Apache Spark 持續致力於 Apache Hadoop 在 15 年前開始的巨量資料分析工作,現在已成為大規模分散式資料處理的主要框架。如今,在 16,000 多家企業和組織中,有數十萬名資料工程師和科學家使用 Spark。
Spark 取代 Hadoop 的原因之一,是因為它可以將資料處理速度平均加快大約 100 倍。這些能力是由250 多家公司的 1,000 多位貢獻者,在開放社群中創造。Databricks 創辦人開始進行此項工作時,僅在他們的平台上,每天就要啟動超過一百萬個虛擬機器分析資料。
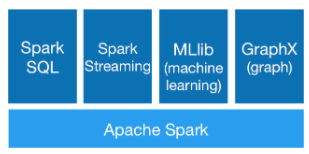
Spark 具有用於 SQL、串流處理、機器學習和圖形處理的高階運算子及函式庫,可以讓開發人員使用互動式殼層、notebook 或封裝應用程式,輕鬆使用 Scala、Python、R 或 SQL 建構平行應用程式。Spark 是使用函式程式設計模型和關聯查詢引擎 Catalyst ,支援批次處理和互動式分析。Spark 可以將工作轉換成查詢計畫,並在叢集中的各個節點調度查詢計畫中的操作。
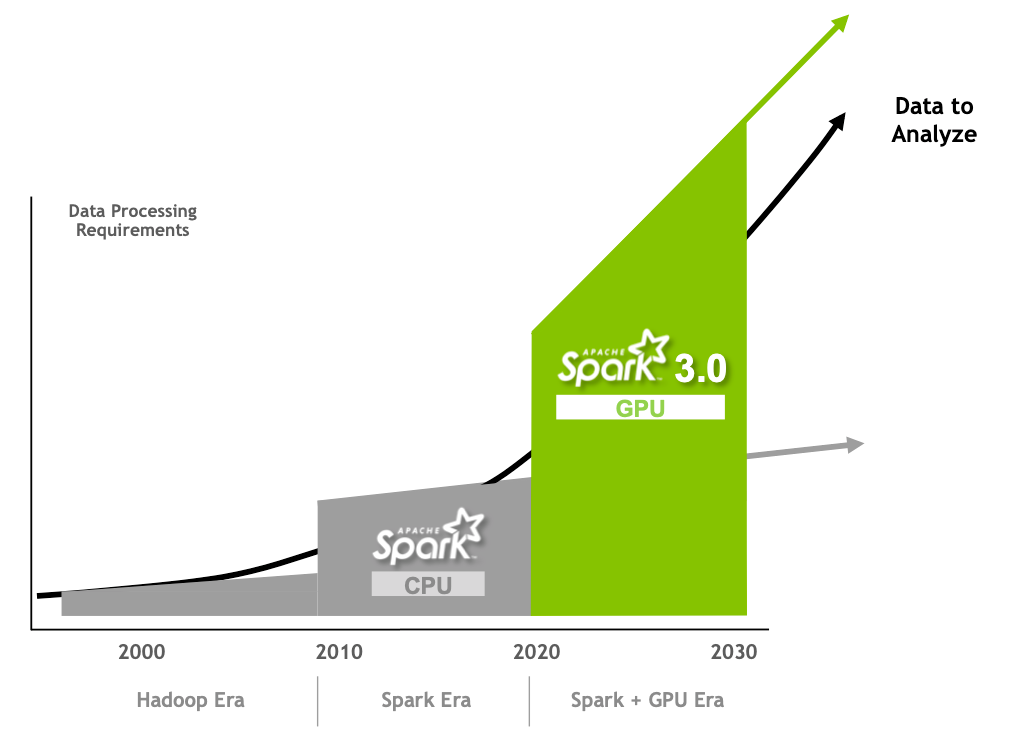
Spark 的每一個版本都會進行改進,以簡化程式設計及加快執行速度。Apache Spark 3.0 延續此趨勢,透過創新及本文探討的 NVIDIA GPU 加速改進 Spark SQL 效能。
適用於 Spark SQL 的 Spark 3.0 最佳化
Apache Spark 使用 SQL 查詢執行引擎,實現批次和串流資料的高效能。該引擎是以大規模平行處理(massively parallel processing,MPP)技術的構想為基礎,由最先進的 DAG 排程器、查詢最佳化工具和實體執行引擎組成。大多數 Spark 應用程式都是透過查詢執行引擎進行操作,因此,Apache Spark 社群已設法進一步提升其效能。根據 TPC-DS 基準測試顯示,自適應查詢執行、動態分割區修剪及其他最佳化,已使 Spark 3.0 的執行速度比 Spark 2.4 快大約 2 倍。
Spark 3.0 適應性查詢執行
Spark 2.2 將以成本為基礎的最佳化,加入以規則為基礎之現有的查詢最佳化工具中。現在 Spark 3.0 已具有執行階段適應性查詢執行(adaptive query execution,AQE)。透過 AQE,運用從已完成查詢計畫階段取得的執行階段統計資料,重新將其餘查詢階段的執行計畫最佳化。根據 Databricks 基準測試顯示,使用 AQE 時的加速效果提升了 1.1 倍到 8 倍。
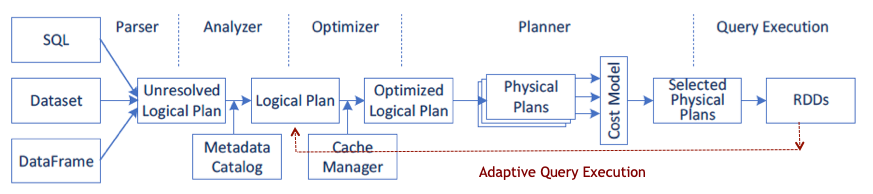
Spark 3.0 AQE 最佳化功能,包括:
- 動態合併資料傳輸(shuffle)分割區:AQE 可以查看 shuffle 檔案統計資料,將相鄰的小分割區合併成較大的分割區,以減少查詢聚合的任務數量。
- 動態切換聯結策略:AQE 可以根據聯結關係大小,在執行階段將聯結策略最佳化。例如將排序合併聯結轉換成廣播雜湊聯結,如果聯結的一側小到可以置入記憶體時,執行的效能更好。
- 以動態方式最佳化扭曲聯結:AQE可以使用執行階段統計資料,偵測排序合併聯結分割區大小中的資料扭曲,並將扭曲分割區分成較小的子分割區。
Spark 3.0 動態分割區修剪
Spark 2.x 靜態分割區修剪是以允許 Spark 僅讀取目錄和檔案之子集,以查詢符合分割區篩選條件的的方式提高效能。Spark 3.0 將此資料修剪技術引入與資料倉儲查詢類似之查詢的執行階段時,此類查詢會將已分割事實表與維度表中的篩選值聯結。減少讀取和處理的資料量,可以大幅節省時間。
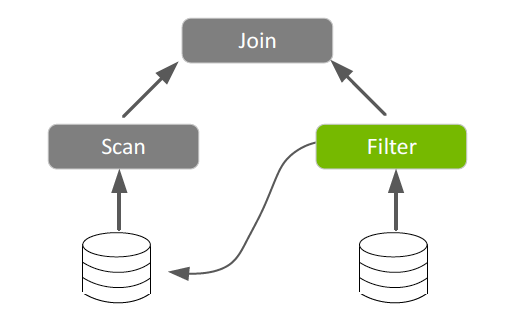
Spark 3.0 GPU 加速
GPU 因為每 FLOP(效能)價格極低而廣受採用。它們是透過加快多核心伺服器的速度以進行平行處理,解決目前的運算效能瓶頸。
一個 CPU 是由數個核心組成,適用於循序式序列處理。GPU 的大規模平行架構是由數千個更小、更有效率的核心組成,可以同時處理多個任務。相較於僅包含 CPU 的配置,GPU 能以更快的速度處理資料。GPU 在過去幾年內,一直負責促進深度學習和機器學習模型訓練的發展。但是,資料科學家卻將 80% 的時間使用在資料預處理上。
雖然 Spark 是以分割區的形式,將運算分散在節點之間,卻都在 CPU 核心上執行分割區中的運算。Spark 透過加入記憶體內資料處理,緩解了 Hadoop 的 I/O 問題,但是,現在面臨的瓶頸已從 I/O 轉移到越來越多的應用程式運算方面。在出現 GPU 加速運算之後,已可避免出現此類效能瓶頸。
為了能滿足與超越現代的資料處理要求,NVIDIA 與 Apache Spark 社群協作,透過發布 Spark 3.0 和用於 Apache Spark 的新開源 RAPIDS 加速器,。若需要更多資訊,請參閱 Google Cloud and NVIDIA’s enhanced partnership accelerates computing workloads。
Spark 的 GPU 加速具有許多好處:
- 更快完成資料處理、查詢和模型訓練,以縮短取得結果的時間。
- Spark 和機器學習/深度學習框架可使用相同的 GPU 加速基礎架構,不需要個別的叢集,且能讓整個工作流程都獲得 GPU 加速。
- 需要的伺服器變少,可以降低基礎架構的成本。
用於 Apache Spark 的 RAPIDS 加速器
RAPIDS 是由開放原始碼軟體函式庫和 API 組成的套件,可以完全在 GPU 上執行端對端資料科學和分析工作流程,以實現大幅加速,尤其是大型資料集。是以 NVIDIA CUDA 和 UCX 為基礎,可以在不需要變更程式碼的情況下,進行 GPU 加速 SQL 和 DataFrame 操作以及 Spark Shuffle。
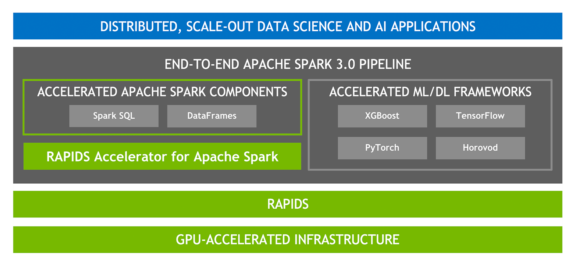
加速 SQL/DataFrame
Spark 3.0 支援 SQL 最佳化工具外掛程式,以使用欄式批次,而非資料列處理資料。欄式資料適用於 GPU,在RAPIDS 加速器中插入此功能,可以加快 SQL 和 DataFrame 運算子。透過 RAPIDS 加速器,修改Catalyst 查詢最佳化工具,以找出查詢計畫中可以利用 RAPIDS API 加速的 operator,主要是一對一對應,並在執行查詢計畫時,於 Spark 叢集中的 GPU 上調度這些 operator。
加速 shuffle
在根據階段之間的現有 DataFrame 建立新的 DataFrame 時,必須在分割區之間按照值排序、分類或合併資料的 Spark 操作移動資料,此過程稱為 shuffle,包含磁碟 I/O、資料序列化和網路 I/O。新的 RAPIDS 加速器 shuffle 建置是利用 UCX,將 GPU 資料傳輸最佳化,以盡可能將資料保留在 GPU 上。它會充分利用可用的硬體資源,尋找在節點之間移動資料的最快路徑,包括繞過 CPU 在 GPU 對 GPU 記憶體節點內和節點之間進行傳輸。
加速器感知 Scheduling
現在 GPU 已成為 Apache Spark 3.0 中的可調度資源,能進一步統一 Spark 上的 DL 和資料處理。這讓 Spark 可以調度具有指定數量 GPU 的執行程式,且您可以指定每項任務需要多少 GPU。Spark 將這些資源要求傳達給基礎叢集管理器:Kubernetes、YARN 或 Standalone 模式。您也可以配置可偵測叢集管理器分配之 GPU 的探索指令碼。以大幅簡化執行需要 GPU 的機器學習應用程式,因為過去必須解決 Spark 應用程式中缺少 GPU 調度的問題。
加速 XGBoost
XGBoost 是可擴充、分散式的梯度提升決策樹(gradient-boosted decision tree,GBDT)機系學習函式庫。
XGBoost 提供的平行樹提升,是處理迴歸、分類和排序問題的主要機系學習函式庫。RAPIDS 團隊與 Distributed Machine Learning Common (DMLC) XGBoost 組織密切合作,現在 XGBoost 已包括流暢的拖曳式 GPU 加速。
同時 Spark 3.0 XGBoost 已經與 RAPIDS 加速器整合,可透過下列功能改善效能、準確性和成本:
- Spark SQL/DataFrame 操作的 GPU 加速
- XGBoost 訓練時間的 GPU 加速
透過記憶體內最佳化儲存功能,有效率地利用 GPU 記憶體
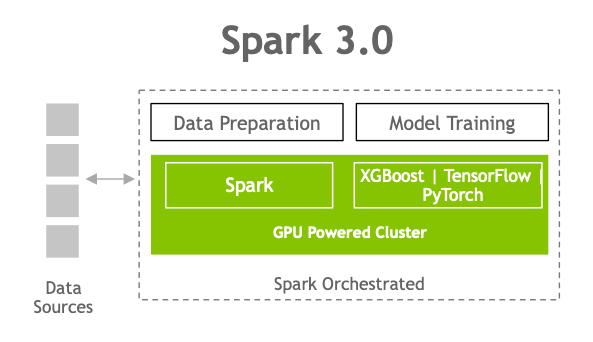
端對端機器學習加速的實際範例
Adobe、Verizon Media 和 Uber 在 GTC 2020 上,分別談論如何使用結合 GPU 的 Spark 3.0 預覽版,加快和擴充機器學習巨量資料預處理、訓練以及調整工作流程。
Adobe
Adobe 與 NVIDIA 建立策略性 AI 合作夥伴關係,是最早在 Databricks 上執行 Spark 3.0 預覽版的公司之一。在 NVIDIA GTC 大會上,Adobe Intelligent Services 提供了以 GPU 為基礎之 Spark 3.0 和 XGBoost 智慧電子郵件解決方案的評估結果,以最佳化行銷訊息的傳遞。在初始測試中,Adobe 將效能提升 7 倍,節省了 90% 的成本。
Spark 3.0 的效能提升,讓科學家可以使用更大的資料集訓練模型,更頻繁地重新訓練模型,以提高模型的準確性。因此,每一天都可以處理數 TB 的新資料,對於支援線上推薦系統或分析新研究資料的資料科學家而言非常重要。此外在加快處理速度之後,可以減少提供結果需要的硬體資源,進而大幅節省成本。
Adobe 機器學習資深總監 William Yan 在回答這些進步的相關問題時表示:「相較於在 CPU 上執行 Spark,NVIDIA 加速 Spark 3.0 的效能明顯更快。這些顛覆性的 GPU 效能提升,已為加強全套 Adobe Experience Cloud 應用程式之 AI 驅動功能,開創出全新的可能性。」
Verizon Media
為了預測數千萬名訂閱者的客戶流失率,Verizon Media 在以 GPU 為基礎的叢集上建立分散式 Spark 機器學習工作流程,以進行 XGBoost 模型訓練和超參數調整。Verizon Media 將效能提升至以 CPU 為基礎之 XGBoost 解決方案的 3 倍,加強進行超參數搜尋的能力,以便能找出最佳的超參數,進而獲得最佳化模型和最高的準確性。若需要更多資訊,請參閱 GTC 2020: Democratized M pipelines and Spark Rapids based-hyperparameter tuning。
Uber
Uber 將深度學習應用在整個事業中,從自動駕駛研究,到旅程預測和詐騙預防。Uber 開發出適用於 TensorFlow、Keras、PyTorch 和 Apache MXNet 的分散式深度學習訓練框架 Horovod,利用 GPU 和資料平行方法進行分散式訓練,更輕鬆地加快深度學習專案。
Horovod 已可支援 Spark 3.0 與 GPU scheduling,以及新的 KerasEstimator 類別,該類別將 Spark 估計器與 Spark 機器學習工作流程搭配使用,進一步與 Spark 整合及確保易用性。因此可以直接在 Spark DataFrame 上訓練 TensorFlow 和 PyTorch 模型,並利用 Horovod 的能力平行擴充至數百個 GPU,而不需要使用任何專用程式碼進行分散式訓練。生產 ETL 工作可透過 Apache Spark 3.0 中新的加速器感知調度和欄式處理 API,將資料傳遞給同一個工作流程中,在 GPU 上執行分散式深度學習訓練的 Horovod。
深入瞭解
- 欲深入瞭解新的 Spark 3.0 功能,請參閱 Spark 3.0 版本資訊。
- 若需要用於 Apache Spark 的 RAPIDS 加速器和入門指南,請參閱 spark-rapids GitHub 儲存庫。
- Databricks 最近宣布推出 Spark 3.0.0 做為 Databricks Runtime 7.0 的一部分,以及推出具有預先配置 GPU 加速的 Spark 3.0.0 做為 Databricks Runtime 7.0 for Machine Learning 的一部分,後者可在 Microsoft Azure 和 AWS 上取得。
- Google Cloud 最近宣布在 Dataproc 映像版0 上提供 Spark 3.0 預覽版。
- 若想要觀看 CPU 叢集與 Databricks 平台上之 GPU 叢集效能的並排比較,請觀看 。
欲深入瞭解如何利用 RAPIDS 和 GPU 加快 Apache Spark 3.0,請觀看 GTC 2020 Spark 會議。