.5f);
nv_bfloat16 b = (nv_bfloat16)(1.5f);
nv_bfloat16 c = a + b;
範例:將兩個 FP32 值轉換成 16 位元(FP16 或 BF16),然後與 16 位元運算相加,並將結果儲存在 16 位元暫存器中的範例 CUDA 程式碼。
全域平台控制
A100 導入全域平台控制,以允許變更 AI 訓練的預設數學行為。全域環境變數 NVIDIA_TF32_OVERRIDE 可用於在系統層級切換 TF32 模式,進而覆蓋函式庫或框架中的程式設定,如表 2。
| NVIDIA_TF32_OVERRIDE=0 | 未設定 |
| 停用所有的 TF32 核心,以使用 FP32 核心 | 預設為函式庫和框架設定 |
全域變數是設計為訓練出錯時的除錯工具。它可以讓您快速排除與 TF32 函式庫有關的任何問題,並專注於訓練指令碼中的其他問題。
在啟動應用程式之前,必須先設定 NVIDIA_TF32_OVERRIDE,因為未指定啟動應用程式後之任何變更的影響。此變數僅會影響 FP32 運算的模式。不會影響使用 FP64 或任一 16 位元格式的運算,並會繼續使用對應的類型。
結論
本文簡要介紹了 NVIDIA Ampere GPU 架構,為人工智慧訓練提供的各種精度和 Tensor 核心功能。TensorFloat32 將 Tensor 核心的效能帶入單精度工作負載,而使用原生 16 位元格式(FP16/BF16)的混合精度,則仍是訓練深度神經網路的最快選項。針對 A100 GPU 最佳化的最新深度學習框架,已提供了所有選項。欲深入瞭解使用 Tensor 核心訓練神經網路的各種可能性,請參閱以下線上講座: